knitr::opts_chunk$set(message = TRUE) # Want tidylog messages
library(tidyverse)
library(tidylog) ## Explains what happens with dplyr verbsIntroduction to the dplyr package
One of the dominant paradigms of working with data in R is to render it into “tidy” form. A huge benefit of the tidy way of working is that it influences your thinking with data and helps plan out your operations, in going from purpose to actual code in a swift and intuitive manner. This tidy form allows for a huge variety of data manipulation, summarizing, and plotting tasks, that can be performed using the packages of the tidyverse, and other packages that leverage the power of the tidyverse.
Setting up the Packages
Tidy Data
[1] 87 14starwarsname <chr> | height <int> | mass <dbl> | hair_color <chr> | skin_color <chr> | eye_color <chr> | birth_year <dbl> | sex <chr> | gender <chr> | homeworld <chr> | |
|---|---|---|---|---|---|---|---|---|---|---|
| Luke Skywalker | 172 | 77.0 | blond | fair | blue | 19.0 | male | masculine | Tatooine | |
| C-3PO | 167 | 75.0 | NA | gold | yellow | 112.0 | none | masculine | Tatooine | |
| R2-D2 | 96 | 32.0 | NA | white, blue | red | 33.0 | none | masculine | Naboo | |
| Darth Vader | 202 | 136.0 | none | white | yellow | 41.9 | male | masculine | Tatooine | |
| Leia Organa | 150 | 49.0 | brown | light | brown | 19.0 | female | feminine | Alderaan | |
| Owen Lars | 178 | 120.0 | brown, grey | light | blue | 52.0 | male | masculine | Tatooine | |
| Beru Whitesun Lars | 165 | 75.0 | brown | light | blue | 47.0 | female | feminine | Tatooine | |
| R5-D4 | 97 | 32.0 | NA | white, red | red | NA | none | masculine | Tatooine | |
| Biggs Darklighter | 183 | 84.0 | black | light | brown | 24.0 | male | masculine | Tatooine | |
| Obi-Wan Kenobi | 182 | 77.0 | auburn, white | fair | blue-gray | 57.0 | male | masculine | Stewjon |
“Tidy Data” is an important way of thinking about what data typically look like in R. Let’s fetch a figure from the web to show the (preferred) structure of data in R.

The three features described in the figure above define the nature of tidy data:
- Variables in Columns
- Observations in Rows and
- Measurements in Cells.
Data are imagined to be resulting from an experiment. Each variable represents a parameter/aspect in the experiment. Each row represents an additional datum of measurement. A cell is a single measurement on a single parameter(column) in a single observation(row).
When working with data you must:
- Figure out what you want to do. (Purpose)
- Describe those tasks in the form of a computer program. (Plain English to R Code)
- Execute the program.
The dplyr package makes these steps fast and easy:
- By constraining your options, it helps you think about your data manipulation challenges.
- It provides simple “verbs”, functions that correspond to the most common data manipulation tasks, to help you translate your thoughts into code.
- It uses efficient backends, so you spend less time waiting for the computer.
Ne’er you mind about backends ;-) See Shakespeare’s Hamlet.
This document introduces you to dplyr’s basic set of tools, and shows you how to apply them to data frames. dplyr also supports databases via the dbplyr package, once you’ve installed, read vignette("dbplyr") to learn more.
Data: starwars
To explore the basic data manipulation verbs of dplyr, we’ll use the dataset starwars. This dataset contains 87 characters and comes from the Star Wars API, and is documented in ?starwars
This means: type
?starwarsin the Console. Try.
Note that starwars is a tibble, a modern re-imagining of the data frame. It’s particularly useful for large datasets because it only prints the first few rows. You can learn more about tibbles at https://tibble.tidyverse.org; in particular you can convert data frames to tibbles with as_tibble().
Check your Environment Tab to inspect
starwarsin a separate tab.
Single table verbs
dplyr aims to provide a function for each basic verb of data manipulation. These verbs can be organised into three categories based on the component of the dataset that they work with:
- Rows:
-
filter()chooses rows based on column values. -
slice()chooses rows based on location. -
arrange()changes the order of the rows.
-
- Columns:
-
select()changes whether or not a column is included. -
rename()changes the name of columns. -
mutate()changes the values of columns and creates new columns. -
relocate()changes the order of the columns.
-
- Groups of rows:
-
summarise()collapses a group into a single row.
-
Think of the parallels from Microsoft Excel.
The pipe
All of the dplyr functions take a data frame (or tibble) as the first argument. Rather than forcing the user to either save intermediate objects or nest functions, dplyr provides the %>% operator from magrittr. x %>% f(y) turns into f(x, y) so the result from one step is then “piped” into the next step. You can use the pipe to rewrite multiple operations that you can read left-to-right, top-to-bottom (reading the pipe operator as “then”).
Filter rows with filter()
filter() allows you to select a subset of rows in a data frame. Like all single verbs, the first argument is the tibble (or data frame). The second and subsequent arguments refer to variables within that data frame, selecting rows where the expression is TRUE.
