🃏 Testing a Single Proportion
Plot Fonts and Theme
Show the Code
library(systemfonts)
library(showtext)
## Clean the slate
systemfonts::clear_local_fonts()
systemfonts::clear_registry()
##
showtext_opts(dpi = 96) # set DPI for showtext
sysfonts::font_add(
family = "Alegreya",
regular = "../../../../../../fonts/Alegreya-Regular.ttf",
bold = "../../../../../../fonts/Alegreya-Bold.ttf",
italic = "../../../../../../fonts/Alegreya-Italic.ttf",
bolditalic = "../../../../../../fonts/Alegreya-BoldItalic.ttf"
)Error in check_font_path(bold, "bold"): font file not found for 'bold' typeShow the Code
sysfonts::font_add(
family = "Roboto Condensed",
regular = "../../../../../../fonts/RobotoCondensed-Regular.ttf",
bold = "../../../../../../fonts/RobotoCondensed-Bold.ttf",
italic = "../../../../../../fonts/RobotoCondensed-Italic.ttf",
bolditalic = "../../../../../../fonts/RobotoCondensed-BoldItalic.ttf"
)
showtext_auto(enable = TRUE) # enable showtext
##
theme_custom <- function() {
font <- "Alegreya" # assign font family up front
theme_classic(base_size = 14, base_family = font) %+replace% # replace elements we want to change
theme(
text = element_text(family = font), # set base font family
# text elements
plot.title = element_text( # title
family = font, # set font family
size = 24, # set font size
face = "bold", # bold typeface
hjust = 0, # left align
margin = margin(t = 5, r = 0, b = 5, l = 0)
), # margin
plot.title.position = "plot",
plot.subtitle = element_text( # subtitle
family = font, # font family
size = 14, # font size
hjust = 0, # left align
margin = margin(t = 5, r = 0, b = 10, l = 0)
), # margin
plot.caption = element_text( # caption
family = font, # font family
size = 9, # font size
hjust = 1
), # right align
plot.caption.position = "plot", # right align
axis.title = element_text( # axis titles
family = "Roboto Condensed", # font family
size = 12
), # font size
axis.text = element_text( # axis text
family = "Roboto Condensed", # font family
size = 9
), # font size
axis.text.x = element_text( # margin for axis text
margin = margin(5, b = 10)
)
# since the legend often requires manual tweaking
# based on plot content, don't define it here
)
}Show the Code
```{r}
#| cache: false
#| code-fold: true
## Set the theme
theme_set(new = theme_custom())
## Use available fonts in ggplot text geoms too!
update_geom_defaults(geom = "text", new = list(
family = "Roboto Condensed",
face = "plain",
size = 3.5,
color = "#2b2b2b"
))
```
Often we hear reports that a certain percentage of people support a certain political party, or that a certain proportion of people are in favour of a certain policy. Such statements are the result of a desire to infer a proportion in the population, which is what we will investigate here.
We have seen how sampling from a population works when we wish to estimate means:
- The sample means
- The samples means are normally distributed
- The uncertainty in using
- The larger the size of the sample, the tighter the Confidence Interval.
Now then: does a similar logic work for proportions too, as for means?
- Sample proportions are also centred around population proportions
-
Success-failure condition: If
- The Standard Error for a sample proportion is given by
- We would calculate the Confidence Intervals in a similar fashion, based on the desired probability of error, as:
We will be analyzing the same dataset called the Youth Risk Behavior Surveillance System (YRBSS) survey from the openintro package, which uses data from high schoolers to help discover health patterns. The dataset is called yrbss.
