knitr::opts_chunk$set(echo = TRUE, message = TRUE, warning = TRUE, fig.align = "center")
library(tidyverse)
library(mosaic) # Our go-to package
library(infer) # An alternative package for inference using tidy data
library(broom) # Clean test results in tibble form
library(skimr) # data inspection
library(resampledata) # Datasets from Chihara and Hesterberg's book
library(openintro) # datasets
library(gt) # for tablesInference for Two Independent Means
flowchart TD
A[Inference for Independent Means] -->|Check Assumptions| B[Normality: Shapiro-Wilk Test shapiro.test\n Variances: Fisher F-test var.test]
B --> C{OK?}
C -->|Yes, both\n Parametric| D[t.test]
D <-->F[Linear Model\n Method]
C -->|Yes, but not variance\n Parametric| W[t.test with\n Welch Correction]
W<-->F
C -->|No\n Non-Parametric| E[wilcox.test]
E <--> G[Linear Model\n with\n Signed-Ranks]
C -->|No\n Non-Parametric| P[Bootstrap\n or\n Permutation]
P <--> Q[Linear Model\n with Signed-Rank\n with Permutation]
Research Question
TBD
A.
Statistical tests for means usually require a couple of checks1 2:
- Are the data normally distributed?
- Are the data variances similar?:
Let us also complete a check for normality: the shapiro.wilk test checks whether a Quant variable is from a normal distribution; the NULL hypothesis is that the data are from a normal distribution.
B.
Conditions:
- The two variables are not normally distributed.
- The two variances are also significantly different.
Type this in your console:
help(yrbss)Type help(wilcox.test) in your Console.
Every two years, the Centers for Disease Control and Prevention in the USA conduct the Youth Risk Behavior Surveillance System (YRBSS) survey, where it takes data from highschoolers (9th through 12th grade), to analyze health patterns. We will work with a selected group of variables from a random sample of observations during one of the years the YRBSS was conducted.
data(yrbss)
yrbss
yrbss_inspect <- inspect(yrbss)
yrbss_inspect$categorical
yrbss_inspect$quantitativeage <int> | gender <chr> | grade <chr> | hispanic <chr> | race <chr> | height <dbl> | weight <dbl> | helmet_12m <chr> | text_while_driving_30d <chr> | physically_active_7d <int> | |
|---|---|---|---|---|---|---|---|---|---|---|
| 14 | female | 9 | not | Black or African American | NA | NA | never | 0 | 4 | |
| 14 | female | 9 | not | Black or African American | NA | NA | never | NA | 2 | |
| 15 | female | 9 | hispanic | Native Hawaiian or Other Pacific Islander | 1.73 | 84.37 | never | 30 | 7 | |
| 15 | female | 9 | not | Black or African American | 1.60 | 55.79 | never | 0 | 0 | |
| 15 | female | 9 | not | Black or African American | 1.50 | 46.72 | did not ride | did not drive | 2 | |
| 15 | female | 9 | not | Black or African American | 1.57 | 67.13 | did not ride | did not drive | 1 | |
| 15 | female | 9 | not | Black or African American | 1.65 | 131.54 | did not ride | NA | 4 | |
| 14 | male | 9 | not | Black or African American | 1.88 | 71.22 | never | NA | 4 | |
| 15 | male | 9 | not | Black or African American | 1.75 | 63.50 | never | NA | 5 | |
| 15 | male | 10 | not | Black or African American | 1.37 | 97.07 | did not ride | NA | 0 |
name <chr> | class <chr> | levels <int> | n <int> | missing <int> | distribution <chr> |
|---|---|---|---|---|---|
| gender | character | 2 | 13571 | 12 | male (51.2%), female (48.8%) |
| grade | character | 5 | 13504 | 79 | 9 (26.6%), 12 (26.3%), 11 (23.6%) ... |
| hispanic | character | 2 | 13352 | 231 | not (74.4%), hispanic (25.6%) |
| race | character | 5 | 10778 | 2805 | White (59.5%) ... |
| helmet_12m | character | 6 | 13272 | 311 | never (52.6%), did not ride (34.3%) ... |
| text_while_driving_30d | character | 8 | 12665 | 918 | 0 (37.8%), did not drive (36.7%) ... |
| hours_tv_per_school_day | character | 7 | 13245 | 338 | 2 (20.4%), <1 (16.4%), 3 (16.1%) ... |
| school_night_hours_sleep | character | 7 | 12335 | 1248 | 7 (28.1%), 8 (21.8%), 6 (21.5%) ... |
name <chr> | class <chr> | min <dbl> | Q1 <dbl> | median <dbl> | Q3 <dbl> | max <dbl> | mean <dbl> | sd <dbl> | ||
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | age | integer | 12.00 | 15.00 | 16.00 | 17.00 | 18.00 | 16.157041 | 1.2637373 | |
| 2 | height | numeric | 1.27 | 1.60 | 1.68 | 1.78 | 2.11 | 1.691241 | 0.1046973 | |
| 3 | weight | numeric | 29.94 | 56.25 | 64.41 | 76.20 | 180.99 | 67.906503 | 16.8982128 | |
| 4 | physically_active_7d | integer | 0.00 | 2.00 | 4.00 | 7.00 | 7.00 | 3.903005 | 2.5641046 | |
| 5 | strength_training_7d | integer | 0.00 | 0.00 | 3.00 | 5.00 | 7.00 | 2.949948 | 2.5768522 |
We have 13K data entries, and with 13 different variables, some Qual and some Quant. Many entries are missing too, typical of real-world data and something we will have to account for in our computations. The meaning of each variable can be found by bringing up the help file.
In this tutorial, our research question is:
Research Question
Does weight of highschoolers in this dataset vary with gender?
First, histograms and densities of the variable we are interested in:
yrbss_select_gender <- yrbss %>%
select(weight, gender, physically_active_7d) %>%
drop_na(weight) # Sadly dropping off NA data
yrbss_select_gender %>%
gf_density(~weight,
fill = ~gender,
alpha = 0.5,
title = "Highschoolers' Weights by Gender"
) %>%
gf_theme(theme_classic())
yrbss_select_gender %>%
gf_boxplot(weight ~ gender,
fill = ~gender,
alpha = 0.5,
title = "Highschoolers' Weights by Gender"
) %>%
gf_theme(theme_classic())

Overlapped Distribution plot shows some difference in the means; and the Boxplots show visible difference in the medians.
As stated before, statistical tests for means usually require a couple of checks:
- Are the data normally distributed?
- Are the data variances similar?