For example, we can select all character with light skin color and brown eyes with:
Note the double equal to sign (==) below! Equivalent to MS Excel Data -> Filter
starwars %>% filter(skin_color == "light", eye_color == "brown")filter: removed 80 rows (92%), 7 rows remainingname <chr> | height <int> | mass <dbl> | hair_color <chr> | skin_color <chr> | eye_color <chr> | birth_year <dbl> | sex <chr> | gender <chr> | homeworld <chr> | |
|---|---|---|---|---|---|---|---|---|---|---|
| Leia Organa | 150 | 49 | brown | light | brown | 19 | female | feminine | Alderaan | |
| Biggs Darklighter | 183 | 84 | black | light | brown | 24 | male | masculine | Tatooine | |
| Padmé Amidala | 185 | 45 | brown | light | brown | 46 | female | feminine | Naboo | |
| Cordé | 157 | NA | brown | light | brown | NA | NA | NA | Naboo | |
| Dormé | 165 | NA | brown | light | brown | NA | female | feminine | Naboo | |
| Raymus Antilles | 188 | 79 | brown | light | brown | NA | male | masculine | Alderaan | |
| Poe Dameron | NA | NA | brown | light | brown | NA | male | masculine | NA |
Arrange rows with arrange()
arrange() works similarly to filter() except that instead of filtering or selecting rows, it reorders them. It takes a data frame, and a set of column names (or more complicated expressions) to order by. If you provide more than one column name, each additional column will be used to break ties in the values of preceding columns:
name <chr> | height <int> | mass <dbl> | hair_color <chr> | skin_color <chr> | eye_color <chr> | birth_year <dbl> | sex <chr> | gender <chr> | homeworld <chr> | |
|---|---|---|---|---|---|---|---|---|---|---|
| Yoda | 66 | 17.0 | white | green | brown | 896.0 | male | masculine | NA | |
| Ratts Tyerel | 79 | 15.0 | none | grey, blue | unknown | NA | male | masculine | Aleen Minor | |
| Wicket Systri Warrick | 88 | 20.0 | brown | brown | brown | 8.0 | male | masculine | Endor | |
| Dud Bolt | 94 | 45.0 | none | blue, grey | yellow | NA | male | masculine | Vulpter | |
| R2-D2 | 96 | 32.0 | NA | white, blue | red | 33.0 | none | masculine | Naboo | |
| R4-P17 | 96 | NA | none | silver, red | red, blue | NA | none | feminine | NA | |
| R5-D4 | 97 | 32.0 | NA | white, red | red | NA | none | masculine | Tatooine | |
| Sebulba | 112 | 40.0 | none | grey, red | orange | NA | male | masculine | Malastare | |
| Gasgano | 122 | NA | none | white, blue | black | NA | male | masculine | Troiken | |
| Watto | 137 | NA | black | blue, grey | yellow | NA | male | masculine | Toydaria |
Use desc() to order a column in descending order:
name <chr> | height <int> | mass <dbl> | hair_color <chr> | skin_color <chr> | eye_color <chr> | birth_year <dbl> | sex <chr> | gender <chr> | homeworld <chr> | |
|---|---|---|---|---|---|---|---|---|---|---|
| Yarael Poof | 264 | NA | none | white | yellow | NA | male | masculine | Quermia | |
| Tarfful | 234 | 136.0 | brown | brown | blue | NA | male | masculine | Kashyyyk | |
| Lama Su | 229 | 88.0 | none | grey | black | NA | male | masculine | Kamino | |
| Chewbacca | 228 | 112.0 | brown | unknown | blue | 200.0 | male | masculine | Kashyyyk | |
| Roos Tarpals | 224 | 82.0 | none | grey | orange | NA | male | masculine | Naboo | |
| Grievous | 216 | 159.0 | none | brown, white | green, yellow | NA | male | masculine | Kalee | |
| Taun We | 213 | NA | none | grey | black | NA | female | feminine | Kamino | |
| Rugor Nass | 206 | NA | none | green | orange | NA | male | masculine | Naboo | |
| Tion Medon | 206 | 80.0 | none | grey | black | NA | male | masculine | Utapau | |
| Darth Vader | 202 | 136.0 | none | white | yellow | 41.9 | male | masculine | Tatooine |
Choose rows using their position with slice()
slice() lets you index rows by their (integer) locations. It allows you to select, remove, and duplicate rows.
This is an important step in Prediction, Modelling and Machine Learning.
We can get characters from row numbers 5 through 10.
starwars %>% slice(5:10)slice: removed 81 rows (93%), 6 rows remainingname <chr> | height <int> | mass <dbl> | hair_color <chr> | skin_color <chr> | eye_color <chr> | birth_year <dbl> | sex <chr> | gender <chr> | homeworld <chr> | |
|---|---|---|---|---|---|---|---|---|---|---|
| Leia Organa | 150 | 49 | brown | light | brown | 19 | female | feminine | Alderaan | |
| Owen Lars | 178 | 120 | brown, grey | light | blue | 52 | male | masculine | Tatooine | |
| Beru Whitesun Lars | 165 | 75 | brown | light | blue | 47 | female | feminine | Tatooine | |
| R5-D4 | 97 | 32 | NA | white, red | red | NA | none | masculine | Tatooine | |
| Biggs Darklighter | 183 | 84 | black | light | brown | 24 | male | masculine | Tatooine | |
| Obi-Wan Kenobi | 182 | 77 | auburn, white | fair | blue-gray | 57 | male | masculine | Stewjon |
It is accompanied by a number of helpers for common use cases:
-
slice_head()andslice_tail()select the first or last rows.
starwars %>% slice_head(n = 3)slice_head: removed 84 rows (97%), 3 rows remainingname <chr> | height <int> | mass <dbl> | hair_color <chr> | skin_color <chr> | eye_color <chr> | birth_year <dbl> | sex <chr> | gender <chr> | homeworld <chr> | |
|---|---|---|---|---|---|---|---|---|---|---|
| Luke Skywalker | 172 | 77 | blond | fair | blue | 19 | male | masculine | Tatooine | |
| C-3PO | 167 | 75 | NA | gold | yellow | 112 | none | masculine | Tatooine | |
| R2-D2 | 96 | 32 | NA | white, blue | red | 33 | none | masculine | Naboo |
-
slice_sample()randomly selects rows. Use the option prop to choose a certain proportion of the cases.
starwars %>% slice_sample(n = 5)slice_sample: removed 82 rows (94%), 5 rows remainingname <chr> | height <int> | mass <dbl> | hair_color <chr> | skin_color <chr> | eye_color <chr> | birth_year <dbl> | sex <chr> | gender <chr> | homeworld <chr> | |
|---|---|---|---|---|---|---|---|---|---|---|
| Lando Calrissian | 177 | 79 | black | dark | brown | 31 | male | masculine | Socorro | |
| Rugor Nass | 206 | NA | none | green | orange | NA | male | masculine | Naboo | |
| Jar Jar Binks | 196 | 66 | none | orange | orange | 52 | male | masculine | Naboo | |
| Mace Windu | 188 | 84 | none | dark | brown | 72 | male | masculine | Haruun Kal | |
| Biggs Darklighter | 183 | 84 | black | light | brown | 24 | male | masculine | Tatooine |
starwars %>% slice_sample(prop = 0.1)slice_sample: removed 79 rows (91%), 8 rows remainingname <chr> | height <int> | mass <dbl> | hair_color <chr> | skin_color <chr> | eye_color <chr> | birth_year <dbl> | sex <chr> | gender <chr> | homeworld <chr> | |
|---|---|---|---|---|---|---|---|---|---|---|
| Captain Phasma | NA | NA | none | none | unknown | NA | female | feminine | NA | |
| Leia Organa | 150 | 49 | brown | light | brown | 19 | female | feminine | Alderaan | |
| Jar Jar Binks | 196 | 66 | none | orange | orange | 52 | male | masculine | Naboo | |
| Dud Bolt | 94 | 45 | none | blue, grey | yellow | NA | male | masculine | Vulpter | |
| Wilhuff Tarkin | 180 | NA | auburn, grey | fair | blue | 64 | male | masculine | Eriadu | |
| Bib Fortuna | 180 | NA | none | pale | pink | NA | male | masculine | Ryloth | |
| Qui-Gon Jinn | 193 | 89 | brown | fair | blue | 92 | male | masculine | NA | |
| Dexter Jettster | 198 | 102 | none | brown | yellow | NA | male | masculine | Ojom |
Use replace = TRUE to perform a bootstrap sample. If needed, you can weight the sample with the weight argument.
Bootstrap samplesare a special statistical sampling method. Counterintuitive perhaps, since you sample with replacement. Should remind you of your high school Permutation and Combination class, with all those urn models and so on. If you remember.