data(yrbss, package = "openintro")
yrbssage <int> | gender <chr> | grade <chr> | hispanic <chr> | race <chr> | height <dbl> | weight <dbl> | helmet_12m <chr> | text_while_driving_30d <chr> | physically_active_7d <int> | |
|---|---|---|---|---|---|---|---|---|---|---|
| 14 | female | 9 | not | Black or African American | NA | NA | never | 0 | 4 | |
| 14 | female | 9 | not | Black or African American | NA | NA | never | NA | 2 | |
| 15 | female | 9 | hispanic | Native Hawaiian or Other Pacific Islander | 1.73 | 84.37 | never | 30 | 7 | |
| 15 | female | 9 | not | Black or African American | 1.60 | 55.79 | never | 0 | 0 | |
| 15 | female | 9 | not | Black or African American | 1.50 | 46.72 | did not ride | did not drive | 2 | |
| 15 | female | 9 | not | Black or African American | 1.57 | 67.13 | did not ride | did not drive | 1 | |
| 15 | female | 9 | not | Black or African American | 1.65 | 131.54 | did not ride | NA | 4 | |
| 14 | male | 9 | not | Black or African American | 1.88 | 71.22 | never | NA | 4 | |
| 15 | male | 9 | not | Black or African American | 1.75 | 63.50 | never | NA | 5 | |
| 15 | male | 10 | not | Black or African American | 1.37 | 97.07 | did not ride | NA | 0 |
When summarizing the YRBSS data, the Centers for Disease Control and Prevention seeks insight into the population parameters. Accordingly, in this tutorial, our research questions are:
What are the counts within each category for the amount of days these students have texted while driving within the past 30 days?
What proportion of people on earth have texted while driving each day for the past 30 days without wearing helmets?
Question 1 pertains to the data set yrbss, our “sample”. To answer this, you can answer the question, “What proportion of people in your sample reported that they have texted while driving each day for the past 30 days?” with a statistic. Question 2 is an inference we need to make about the population of highschoolers. While the question “What proportion of people on earth have texted while driving each day for the past 30 days?” is answered with an estimate of the parameter.
For our first Research Question, we will choose the column helmet_12m: Remember that you can use filter to limit the dataset to just non-helmet wearers. Here, we will name the (filtered ) dataset no_helmet.
helmet_12m <chr> | n <int> | |||
|---|---|---|---|---|
| always | 399 | |||
| did not ride | 4549 | |||
| most of time | 293 | |||
| never | 6977 | |||
| rarely | 713 | |||
| sometimes | 341 | |||
| NA | 311 |
text_while_driving_30d <chr> | n <int> | |||
|---|---|---|---|---|
| 0 | 4792 | |||
| 1-2 | 925 | |||
| 10-19 | 373 | |||
| 20-29 | 298 | |||
| 3-5 | 493 | |||
| 30 | 827 | |||
| 6-9 | 311 | |||
| did not drive | 4646 | |||
| NA | 918 |
Also, it may be easier to calculate the proportion if we create a new variable that specifies whether the individual has texted every day while driving over the past 30 days or not. We will call this variable text_ind.
no_helmet_text <- yrbss %>%
filter(helmet_12m == "never") %>%
mutate(text_ind = ifelse(text_while_driving_30d == "30", "yes", "no")) %>%
# removing most of the other variables
select(age, gender, text_ind)
no_helmet_textage <int> | gender <chr> | text_ind <chr> | ||
|---|---|---|---|---|
| 14 | female | no | ||
| 14 | female | NA | ||
| 15 | female | yes | ||
| 15 | female | no | ||
| 14 | male | NA | ||
| 15 | male | NA | ||
| 16 | male | no | ||
| 14 | male | no | ||
| 15 | male | no | ||
| 16 | male | no |
text_ind <chr> | n <int> | |||
|---|---|---|---|---|
| no | 6025 | |||
| yes | 462 |
prop <dbl> | n <int> | |||
|---|---|---|---|---|
| 0.07121936 | 6487 |
This is the observed_statistic: the proportion of people in this sample who do text when they drive without a helmet.