Let us also complete a visual check for normality,with plots since we cannot do a shapiro.test:
Shapiro-Wilks Test
The longest data it can take (in R) is 5000. Since our data is longer, we will cannot use this procedure and have to resort to visual means.
male_student_weights <- yrbss_select_gender %>%
filter(gender == "male") %>%
select(weight)
female_student_weights <- yrbss_select_gender %>%
filter(gender == "female") %>%
select(weight)
# shapiro.test(male_student_weights$weight)
# shapiro.test(female_student_weights$weight)
yrbss_select_gender %>%
gf_density(~weight,
fill = ~gender,
alpha = 0.5,
title = "Highschoolers' Weights by Gender"
) %>%
gf_facet_grid(~gender) %>%
gf_fitdistr(dist = "dnorm") %>%
gf_theme(theme_classic())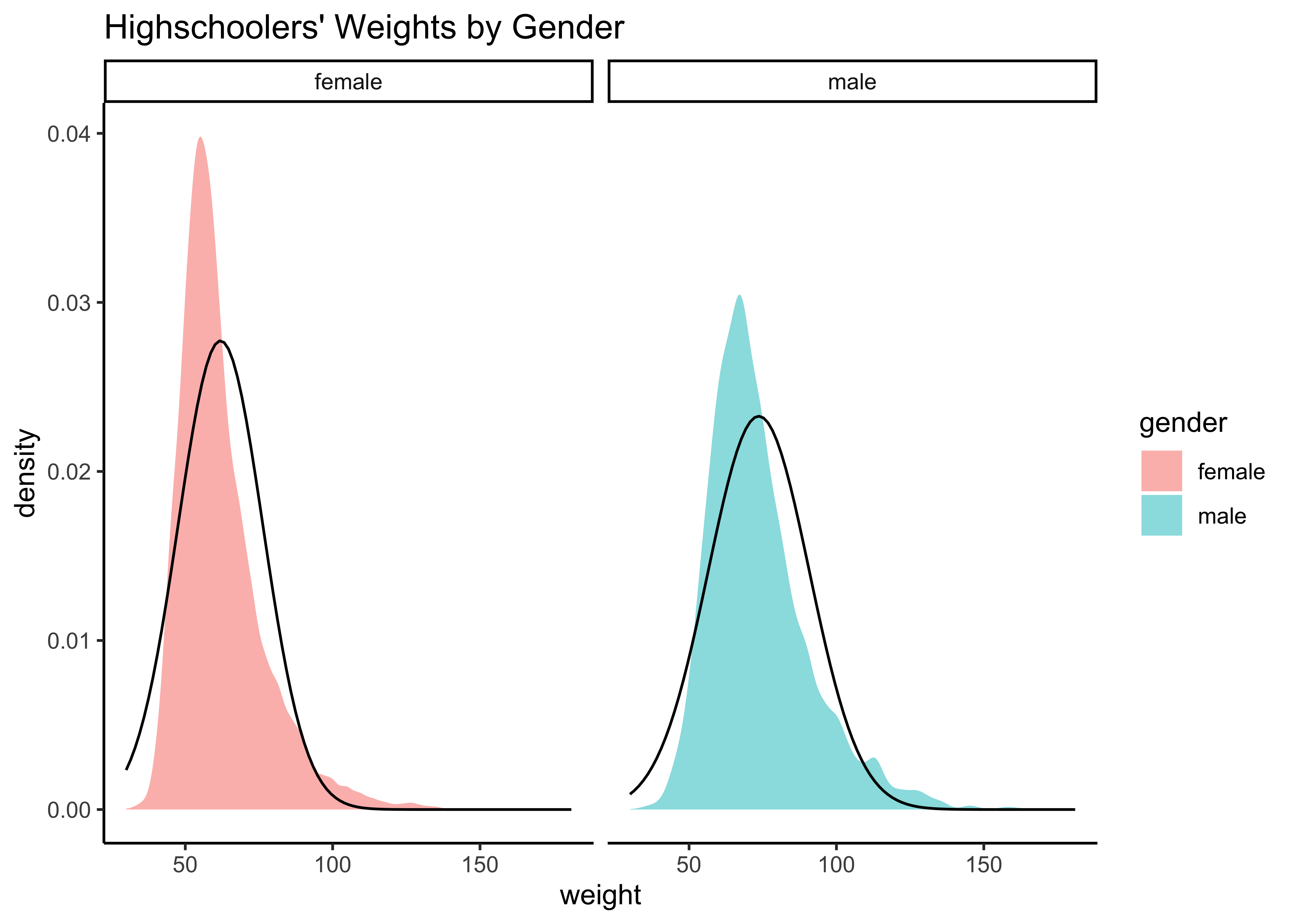
Distributions are not too close to normal…perhaps a hint of a rightward skew, suggesting that there are some obese students.
We can plot Q-Q plots3 for both variables, and also compare both data with normally-distributed data generated with the same means and standard deviations:
yrbss_select_gender %>%
gf_qq(~ weight | gender) %>%
gf_qqline(ylab = "scores") %>%
gf_theme(theme_classic())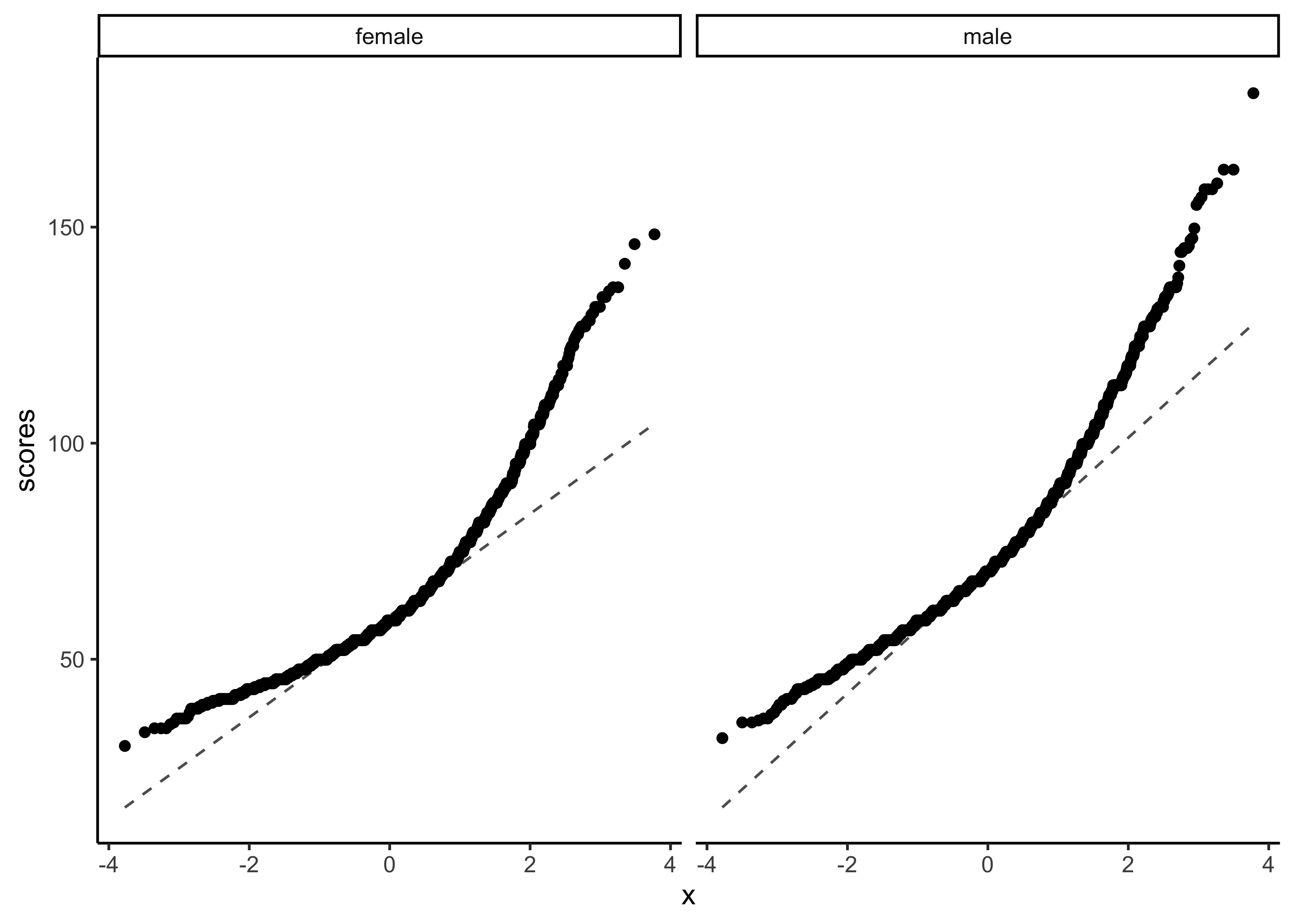
No real evidence (visually) of the variables being normally distributed.