-
slice_min()andslice_max()select rows with highest or lowest values of a variable. Note that we first must choose only the values which are not NA.
filter: removed 6 rows (7%), 81 rows remaining
slice_min: removed 78 rows (96%), 3 rows remainingname <chr> | height <int> | mass <dbl> | hair_color <chr> | skin_color <chr> | eye_color <chr> | birth_year <dbl> | sex <chr> | gender <chr> | homeworld <chr> | |
|---|---|---|---|---|---|---|---|---|---|---|
| Yoda | 66 | 17 | white | green | brown | 896 | male | masculine | NA | |
| Ratts Tyerel | 79 | 15 | none | grey, blue | unknown | NA | male | masculine | Aleen Minor | |
| Wicket Systri Warrick | 88 | 20 | brown | brown | brown | 8 | male | masculine | Endor |
Select columns with select()
Often you work with large datasets with many columns but only a few are actually of interest to you. select() allows you to rapidly zoom in on a useful subset using operations that usually only work on numeric variable positions:
# Select columns by name
starwars %>% select(hair_color, skin_color, eye_color)select: dropped 11 variables (name, height, mass, birth_year, sex, …)hair_color <chr> | skin_color <chr> | eye_color <chr> | ||
|---|---|---|---|---|
| blond | fair | blue | ||
| NA | gold | yellow | ||
| NA | white, blue | red | ||
| none | white | yellow | ||
| brown | light | brown | ||
| brown, grey | light | blue | ||
| brown | light | blue | ||
| NA | white, red | red | ||
| black | light | brown | ||
| auburn, white | fair | blue-gray |
# Select all columns between hair_color and eye_color (inclusive)
starwars %>% select(hair_color:eye_color)select: dropped 11 variables (name, height, mass, birth_year, sex, …)hair_color <chr> | skin_color <chr> | eye_color <chr> | ||
|---|---|---|---|---|
| blond | fair | blue | ||
| NA | gold | yellow | ||
| NA | white, blue | red | ||
| none | white | yellow | ||
| brown | light | brown | ||
| brown, grey | light | blue | ||
| brown | light | blue | ||
| NA | white, red | red | ||
| black | light | brown | ||
| auburn, white | fair | blue-gray |
# Select all columns except those from hair_color to eye_color (inclusive)
starwars %>% select(!(hair_color:eye_color))select: dropped 3 variables (hair_color, skin_color, eye_color)name <chr> | height <int> | mass <dbl> | birth_year <dbl> | sex <chr> | gender <chr> | homeworld <chr> | species <chr> | films <list> | vehicles <list> | |
|---|---|---|---|---|---|---|---|---|---|---|
| Luke Skywalker | 172 | 77.0 | 19.0 | male | masculine | Tatooine | Human | <chr [5]> | <chr [2]> | |
| C-3PO | 167 | 75.0 | 112.0 | none | masculine | Tatooine | Droid | <chr [6]> | <chr [0]> | |
| R2-D2 | 96 | 32.0 | 33.0 | none | masculine | Naboo | Droid | <chr [7]> | <chr [0]> | |
| Darth Vader | 202 | 136.0 | 41.9 | male | masculine | Tatooine | Human | <chr [4]> | <chr [0]> | |
| Leia Organa | 150 | 49.0 | 19.0 | female | feminine | Alderaan | Human | <chr [5]> | <chr [1]> | |
| Owen Lars | 178 | 120.0 | 52.0 | male | masculine | Tatooine | Human | <chr [3]> | <chr [0]> | |
| Beru Whitesun Lars | 165 | 75.0 | 47.0 | female | feminine | Tatooine | Human | <chr [3]> | <chr [0]> | |
| R5-D4 | 97 | 32.0 | NA | none | masculine | Tatooine | Droid | <chr [1]> | <chr [0]> | |
| Biggs Darklighter | 183 | 84.0 | 24.0 | male | masculine | Tatooine | Human | <chr [1]> | <chr [0]> | |
| Obi-Wan Kenobi | 182 | 77.0 | 57.0 | male | masculine | Stewjon | Human | <chr [6]> | <chr [1]> |
select: dropped 11 variables (name, height, mass, birth_year, sex, …)hair_color <chr> | skin_color <chr> | eye_color <chr> | ||
|---|---|---|---|---|
| blond | fair | blue | ||
| NA | gold | yellow | ||
| NA | white, blue | red | ||
| none | white | yellow | ||
| brown | light | brown | ||
| brown, grey | light | blue | ||
| brown | light | blue | ||
| NA | white, red | red | ||
| black | light | brown | ||
| auburn, white | fair | blue-gray |
There are a number of helper functions you can use within select(), like starts_with(), ends_with(), matches() and contains(). These let you quickly match larger blocks of variables that meet some criterion. See ?select for more details.
You can rename variables with select() by using named arguments:
starwars %>% select(home_world = homeworld)select: renamed one variable (home_world) and dropped 13 variableshome_world <chr> | ||||
|---|---|---|---|---|
| Tatooine | ||||
| Tatooine | ||||
| Naboo | ||||
| Tatooine | ||||
| Alderaan | ||||
| Tatooine | ||||
| Tatooine | ||||
| Tatooine | ||||
| Tatooine | ||||
| Stewjon |
But because select() drops all the variables not explicitly mentioned, it’s not that useful. Instead, use rename():
starwars %>% rename(home_world = homeworld)rename: renamed one variable (home_world)name <chr> | height <int> | mass <dbl> | hair_color <chr> | skin_color <chr> | eye_color <chr> | birth_year <dbl> | sex <chr> | gender <chr> | home_world <chr> | |
|---|---|---|---|---|---|---|---|---|---|---|
| Luke Skywalker | 172 | 77.0 | blond | fair | blue | 19.0 | male | masculine | Tatooine | |
| C-3PO | 167 | 75.0 | NA | gold | yellow | 112.0 | none | masculine | Tatooine | |
| R2-D2 | 96 | 32.0 | NA | white, blue | red | 33.0 | none | masculine | Naboo | |
| Darth Vader | 202 | 136.0 | none | white | yellow | 41.9 | male | masculine | Tatooine | |
| Leia Organa | 150 | 49.0 | brown | light | brown | 19.0 | female | feminine | Alderaan | |
| Owen Lars | 178 | 120.0 | brown, grey | light | blue | 52.0 | male | masculine | Tatooine | |
| Beru Whitesun Lars | 165 | 75.0 | brown | light | blue | 47.0 | female | feminine | Tatooine | |
| R5-D4 | 97 | 32.0 | NA | white, red | red | NA | none | masculine | Tatooine | |
| Biggs Darklighter | 183 | 84.0 | black | light | brown | 24.0 | male | masculine | Tatooine | |
| Obi-Wan Kenobi | 182 | 77.0 | auburn, white | fair | blue-gray | 57.0 | male | masculine | Stewjon |
Add new columns with mutate()
Besides selecting sets of existing columns, it’s often useful to add new columns that are functions of existing columns. This is the job of mutate():
starwars %>% mutate(height_m = height / 100)mutate: new variable 'height_m' (double) with 46 unique values and 7% NAname <chr> | height <int> | mass <dbl> | hair_color <chr> | skin_color <chr> | eye_color <chr> | birth_year <dbl> | sex <chr> | gender <chr> | homeworld <chr> | |
|---|---|---|---|---|---|---|---|---|---|---|
| Luke Skywalker | 172 | 77.0 | blond | fair | blue | 19.0 | male | masculine | Tatooine | |
| C-3PO | 167 | 75.0 | NA | gold | yellow | 112.0 | none | masculine | Tatooine | |
| R2-D2 | 96 | 32.0 | NA | white, blue | red | 33.0 | none | masculine | Naboo | |
| Darth Vader | 202 | 136.0 | none | white | yellow | 41.9 | male | masculine | Tatooine | |
| Leia Organa | 150 | 49.0 | brown | light | brown | 19.0 | female | feminine | Alderaan | |
| Owen Lars | 178 | 120.0 | brown, grey | light | blue | 52.0 | male | masculine | Tatooine | |
| Beru Whitesun Lars | 165 | 75.0 | brown | light | blue | 47.0 | female | feminine | Tatooine | |
| R5-D4 | 97 | 32.0 | NA | white, red | red | NA | none | masculine | Tatooine | |
| Biggs Darklighter | 183 | 84.0 | black | light | brown | 24.0 | male | masculine | Tatooine | |
| Obi-Wan Kenobi | 182 | 77.0 | auburn, white | fair | blue-gray | 57.0 | male | masculine | Stewjon |
We can’t see the height in meters we just calculated, but we can fix that using a select command.