Visualizing a Single Proportion
We can quickly plot this, just for the sake of visual understanding of the proportions:
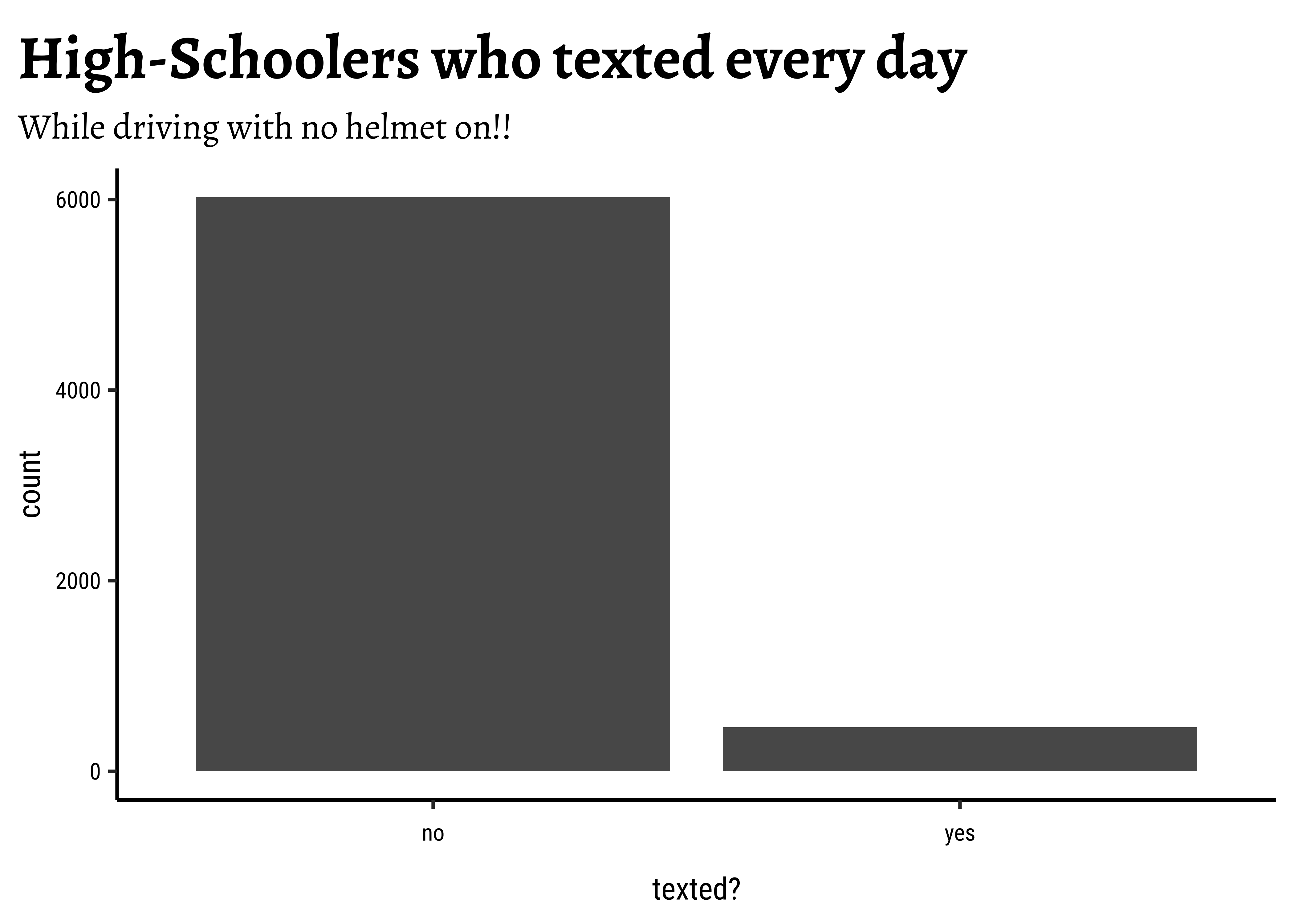
Inference for a Single Proportion
Based on this sample in the yrbss data, we wish to infer proportions for the population of high-schoolers.