Let us check if the two variables have similar variances: the var.test does this for us, with a NULL hypothesis that the variances are not significantly different:
var.test(weight ~ gender,
data = yrbss_select_gender,
conf.int = TRUE,
conf.level = 0.95
) %>%
broom::tidy()
# qf(0.975,6164, 6413)estimate <dbl> | num.df <int> | den.df <int> | statistic <dbl> | p.value <dbl> | conf.low <dbl> | conf.high <dbl> | method <chr> | alternative <chr> |
|---|---|---|---|---|---|---|---|---|
| 0.703976 | 6164 | 6413 | 0.703976 | 1.065068e-43 | 0.6700221 | 0.7396686 | F test to compare two variances | two.sided |
The p.value being so small, we are able to reject the NULL Hypothesis that the variances of weight are nearly equal across the two exercise regimes.
Conditions
- The two variables are not normally distributed.
- The two variances are also significantly different.
This means that the parametric t.test must be eschewed in favour of the non-parametric wilcox.test. We will use that, and also attempt linear models with rank data, and a final permutation test.
Based on the graphs, how would we formulate our Hypothesis? We wish to infer whether there is difference in mean weight across gender. So accordingly:
What would be the test statistic we would use? The difference in means. Is the observed difference in the means between the two groups of scores non-zero? We use the diffmean function, from mosaic:
obs_diff_gender <- diffmean(weight ~ gender, data = yrbss_select_gender)
obs_diff_genderdiffmean
11.70089
Since the data variables do not satisfy the assumption of being normally distributed, and the variances are significantly different, we use the classical wilcox.test, which implements what we need here: the Mann-Whitney U test:4
The Mann-Whitney test as a test of mean ranks. It first ranks all your values from high to low, computes the mean rank in each group, and then computes the probability that random shuffling of those values between two groups would end up with the mean ranks as far apart as, or further apart, than you observed. No assumptions about distributions are needed so far. (emphasis mine)
We will use the mosaic variant). Our model would be:
wilcox.test(weight ~ gender,
data = yrbss_select_gender,
conf.int = TRUE,
conf.level = 0.95
) %>%
broom::tidy()estimate <dbl> | statistic <dbl> | p.value <dbl> | conf.low <dbl> | conf.high <dbl> | method <chr> | alternative <chr> |
|---|---|---|---|---|---|---|
| -11.33999 | 10808212 | 0 | -11.34003 | -10.87994 | Wilcoxon rank sum test with continuity correction | two.sided |
The p.value is negligible and we are able to reject the NULL hypothesis that the means are equal.
We can apply the linear-model-as-inference interpretation to the ranked data data to implement the non-parametric test as a Linear Model:
# Create a sign-rank function
# signed_rank <- function(x) {sign(x) * rank(abs(x))}
lm(rank(weight) ~ gender,
data = yrbss_select_gender
) %>%
broom::tidy(
conf.int = TRUE,
conf.level = 0.95
)term <chr> | estimate <dbl> | std.error <dbl> | statistic <dbl> | p.value <dbl> | conf.low <dbl> | conf.high <dbl> |
|---|---|---|---|---|---|---|
| (Intercept) | 4836.157 | 42.52745 | 113.71848 | 0 | 4752.797 | 4919.517 |