starwars %>%
mutate(height_m = height / 100) %>%
select(height_m, height, everything())mutate: new variable 'height_m' (double) with 46 unique values and 7% NA
select: columns reordered (height_m, height, name, mass, hair_color, …)height_m <dbl> | height <int> | name <chr> | mass <dbl> | hair_color <chr> | skin_color <chr> | eye_color <chr> | birth_year <dbl> | sex <chr> | gender <chr> | |
|---|---|---|---|---|---|---|---|---|---|---|
| 1.72 | 172 | Luke Skywalker | 77.0 | blond | fair | blue | 19.0 | male | masculine | |
| 1.67 | 167 | C-3PO | 75.0 | NA | gold | yellow | 112.0 | none | masculine | |
| 0.96 | 96 | R2-D2 | 32.0 | NA | white, blue | red | 33.0 | none | masculine | |
| 2.02 | 202 | Darth Vader | 136.0 | none | white | yellow | 41.9 | male | masculine | |
| 1.50 | 150 | Leia Organa | 49.0 | brown | light | brown | 19.0 | female | feminine | |
| 1.78 | 178 | Owen Lars | 120.0 | brown, grey | light | blue | 52.0 | male | masculine | |
| 1.65 | 165 | Beru Whitesun Lars | 75.0 | brown | light | blue | 47.0 | female | feminine | |
| 0.97 | 97 | R5-D4 | 32.0 | NA | white, red | red | NA | none | masculine | |
| 1.83 | 183 | Biggs Darklighter | 84.0 | black | light | brown | 24.0 | male | masculine | |
| 1.82 | 182 | Obi-Wan Kenobi | 77.0 | auburn, white | fair | blue-gray | 57.0 | male | masculine |
dplyr::mutate() is similar to the base transform(), but allows you to refer to columns that you’ve just created:
starwars %>%
mutate(
height_m = height / 100,
BMI = mass / (height_m^2)
) %>%
select(BMI, everything())mutate: new variable 'height_m' (double) with 46 unique values and 7% NA
new variable 'BMI' (double) with 59 unique values and 32% NA
select: columns reordered (BMI, name, height, mass, hair_color, …)BMI <dbl> | name <chr> | height <int> | mass <dbl> | hair_color <chr> | skin_color <chr> | eye_color <chr> | birth_year <dbl> | sex <chr> | gender <chr> | |
|---|---|---|---|---|---|---|---|---|---|---|
| 26.02758 | Luke Skywalker | 172 | 77.0 | blond | fair | blue | 19.0 | male | masculine | |
| 26.89232 | C-3PO | 167 | 75.0 | NA | gold | yellow | 112.0 | none | masculine | |
| 34.72222 | R2-D2 | 96 | 32.0 | NA | white, blue | red | 33.0 | none | masculine | |
| 33.33007 | Darth Vader | 202 | 136.0 | none | white | yellow | 41.9 | male | masculine | |
| 21.77778 | Leia Organa | 150 | 49.0 | brown | light | brown | 19.0 | female | feminine | |
| 37.87401 | Owen Lars | 178 | 120.0 | brown, grey | light | blue | 52.0 | male | masculine | |
| 27.54821 | Beru Whitesun Lars | 165 | 75.0 | brown | light | blue | 47.0 | female | feminine | |
| 34.00999 | R5-D4 | 97 | 32.0 | NA | white, red | red | NA | none | masculine | |
| 25.08286 | Biggs Darklighter | 183 | 84.0 | black | light | brown | 24.0 | male | masculine | |
| 23.24598 | Obi-Wan Kenobi | 182 | 77.0 | auburn, white | fair | blue-gray | 57.0 | male | masculine |
If you only want to keep the new variables, use transmute():
starwars %>%
transmute(
height_m = height / 100,
BMI = mass / (height_m^2)
)transmute: dropped 14 variables (name, height, mass, hair_color, skin_color, …)
transmute: dropped 14 variables (name, height, mass, hair_color, skin_color, …)
new variable 'height_m' (double) with 46 unique values and 7% NA
new variable 'BMI' (double) with 59 unique values and 32% NAheight_m <dbl> | BMI <dbl> | |||
|---|---|---|---|---|
| 1.72 | 26.02758 | |||
| 1.67 | 26.89232 | |||
| 0.96 | 34.72222 | |||
| 2.02 | 33.33007 | |||
| 1.50 | 21.77778 | |||
| 1.78 | 37.87401 | |||
| 1.65 | 27.54821 | |||
| 0.97 | 34.00999 | |||
| 1.83 | 25.08286 | |||
| 1.82 | 23.24598 |
Change column order with relocate()
Use a similar syntax as select() to move blocks of columns at once
starwars %>% relocate(sex:homeworld, .before = height)relocate: columns reordered (name, sex, gender, homeworld, height, …)name <chr> | sex <chr> | gender <chr> | homeworld <chr> | height <int> | mass <dbl> | hair_color <chr> | skin_color <chr> | eye_color <chr> | birth_year <dbl> | |
|---|---|---|---|---|---|---|---|---|---|---|
| Luke Skywalker | male | masculine | Tatooine | 172 | 77.0 | blond | fair | blue | 19.0 | |
| C-3PO | none | masculine | Tatooine | 167 | 75.0 | NA | gold | yellow | 112.0 | |
| R2-D2 | none | masculine | Naboo | 96 | 32.0 | NA | white, blue | red | 33.0 | |
| Darth Vader | male | masculine | Tatooine | 202 | 136.0 | none | white | yellow | 41.9 | |
| Leia Organa | female | feminine | Alderaan | 150 | 49.0 | brown | light | brown | 19.0 | |
| Owen Lars | male | masculine | Tatooine | 178 | 120.0 | brown, grey | light | blue | 52.0 | |
| Beru Whitesun Lars | female | feminine | Tatooine | 165 | 75.0 | brown | light | blue | 47.0 | |
| R5-D4 | none | masculine | Tatooine | 97 | 32.0 | NA | white, red | red | NA | |
| Biggs Darklighter | male | masculine | Tatooine | 183 | 84.0 | black | light | brown | 24.0 | |
| Obi-Wan Kenobi | male | masculine | Stewjon | 182 | 77.0 | auburn, white | fair | blue-gray | 57.0 |
Summarise values with summarise()
The last verb is summarise(). It collapses a data frame to a single row.
summarise: now one row and one column, ungroupedmean_height <dbl> | ||||
|---|---|---|---|---|
| 174.6049 |
It’s not that useful until we learn the group_by() verb below.