Hypothesis Testing for a Single Proportion
Consider the inference we did for a single mean. What was our NULL Hypothesis? That the population mean
With proportions, we usually look for a “no difference” situation, i.e. a ratio of unity!! So our NULL hypothesis would be a proportion of 1:1 for texters and no-texters, so a proportion of
The simplest test in R for a single proportion is the binom.test:
mosaic::binom.test(~text_ind, data = no_helmet_text, success = "yes")
data: no_helmet_text$text_ind [with success = yes]
number of successes = 463, number of trials = 6503, p-value < 2.2e-16
alternative hypothesis: true probability of success is not equal to 0.5
95 percent confidence interval:
0.06506429 0.07771932
sample estimates:
probability of success
0.07119791 mosaic::binom.test(~text_ind, data = no_helmet_text, success = "yes") %>%
broom::tidy()estimate <dbl> | statistic <dbl> | p.value <dbl> | parameter <dbl> | conf.low <dbl> | conf.high <dbl> | alternative <chr> |
|---|---|---|---|---|---|---|
| 0.07119791 | 463 | 0 | 6503 | 0.06506429 | 0.07771932 | two.sided |
How do we understand this result? That the sample tells us the p-value is
The Confidence Intervals from the binom.test inform us about our population proportion estimate: It lies within the interval [0.06506429, 0.07771932]. We know that this is also given by:
The inferential tools for estimating a single population proportion are analogous to those used for estimating single population means: the bootstrap confidence interval and the hypothesis test.
no_helmet_text %>%
drop_na() %>%
specify(response = text_ind, success = "yes") %>%
generate(reps = 999, type = "bootstrap") %>%
calculate(stat = "prop") %>%
get_ci(level = 0.95)lower_ci <dbl> | upper_ci <dbl> | |||
|---|---|---|---|---|
| 0.06474487 | 0.07739325 |
Note that since the goal is to construct an interval estimate for a proportion, it’s necessary to both include the success argument within specify, which accounts for the proportion of non-helmet wearers than have consistently texted while driving the past 30 days, in this example, and that stat within calculate is here “prop”, signaling that we are trying to do some sort of inference on a proportion.
To be Written up in the foreseeable future.
- In business, or “design research”, one encounters things that are proportions in a target population:
- Adoption of a service or an app
- People preferring a particular product
- Beliefs which are of Yes/No type: Is this Govt. doing the right thing with respect to taxes?
- Knowing what this population proportion is a necessary step to take a decision about what you will do about it.
- (Other than plot a *&%#$$%^& pie chart)
- We have seen how the CLT works with proportions, in a manner similar to that with means
- The Standard Error (and therefore the CI) for the inference of a proportion is related to the actual population proportion, which is very different behaviour from that with means, where SE was just a number that depended on the sample size
- Bootstrap procedures work with inference for a single proportion. (Permutation when there are two)
Type
data(package = "resampledata")anddata(package = "resampledata3")in your RStudio console. This will list the datasets in both these package. Try loading a few of these and infering for single proportions.National Health and Nutrition Examination Survey (NHANES) dataset. Install the package
NHANESand explore the dataset for proportions that might be interesting.
- StackExchange.
prop.testvsbinom.testin R. https://stats.stackexchange.com/q/551329 - Mine Çetinkaya-Rundel and Johanna Hardin, OpenIntro Modern Statistics: Chapter 17
- Laura M. Chihara, Tim C. Hesterberg, Mathematical Statistics with Resampling and R. 3 August 2018.© 2019 John Wiley & Sons, Inc.
- OpenIntro Statistics Github Repo: https://github.com/OpenIntroStat/openintro-statistics
Citation
@online{2022,
author = {},
title = {🃏 {Testing} a {Single} {Proportion}},
date = {2022-11-10},
url = {https://av-quarto.netlify.app/content/courses/Analytics/Inference/Modules/180-OneProp/},
langid = {en},
abstract = {Inference Tests for the significance of a Proportion}
}