| gendermale | 2851.246 | 59.55633 | 47.87478 | 0 | 2734.507 | 2967.986 |
Dummy Variables in
lm
Note how the Qual variable was used here in Linear Regression! The gender variable was treated as a binary “dummy” variable5.
We saw from the diagram created by Allen Downey that there is only one test6! We will now use this philosophy to develop a technique that allows us to mechanize several Statistical Models in that way, with nearly identical code. For the specific data at hand, we need to shuffle the records between Semifinal and Final on a per Swimmer basis and take the test statistic (difference between the two swim records for each swimmer). Another way to look at this is to take the differences between Semifinal and Final scores and shuffle the differences to either polarity. We will follow this method in the code below:
null_dist_weight <-
do(9999) * diffmean(data = yrbss_select_gender, weight ~ shuffle(gender))
null_dist_weight
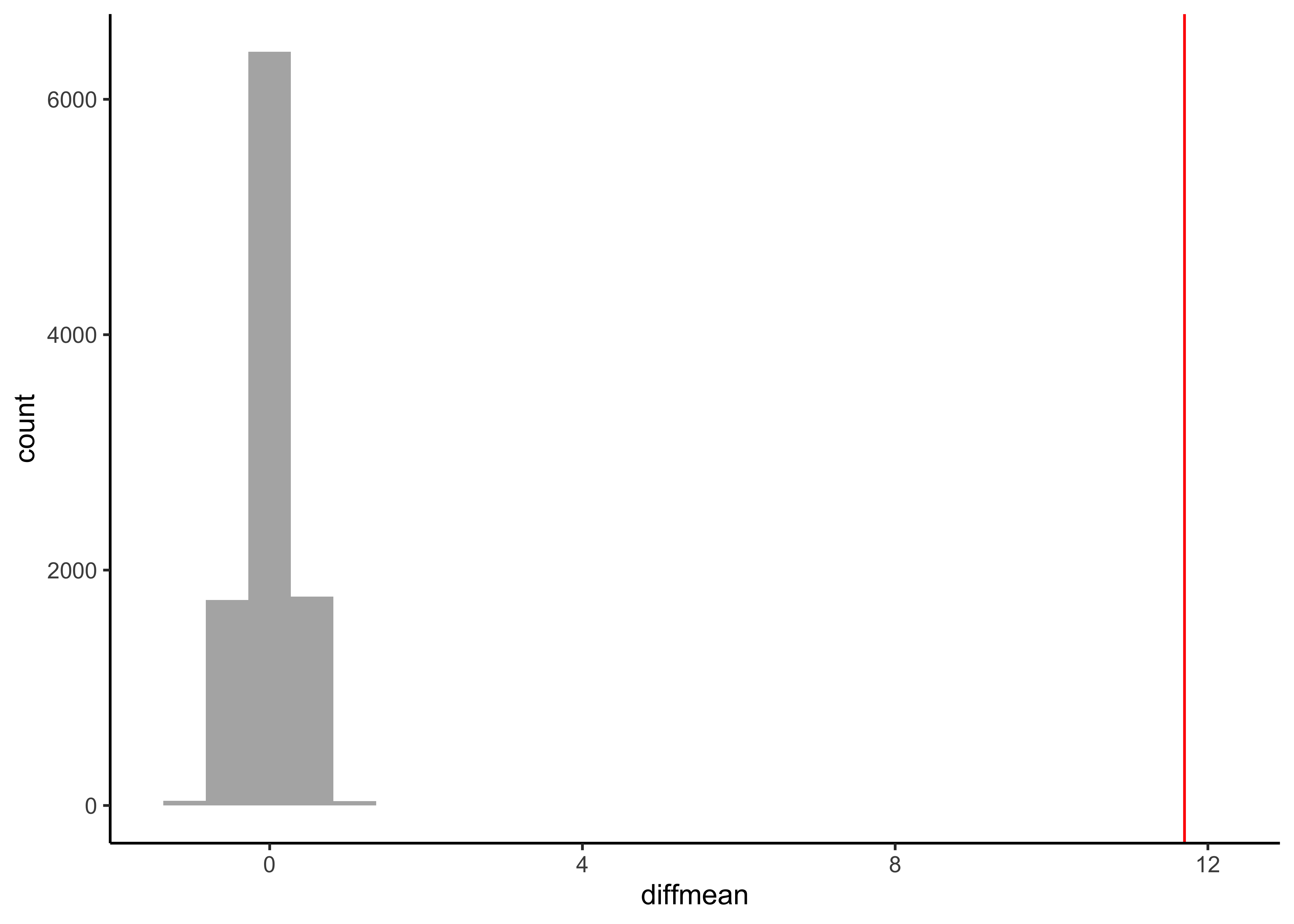
gf_histogram(data = null_dist_weight, ~diffmean, bins = 25) %>%
gf_vline(xintercept = obs_diff_gender, colour = "red") %>%
gf_theme(theme_classic())
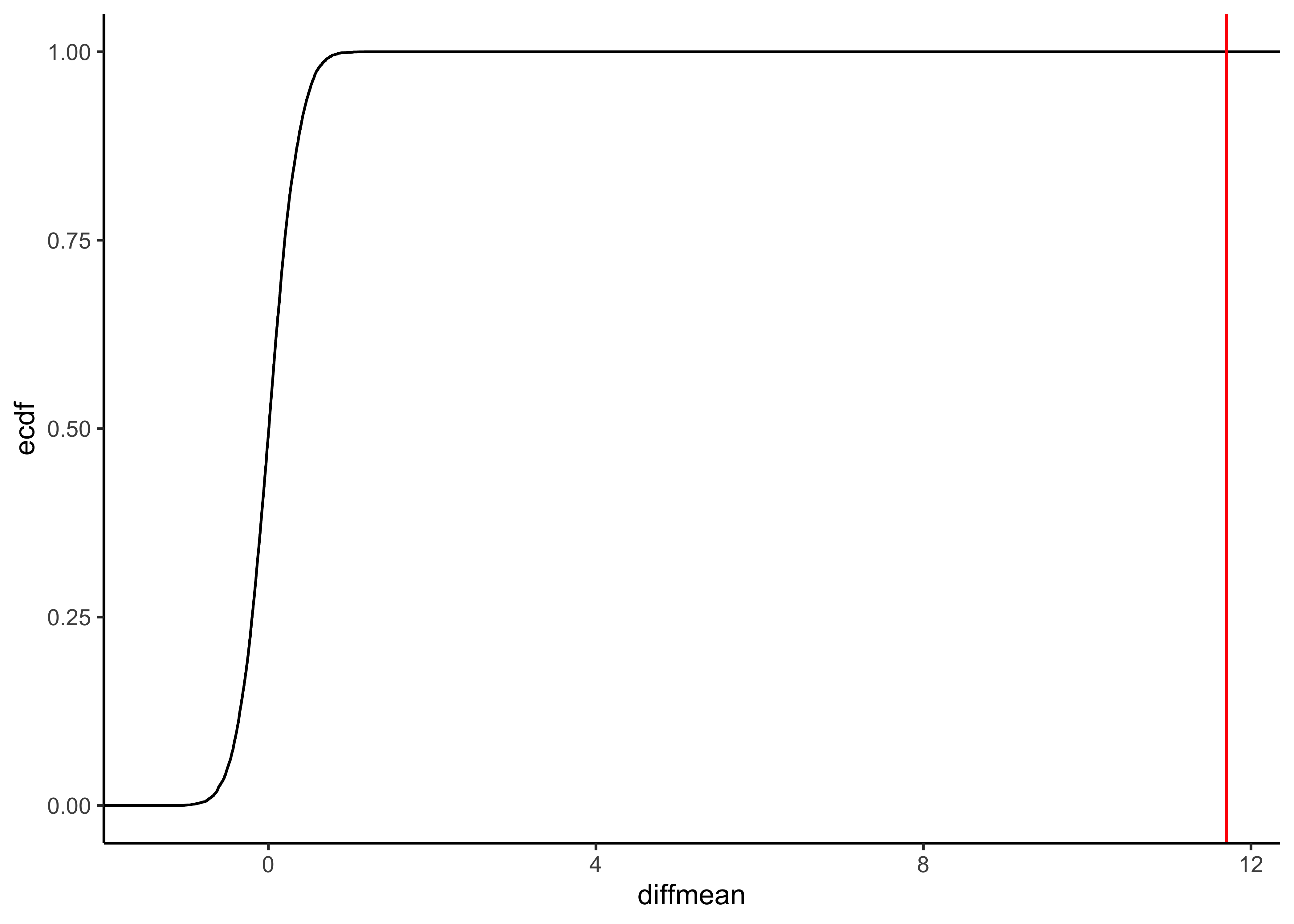
gf_ecdf(data = null_dist_weight, ~diffmean) %>%
gf_vline(xintercept = obs_diff_gender, colour = "red") %>%
gf_theme(theme_classic())
prop1(~ diffmean <= obs_diff_gender, data = null_dist_weight)diffmean <dbl> | ||||
|---|---|---|---|---|
| 2.968491e-01 | ||||
| 2.065851e-02 | ||||
| 2.334340e-02 | ||||
| -3.646964e-01 | ||||
| 1.712191e-01 | ||||
| 5.583873e-01 | ||||
| -4.461974e-01 | ||||
| 2.235745e-01 | ||||
| -1.144226e-01 | ||||
| 4.410358e-02 |
prop_TRUE
1 Clearly the observed_diff_weight is much beyond anything we can generate with permutations with gender! And hence there is a significant difference in weights across gender!
We can put all the test results together to get a few more insights about the tests:
wilcox.test(weight ~ gender,
data = yrbss_select_gender,
conf.int = TRUE,
conf.level = 0.95
) %>%
broom::tidy() %>%
gt() %>%
tab_style(
style = list(cell_fill(color = "cyan"), cell_text(weight = "bold")),
locations = cells_body(columns = p.value)
) %>%
tab_header(title = "wilcox.test")
lm(rank(weight) ~ gender,
data = yrbss_select_gender
) %>%
broom::tidy(
conf.int = TRUE,
conf.level = 0.95
) %>%
gt() %>%
tab_style(
style = list(cell_fill(color = "cyan"), cell_text(weight = "bold")),
locations = cells_body(columns = p.value)
) %>%
tab_header(title = "Linear Model with Ranked Data")| wilcox.test | ||||||
|---|---|---|---|---|---|---|
| estimate | statistic | p.value | conf.low | conf.high | method | alternative |
| -11.33999 | 10808212 | 0 | -11.34003 | -10.87994 | Wilcoxon rank sum test with continuity correction | two.sided |
| Linear Model with Ranked Data | ||||||
|---|---|---|---|---|---|---|
| term | estimate | std.error | statistic | p.value | conf.low | conf.high |
| (Intercept) | 4836.157 | 42.52745 | 113.71848 | 0 | 4752.797 | 4919.517 |
| gendermale | 2851.246 | 59.55633 | 47.87478 | 0 | 2734.507 | 2967.986 |
The wilcox.test and the linear model with rank data offer the same results. This is of course not surprising!