Commonalities
You may have noticed that the syntax and function of all these verbs are very similar:
The first argument is a data frame.
The subsequent arguments describe what to do with the data frame. You can refer to columns in the data frame directly without using
$.The result is a new data frame
Together these properties make it easy to chain together multiple simple steps to achieve a complex result.
These five functions provide the basis of a language of data manipulation. At the most basic level, you can only alter a tidy data frame in five useful ways: you can reorder the rows (arrange()), pick observations and variables of interest (filter() and select()), add new variables that are functions of existing variables (mutate()), or collapse many values to a summary (summarise()).
Combining functions with %>%
The dplyr API is functional in the sense that function calls don’t have side-effects. You must always save their results. This doesn’t lead to particularly elegant code, especially if you want to do many operations at once. You either have to do it step-by-step:
Or if you don’t want to name the intermediate results, you need to wrap the function calls inside each other:
summarise(
select(
group_by(starwars, species, sex),
height, mass
),
height = mean(height, na.rm = TRUE),
mass = mean(mass, na.rm = TRUE)
)group_by: 2 grouping variables (species, sex)
Adding missing grouping variables: `species`, `sex`
select: dropped 10 variables (name, hair_color, skin_color, eye_color, birth_year, …)
summarise: now 41 rows and 4 columns, one group variable remaining (species)species <chr> | sex <chr> | height <dbl> | mass <dbl> | |
|---|---|---|---|---|
| Aleena | male | 79.0000 | 15.00000 | |
| Besalisk | male | 198.0000 | 102.00000 | |
| Cerean | male | 198.0000 | 82.00000 | |
| Chagrian | male | 196.0000 | NaN | |
| Clawdite | female | 168.0000 | 55.00000 | |
| Droid | none | 131.2000 | 69.75000 | |
| Dug | male | 112.0000 | 40.00000 | |
| Ewok | male | 88.0000 | 20.00000 | |
| Geonosian | male | 183.0000 | 80.00000 | |
| Gungan | male | 208.6667 | 74.00000 |
This is difficult to read because the order of the operations is from inside to out. Thus, the arguments are a long way away from the function. To get around this problem, dplyr provides the %>% operator from magrittr. x %>% f(y) turns into f(x, y) so you can use it to rewrite multiple operations that you can read left-to-right, top-to-bottom (reading the pipe operator as “then”):
starwars %>%
group_by(species, sex) %>%
summarise(
mean_height = mean(height, na.rm = TRUE),
mean_mass = mean(mass, na.rm = TRUE)
)group_by: 2 grouping variables (species, sex)
summarise: now 41 rows and 4 columns, one group variable remaining (species)species <chr> | sex <chr> | mean_height <dbl> | mean_mass <dbl> | |
|---|---|---|---|---|
| Aleena | male | 79.0000 | 15.00000 | |
| Besalisk | male | 198.0000 | 102.00000 | |
| Cerean | male | 198.0000 | 82.00000 | |
| Chagrian | male | 196.0000 | NaN | |
| Clawdite | female | 168.0000 | 55.00000 | |
| Droid | none | 131.2000 | 69.75000 | |
| Dug | male | 112.0000 | 40.00000 | |
| Ewok | male | 88.0000 | 20.00000 | |
| Geonosian | male | 183.0000 | 80.00000 | |
| Gungan | male | 208.6667 | 74.00000 |
Patterns of operations
The dplyr verbs can be classified by the type of operations they accomplish (we sometimes speak of their semantics, i.e., their meaning). It’s helpful to have a good grasp of the difference between select and mutate operations.
Selecting operations
One of the appealing features of dplyr is that you can refer to columns from the tibble as if they were regular variables. However, the syntactic uniformity of referring to bare column names hides semantical differences across the verbs. A column symbol supplied to select() does not have the same meaning as the same symbol supplied to mutate().
Selecting operations expect column names and positions. Hence, when you call select() with bare variable names, they actually represent their own positions in the tibble. The following calls are completely equivalent from dplyr’s point of view:
# `name` represents the integer 1
select(starwars, name)select: dropped 13 variables (height, mass, hair_color, skin_color, eye_color,
…)name <chr> | ||||
|---|---|---|---|---|
| Luke Skywalker | ||||
| C-3PO | ||||
| R2-D2 | ||||
| Darth Vader | ||||
| Leia Organa | ||||
| Owen Lars | ||||
| Beru Whitesun Lars | ||||
| R5-D4 | ||||
| Biggs Darklighter | ||||
| Obi-Wan Kenobi |
select(starwars, 1)select: dropped 13 variables (height, mass, hair_color, skin_color, eye_color,
…)name <chr> | ||||
|---|---|---|---|---|
| Luke Skywalker | ||||
| C-3PO | ||||
| R2-D2 | ||||
| Darth Vader | ||||
| Leia Organa | ||||
| Owen Lars | ||||
| Beru Whitesun Lars | ||||
| R5-D4 | ||||
| Biggs Darklighter | ||||
| Obi-Wan Kenobi |
By the same token, this means that you cannot refer to variables from the surrounding context if they have the same name as one of the columns. In the following example, height still represents 2, not 5:
height <- 5
select(starwars, height)select: dropped 13 variables (name, mass, hair_color, skin_color, eye_color, …)height <int> | ||||
|---|---|---|---|---|
| 172 | ||||
| 167 | ||||
| 96 | ||||
| 202 | ||||
| 150 | ||||
| 178 | ||||
| 165 | ||||
| 97 | ||||
| 183 | ||||
| 182 |
One useful subtlety is that this only applies to bare names and to selecting calls like c(height, mass) or height:mass. In all other cases, the columns of the data frame are not put in scope. This allows you to refer to contextual variables in selection helpers:
name <- "color"
select(starwars, ends_with(name))select: dropped 11 variables (name, height, mass, birth_year, sex, …)hair_color <chr> | skin_color <chr> | eye_color <chr> | ||
|---|---|---|---|---|
| blond | fair | blue | ||
| NA | gold | yellow | ||
| NA | white, blue | red | ||
| none | white | yellow | ||
| brown | light | brown | ||
| brown, grey | light | blue | ||
| brown | light | blue | ||
| NA | white, red | red | ||
| black | light | brown | ||
| auburn, white | fair | blue-gray |
These semantics are usually intuitive. But note the subtle difference:
name <- 5
select(starwars, name, identity(name))select: dropped 12 variables (height, mass, hair_color, eye_color, birth_year,
…)name <chr> | skin_color <chr> | |||
|---|---|---|---|---|
| Luke Skywalker | fair | |||
| C-3PO | gold | |||
| R2-D2 | white, blue | |||
| Darth Vader | white | |||
| Leia Organa | light | |||
| Owen Lars | light | |||
| Beru Whitesun Lars | light | |||
| R5-D4 | white, red | |||
| Biggs Darklighter | light | |||
| Obi-Wan Kenobi | fair |
In the first argument, name represents its own position 1. In the second argument, name is evaluated in the surrounding context and represents the fifth column.
Mutating operations
Mutate semantics are quite different from selection semantics. Whereas select() expects column names or positions, mutate() expects column vectors. We will set up a smaller tibble to use for our examples.
df <- starwars %>% select(name, height, mass)select: dropped 11 variables (hair_color, skin_color, eye_color, birth_year,
sex, …)When we use select(), the bare column names stand for their own positions in the tibble. For mutate() on the other hand, column symbols represent the actual column vectors stored in the tibble. Consider what happens if we give a string or a number to mutate():
mutate(df, "height", 2)mutate: new variable '"height"' (character) with one unique value and 0% NA
new variable '2' (double) with one unique value and 0% NAname <chr> | height <int> | mass <dbl> | "height" <chr> | 2 <dbl> |
|---|---|---|---|---|
| Luke Skywalker | 172 | 77.0 | height | 2 |
| C-3PO | 167 | 75.0 | height | 2 |
| R2-D2 | 96 | 32.0 | height | 2 |
| Darth Vader | 202 | 136.0 | height | 2 |
| Leia Organa | 150 | 49.0 | height | 2 |
| Owen Lars | 178 | 120.0 | height | 2 |
| Beru Whitesun Lars | 165 | 75.0 | height | 2 |
| R5-D4 | 97 | 32.0 | height | 2 |
| Biggs Darklighter | 183 | 84.0 | height | 2 |
| Obi-Wan Kenobi | 182 | 77.0 | height | 2 |
mutate() gets length-1 vectors that it interprets as new columns in the data frame. These vectors are recycled so they match the number of rows. That’s why it doesn’t make sense to supply expressions like "height" + 10 to mutate(). This amounts to adding 10 to a string! The correct expression is:
mutate(df, height + 10)mutate: new variable 'height + 10' (double) with 46 unique values and 7% NAname <chr> | height <int> | mass <dbl> | height + 10 <dbl> | |
|---|---|---|---|---|
| Luke Skywalker | 172 | 77.0 | 182 | |
| C-3PO | 167 | 75.0 | 177 | |
| R2-D2 | 96 | 32.0 | 106 | |
| Darth Vader | 202 | 136.0 | 212 | |
| Leia Organa | 150 | 49.0 | 160 | |
| Owen Lars | 178 | 120.0 | 188 | |
| Beru Whitesun Lars | 165 | 75.0 | 175 | |
| R5-D4 | 97 | 32.0 | 107 | |
| Biggs Darklighter | 183 | 84.0 | 193 | |
| Obi-Wan Kenobi | 182 | 77.0 | 192 |
In the same way, you can unquote values from the context if these values represent a valid column. They must be either length 1 (they then get recycled) or have the same length as the number of rows. In the following example we create a new vector that we add to the data frame:
mutate: new variable 'new' (integer) with 87 unique values and 0% NAname <chr> | height <int> | mass <dbl> | new <int> | |
|---|---|---|---|---|
| Luke Skywalker | 172 | 77.0 | 1 | |
| C-3PO | 167 | 75.0 | 2 | |
| R2-D2 | 96 | 32.0 | 3 | |
| Darth Vader | 202 | 136.0 | 4 | |
| Leia Organa | 150 | 49.0 | 5 | |
| Owen Lars | 178 | 120.0 | 6 | |
| Beru Whitesun Lars | 165 | 75.0 | 7 | |
| R5-D4 | 97 | 32.0 | 8 | |
| Biggs Darklighter | 183 | 84.0 | 9 | |
| Obi-Wan Kenobi | 182 | 77.0 | 10 |
A case in point is group_by(). While you might think it has select semantics, it actually has mutate semantics. This is quite handy as it allows to group by a modified column:
group_by(starwars, sex)group_by: one grouping variable (sex)name <chr> | height <int> | mass <dbl> | hair_color <chr> | skin_color <chr> | eye_color <chr> | birth_year <dbl> | sex <chr> | gender <chr> | homeworld <chr> | |
|---|---|---|---|---|---|---|---|---|---|---|
| Luke Skywalker | 172 | 77.0 | blond | fair | blue | 19.0 | male | masculine | Tatooine | |
| C-3PO | 167 | 75.0 | NA | gold | yellow | 112.0 | none | masculine | Tatooine | |
| R2-D2 | 96 | 32.0 | NA | white, blue | red | 33.0 | none | masculine | Naboo | |
| Darth Vader | 202 | 136.0 | none | white | yellow | 41.9 | male | masculine | Tatooine | |
| Leia Organa | 150 | 49.0 | brown | light | brown | 19.0 | female | feminine | Alderaan | |
| Owen Lars | 178 | 120.0 | brown, grey | light | blue | 52.0 | male | masculine | Tatooine | |
| Beru Whitesun Lars | 165 | 75.0 | brown | light | blue | 47.0 | female | feminine | Tatooine | |