Next, consider the possible relationship between a highschooler’s weight and their physical activity.
First, let’s create a new variable physical_3plus, which will be coded as either “yes” if the student is physically active for at least 3 days a week, and “no” if not. Recall that we have several missing data in that column, so we will (sadly) drop these before generating the new variable:
yrbss_select_phy <- yrbss %>%
drop_na(physically_active_7d, weight) %>%
mutate(
physical_3plus = if_else(physically_active_7d >= 3, "yes", "no"),
physical_3plus = factor(physical_3plus,
labels = c("yes", "no"),
levels = c("yes", "no")
)
) %>%
select(weight, physical_3plus)
# Let us check
yrbss_select_phy %>% count(physical_3plus)physical_3plus <fct> | n <int> | |||
|---|---|---|---|---|
| yes | 8342 | |||
| no | 4022 |
Research Question
Does weight vary based on whether students exercise on more or less than 3 days a week? (physically_active_7d >= 3 days)
We can make distribution plots for weight by physical_3plus:
gf_boxplot(weight ~ physical_3plus,
fill = ~physical_3plus,
data = yrbss_select_phy, xlab = "Days of Exercise >=3 "
) %>%
gf_theme(theme_classic())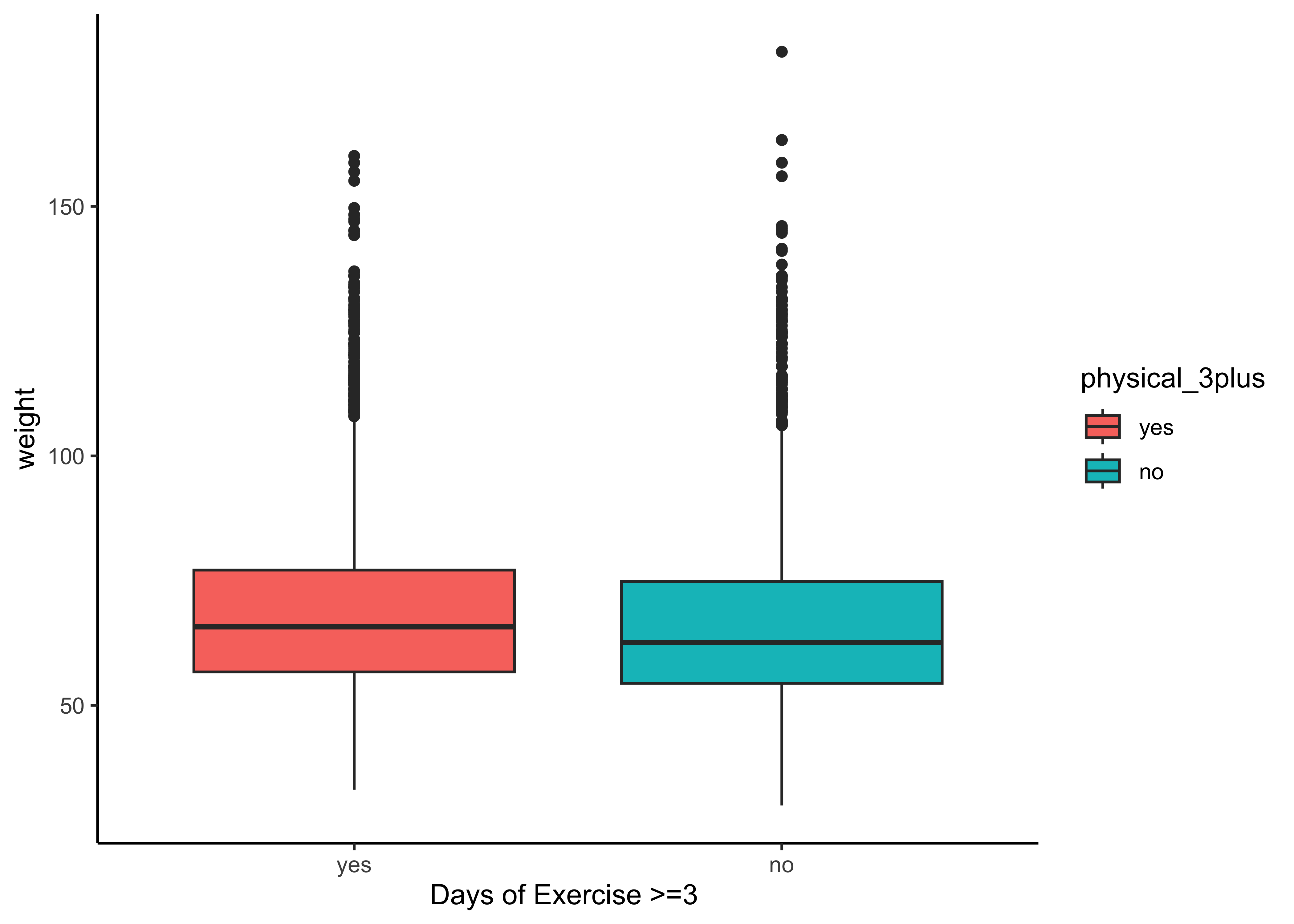
gf_density(~weight,
fill = ~physical_3plus,
data = yrbss_select_phy
) %>%
gf_theme(theme_classic())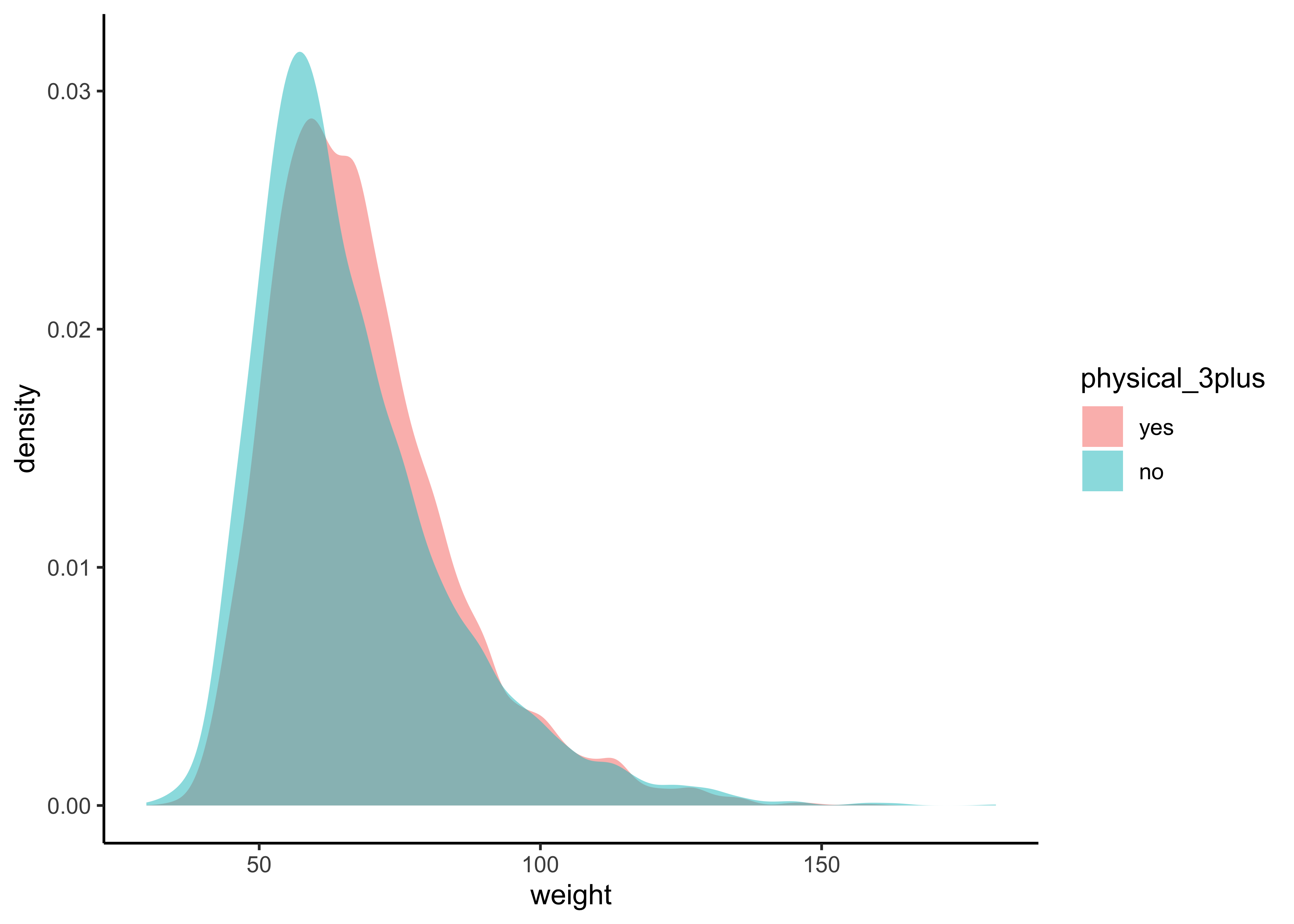
The box plots show how the medians of the two distributions compare, but we can also compare the means of the distributions using the following to first group the data by the physical_3plus variable, and then calculate the mean weight in these groups using the mean function while ignoring missing values by setting the na.rm argument to TRUE.
yrbss_select_phy %>%
group_by(physical_3plus) %>%
summarise(mean_weight = mean(weight, na.rm = TRUE))physical_3plus <fct> | mean_weight <dbl> | |||
|---|---|---|---|---|
| yes | 68.44847 | |||
| no | 66.67389 |
There is an observed difference, but is this difference large enough to deem it “statistically significant”? In order to answer this question we will conduct a hypothesis test. But before that a few more checks on the data:
As stated before, statistical tests for means usually require a couple of checks:
- Are the data normally distributed?
- Are the data variances similar?
Let us also complete a visual check for normality,with plots since we cannot do a shapiro.test:
yrbss_select_phy %>%
gf_density(~weight,
fill = ~physical_3plus,
alpha = 0.5,
title = "Highschoolers' Weights by Exercise Frequency"
) %>%
gf_facet_grid(~physical_3plus) %>%
gf_fitdistr(dist = "dnorm") %>%
gf_theme(theme_classic())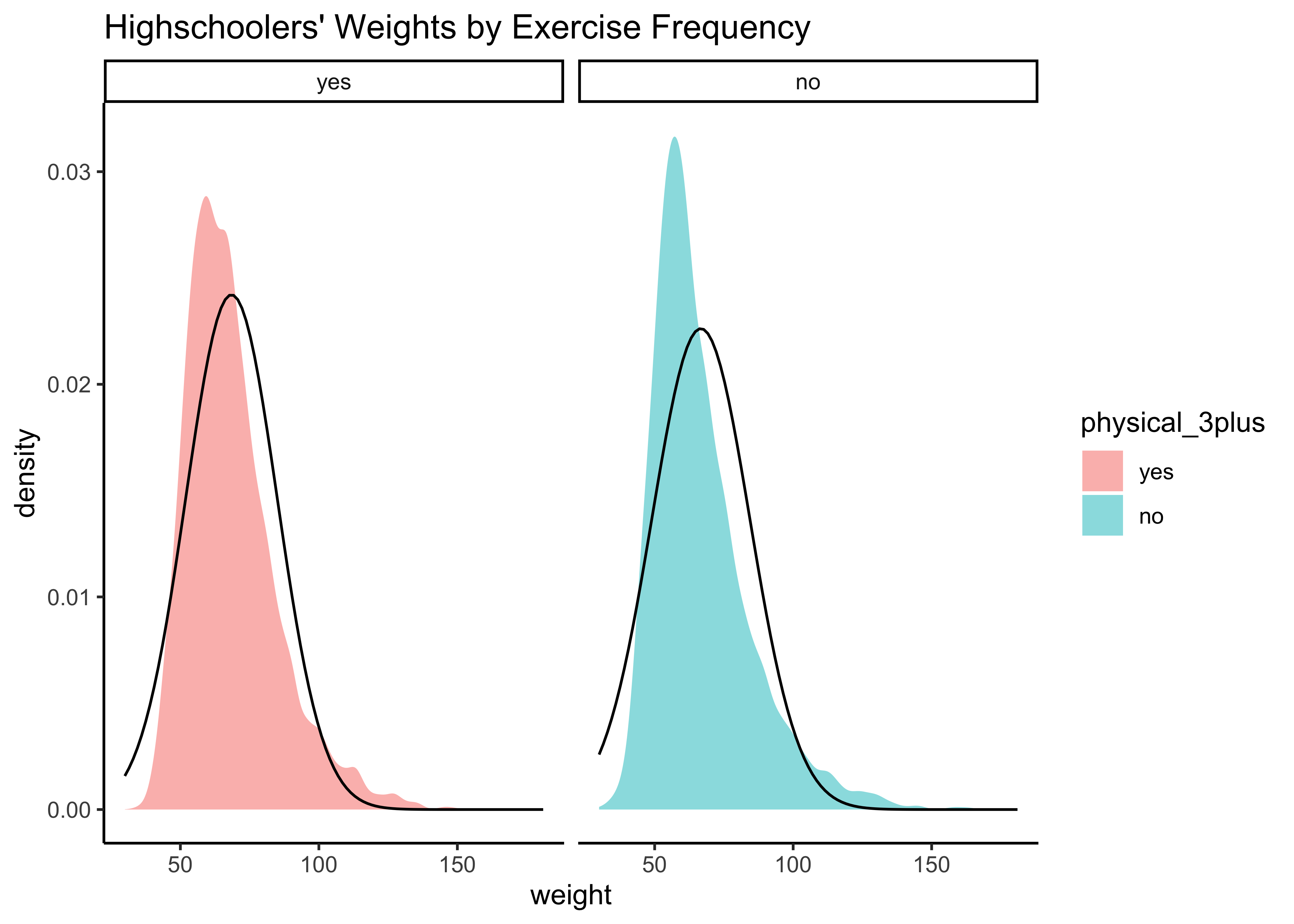
Again, not normally distributed…
We can plot Q-Q plots for both variables, and also compare both data with normally-distributed data generated with the same means and standard deviations:
yrbss_select_phy %>%
gf_qq(~ weight | physical_3plus, color = ~physical_3plus) %>%
gf_qqline(ylab = "Weight") %>%
gf_theme(theme_classic())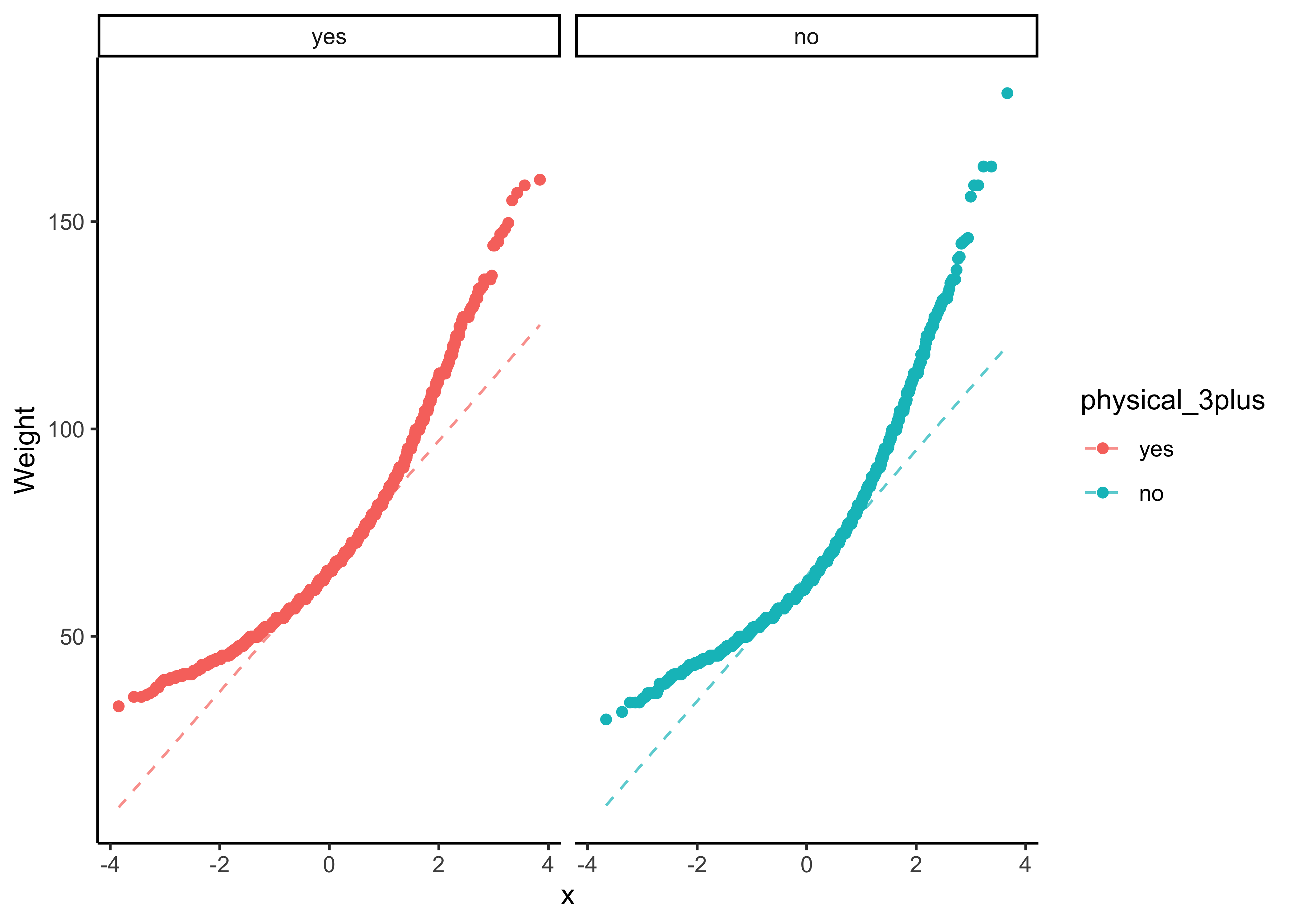
The QQ-plots confirm that he tow data variables are not normally distributed.
Let us check if the two variables have similar variances: the var.test does this for us, with a NULL hypothesis that the variances are not significantly different:
var.test(weight ~ physical_3plus,
data = yrbss_select_phy,
conf.int = TRUE,
conf.level = 0.95
) %>%
broom::tidy()
# Critical F value
qf(0.975, 4021, 8341)estimate <dbl> | num.df <int> | den.df <int> | statistic <dbl> | p.value <dbl> | conf.low <dbl> | conf.high <dbl> | method <chr> | alternative <chr> |
|---|---|---|---|---|---|---|---|---|
| 0.8728201 | 8341 | 4021 | 0.8728201 | 4.390179e-07 | 0.8273749 | 0.9202997 | F test to compare two variances | two.sided |
[1] 1.054398The p.value states the probability of the data being what it is, assuming the NULL hypothesis that variances were similar. It being so small, we are able to reject this NULL Hypothesis that the variances of weight are nearly equal across the two exercise frequencies. (Compare the statistic in the var.test with the critical F-value)
Conditions
- The two variables are not normally distributed.
- The two variances are also significantly different.
Hence we will have to use non-parametric tests to infer if the means are similar.