| R5-D4 | 97 | 32.0 | NA | white, red | red | NA | none | masculine | Tatooine | |
| Biggs Darklighter | 183 | 84.0 | black | light | brown | 24.0 | male | masculine | Tatooine | |
| Obi-Wan Kenobi | 182 | 77.0 | auburn, white | fair | blue-gray | 57.0 | male | masculine | Stewjon |
group_by(starwars, sex = as.factor(sex))group_by: one grouping variable (sex)name <chr> | height <int> | mass <dbl> | hair_color <chr> | skin_color <chr> | eye_color <chr> | birth_year <dbl> | sex <fct> | gender <chr> | homeworld <chr> | |
|---|---|---|---|---|---|---|---|---|---|---|
| Luke Skywalker | 172 | 77.0 | blond | fair | blue | 19.0 | male | masculine | Tatooine | |
| C-3PO | 167 | 75.0 | NA | gold | yellow | 112.0 | none | masculine | Tatooine | |
| R2-D2 | 96 | 32.0 | NA | white, blue | red | 33.0 | none | masculine | Naboo | |
| Darth Vader | 202 | 136.0 | none | white | yellow | 41.9 | male | masculine | Tatooine | |
| Leia Organa | 150 | 49.0 | brown | light | brown | 19.0 | female | feminine | Alderaan | |
| Owen Lars | 178 | 120.0 | brown, grey | light | blue | 52.0 | male | masculine | Tatooine | |
| Beru Whitesun Lars | 165 | 75.0 | brown | light | blue | 47.0 | female | feminine | Tatooine | |
| R5-D4 | 97 | 32.0 | NA | white, red | red | NA | none | masculine | Tatooine | |
| Biggs Darklighter | 183 | 84.0 | black | light | brown | 24.0 | male | masculine | Tatooine | |
| Obi-Wan Kenobi | 182 | 77.0 | auburn, white | fair | blue-gray | 57.0 | male | masculine | Stewjon |
group_by(starwars, height_binned = cut(height, 3))group_by: one grouping variable (height_binned)name <chr> | height <int> | mass <dbl> | hair_color <chr> | skin_color <chr> | eye_color <chr> | birth_year <dbl> | sex <chr> | gender <chr> | homeworld <chr> | |
|---|---|---|---|---|---|---|---|---|---|---|
| Luke Skywalker | 172 | 77.0 | blond | fair | blue | 19.0 | male | masculine | Tatooine | |
| C-3PO | 167 | 75.0 | NA | gold | yellow | 112.0 | none | masculine | Tatooine | |
| R2-D2 | 96 | 32.0 | NA | white, blue | red | 33.0 | none | masculine | Naboo | |
| Darth Vader | 202 | 136.0 | none | white | yellow | 41.9 | male | masculine | Tatooine | |
| Leia Organa | 150 | 49.0 | brown | light | brown | 19.0 | female | feminine | Alderaan | |
| Owen Lars | 178 | 120.0 | brown, grey | light | blue | 52.0 | male | masculine | Tatooine | |
| Beru Whitesun Lars | 165 | 75.0 | brown | light | blue | 47.0 | female | feminine | Tatooine | |
| R5-D4 | 97 | 32.0 | NA | white, red | red | NA | none | masculine | Tatooine | |
| Biggs Darklighter | 183 | 84.0 | black | light | brown | 24.0 | male | masculine | Tatooine | |
| Obi-Wan Kenobi | 182 | 77.0 | auburn, white | fair | blue-gray | 57.0 | male | masculine | Stewjon |
This is why you can’t supply a column name to group_by(). This amounts to creating a new column containing the string recycled to the number of rows:
group_by(df, "month")group_by: one grouping variable ("month")name <chr> | height <int> | mass <dbl> | "month" <chr> | |
|---|---|---|---|---|
| Luke Skywalker | 172 | 77.0 | month | |
| C-3PO | 167 | 75.0 | month | |
| R2-D2 | 96 | 32.0 | month | |
| Darth Vader | 202 | 136.0 | month | |
| Leia Organa | 150 | 49.0 | month | |
| Owen Lars | 178 | 120.0 | month | |
| Beru Whitesun Lars | 165 | 75.0 | month | |
| R5-D4 | 97 | 32.0 | month | |
| Biggs Darklighter | 183 | 84.0 | month | |
| Obi-Wan Kenobi | 182 | 77.0 | month |
Two table verbs
Sometimes our data is spread across more than one table. Often these tables are linked by some common, or common-looking, variable columns. dplyr allows us to work with such data that is spread over more than one table. More information is available here: Two Table Verbs in dplyr
The operations/verbs used to manipulate two-table verbs are:
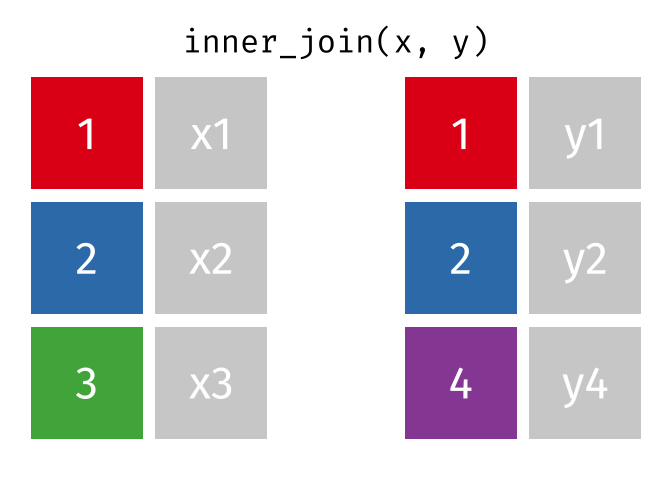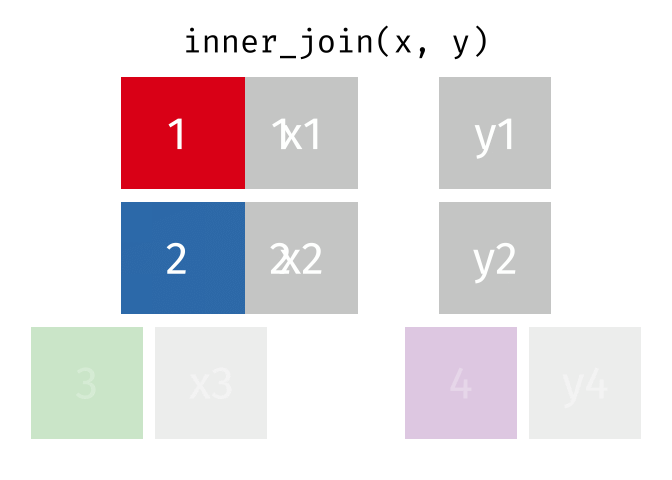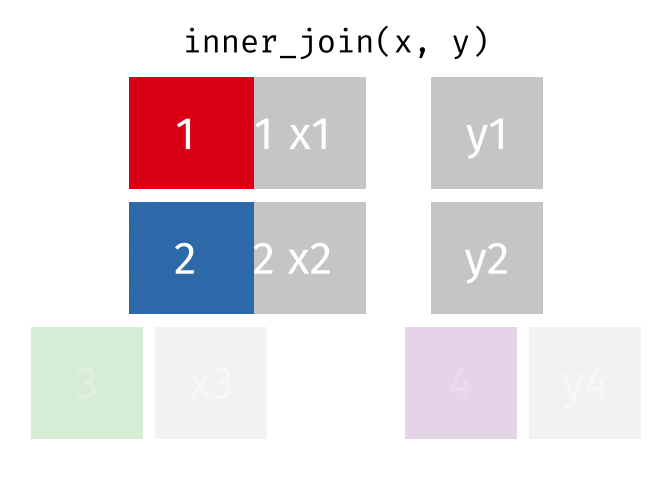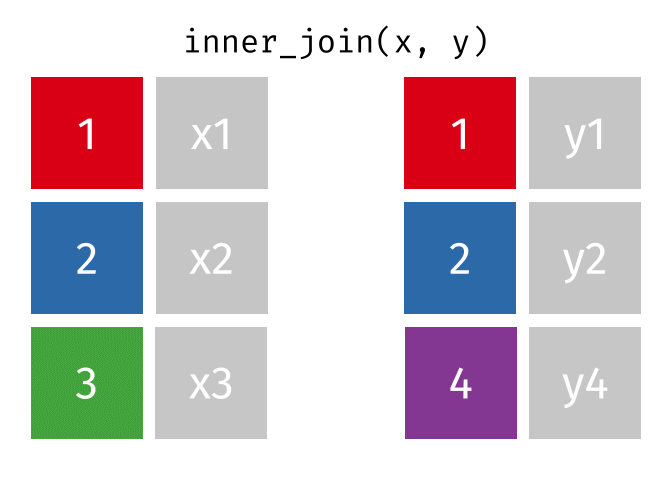
- Mutating joins, which add new variables to one table from matching rows in another.