Based on the graphs, how would we formulate our Hypothesis? We wish to infer whether there is difference in mean weight across physical_3plus. So accordingly:
Statistic
What would be the test statistic we would use? The difference in means. Is the observed difference in the means between the two groups of scores non-zero? We use the diffmean function, from mosaic:
obs_diff_phy <- diffmean(weight ~ physical_3plus, data = yrbss_select_phy)
obs_diff_phy diffmean
-1.774584 Well, the variables are not normally distributed, and the variances are significantly different so a standard t.test is not advised. We can still try:
mosaic::t_test(weight ~ physical_3plus,
var.equal = FALSE, # Welch Correction
data = yrbss_select_phy
) %>%
broom::tidy()estimate <dbl> | estimate1 <dbl> | estimate2 <dbl> | statistic <dbl> | p.value <dbl> | parameter <dbl> | conf.low <dbl> | conf.high <dbl> | method <chr> | alternative <chr> |
|---|---|---|---|---|---|---|---|---|---|
| 1.774584 | 68.44847 | 66.67389 | 5.353003 | 8.907531e-08 | 7478.84 | 1.124728 | 2.424441 | Welch Two Sample t-test | two.sided |
The p.value is Confidence Interval is clear of t.test gives us good reason to reject the Null Hypothesis that the means are similar. But can we really believe this, given the non-normality of data?
However, we have seen that the data variables are not normally distributed. So a Wilcoxon Test, using signed-ranks, is indicated: (recall the model!)
# For stability reasons, it may be advisable to use rounded data or to set digits.rank = 7, say,
# such that determination of ties does not depend on very small numeric differences (see the example).
wilcox.test(weight ~ physical_3plus,
conf.int = TRUE,
conf.level = 0.95,
data = yrbss_select_phy
) %>%
broom::tidy()estimate <dbl> | statistic <dbl> | p.value <dbl> | conf.low <dbl> | conf.high <dbl> | method <chr> | alternative <chr> |
|---|---|---|---|---|---|---|
| 2.269967 | 18314392 | 1.262977e-16 | 1.819992 | 2.720077 | Wilcoxon rank sum test with continuity correction | two.sided |
The nonparametric wilcox.test also suggests that the means for weight across physical_3plus are significantly different.
Using the Linear Model Interpretation
We can apply the linear-model-as-inference interpretation to the ranked data data to implement the non-parametric test as a Linear Model:
lm(rank(weight) ~ physical_3plus,
data = yrbss_select_phy
) %>%
broom::tidy(
conf.int = TRUE,
conf.level = 0.95
)term <chr> | estimate <dbl> | std.error <dbl> | statistic <dbl> | p.value <dbl> | conf.low <dbl> | conf.high <dbl> |
|---|---|---|---|---|---|---|
| (Intercept) | 6366.9438 | 38.96362 | 163.407391 | 0.000000e+00 | 6290.5690 | 6443.3186 |
| physical_3plusno | -566.9972 | 68.31527 | -8.299715 | 1.151496e-16 | -700.9058 | -433.0887 |
Here too, the linear model using rank data arrives at a conclusion similar to that of the Mann-Whitney U test.
Using Permutation Tests
We will do this in two ways, just for fun: one using mosaic and the other using infer.
But first, we need to initialize the test, which we will save as obs_diff.
obs_diff_infer <- yrbss_select_phy %>%
infer::specify(weight ~ physical_3plus) %>%
infer::calculate(stat = "diff in means", order = c("yes", "no"))
obs_diff_infer
obs_diff_mosaic <- mosaic::diffmean(~ weight | physical_3plus, data = yrbss_select_phy)
obs_diff_mosaic
obs_diff_phystat <dbl> | ||||
|---|---|---|---|---|
| 1.774584 |
diffmean
-1.774584 diffmean
-1.774584
Important
Note that obs_diff_infer is a 1 X 1 dataframe; obs_diff_mosaic is a scalar!!
We already have the observed difference, obs_diff_mosaic. Now we generate the null distribution using permutation, with mosaic:
We can also generate the histogram of the null distribution, compare that with the observed diffrence and compute the p-value and confidence intervals:
gf_histogram(~diffmean, data = null_dist_mosaic) %>%
gf_vline(xintercept = obs_diff_mosaic, colour = "red")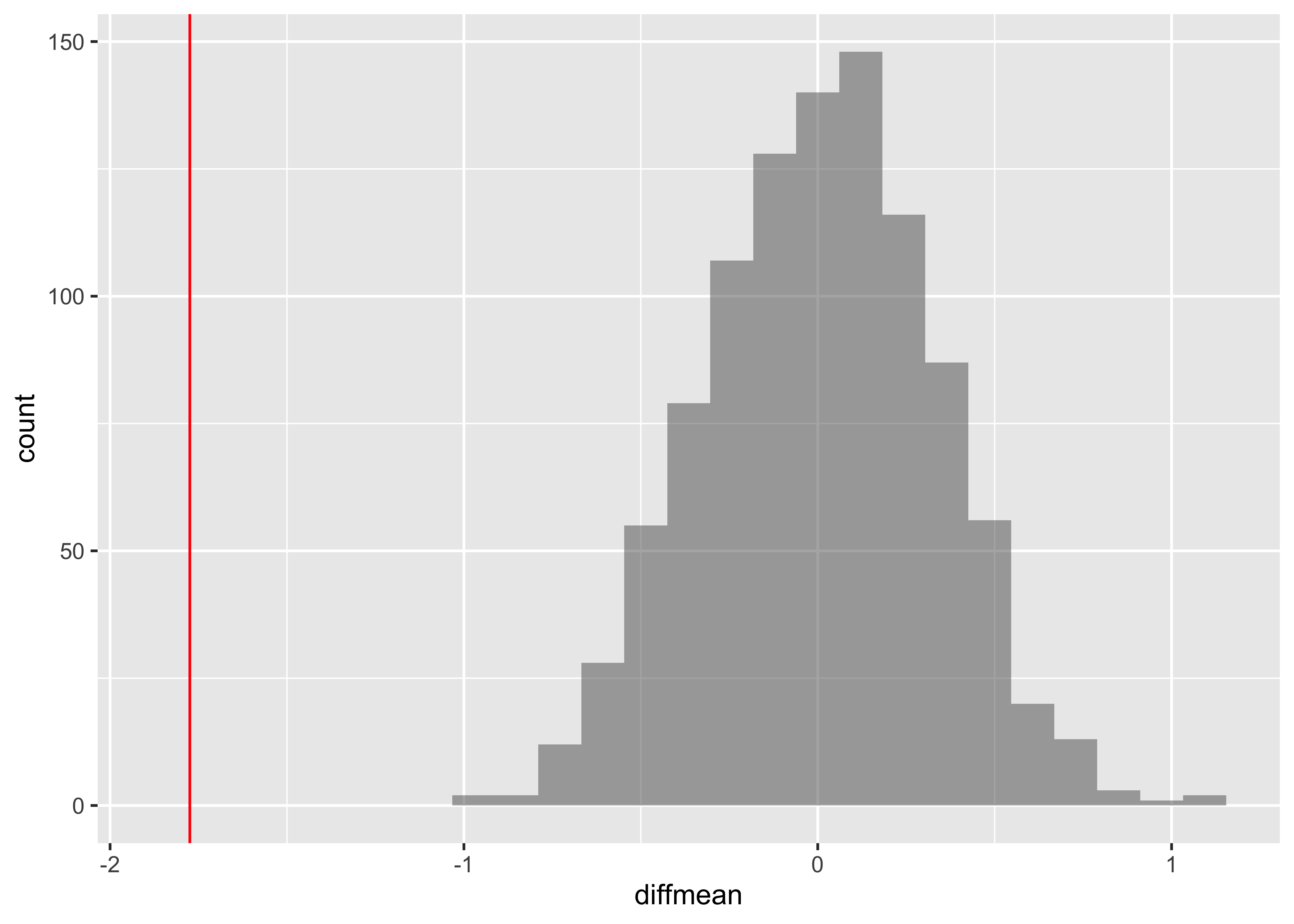
# p-value
prop(~ diffmean != obs_diff_mosaic, data = null_dist_mosaic)prop_TRUE
1 # Confidence Intervals for p = 0.95
mosaic::cdata(~diffmean, p = 0.95, data = null_dist_mosaic)lower <dbl> | upper <dbl> | central.p <dbl> | ||
|---|---|---|---|---|
| 2.5% | -0.6019895 | 0.614377 | 0.95 |
Your Turn
Calculate a 95% confidence interval for the average height in meters (
height) and interpret it in context.Calculate a new confidence interval for the same parameter at the 90% confidence level. Comment on the width of this interval versus the one obtained in the previous exercise.
Conduct a hypothesis test evaluating whether the average height is different for those who exercise at least three times a week and those who don’t.
Now, a non-inference task: Determine the number of different options there are in the dataset for the
hours_tv_per_school_daythere are.Come up with a research question evaluating the relationship between height or weight and sleep. Formulate the question in a way that it can be answered using a hypothesis test and/or a confidence interval. Report the statistical results, and also provide an explanation in plain language. Be sure to check all assumptions, state your
Footnotes
https://stats.stackexchange.com/questions/2492/is-normality-testing-essentially-useless↩︎
https://www.allendowney.com/blog/2023/01/28/never-test-for-normality/↩︎
https://stats.stackexchange.com/questions/92374/testing-large-dataset-for-normality-how-and-is-it-reliable↩︎
https://allendowney.blogspot.com/2016/06/there-is-still-only-one-test.html↩︎