inner_join()
left_join()
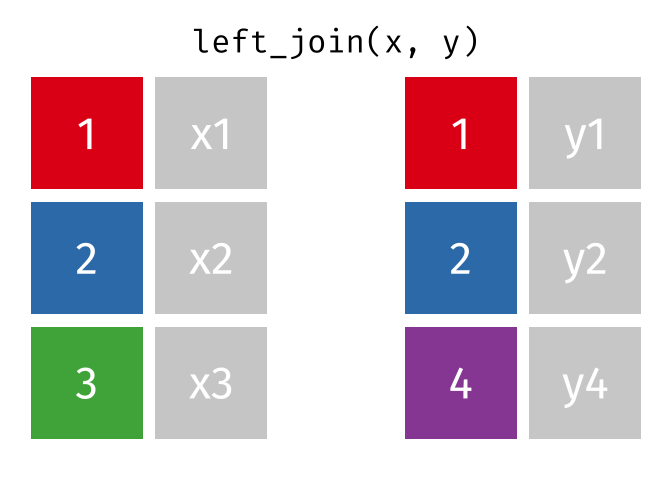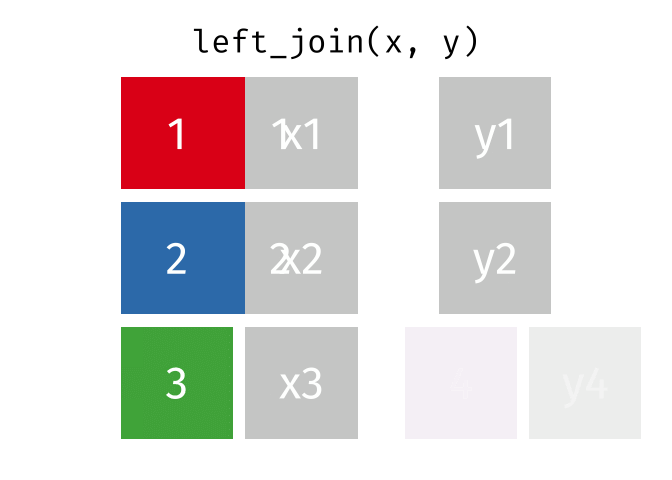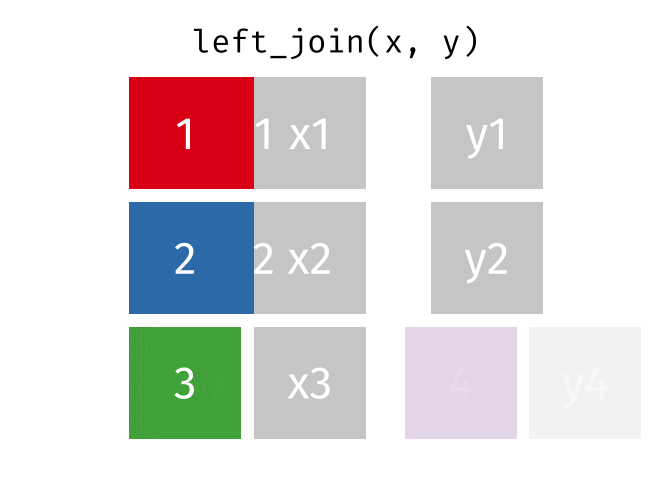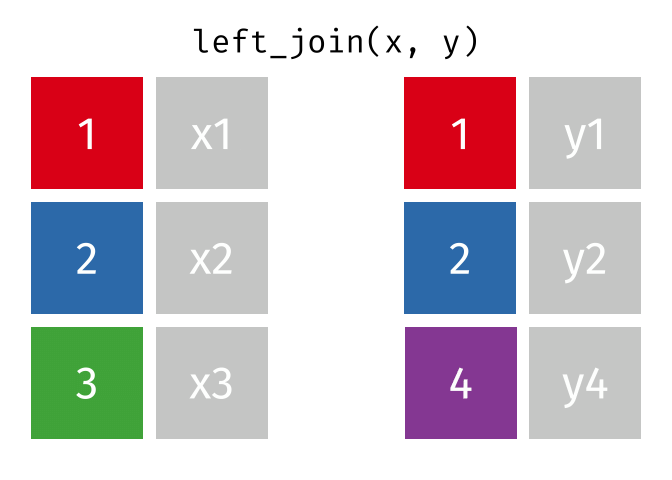
right_join()

full_join()

- Filtering joins, which filter observations from one table based on whether or not they match an observation in the other table.
-
semi_join(x, y)keeps all observations in x that have a match in y.
-

-
anti_join(x, y)drops all observations in x that have a match in

-
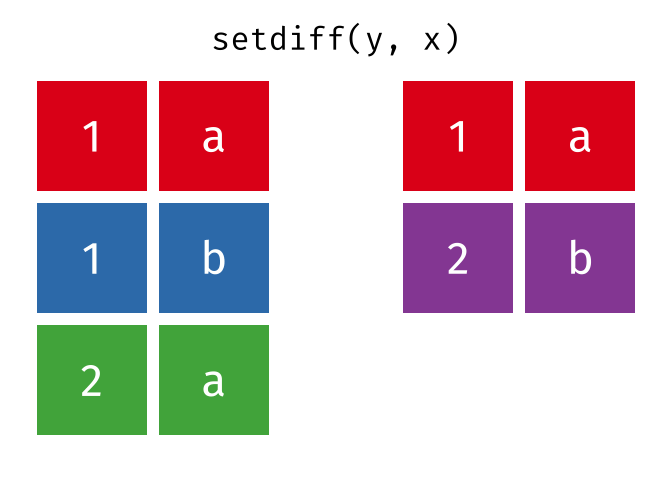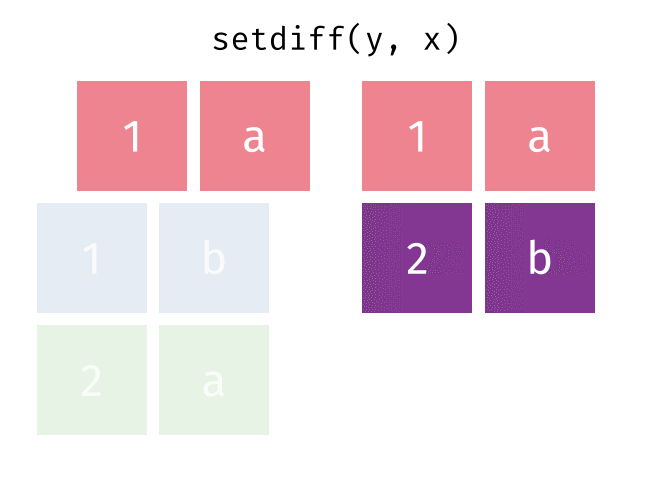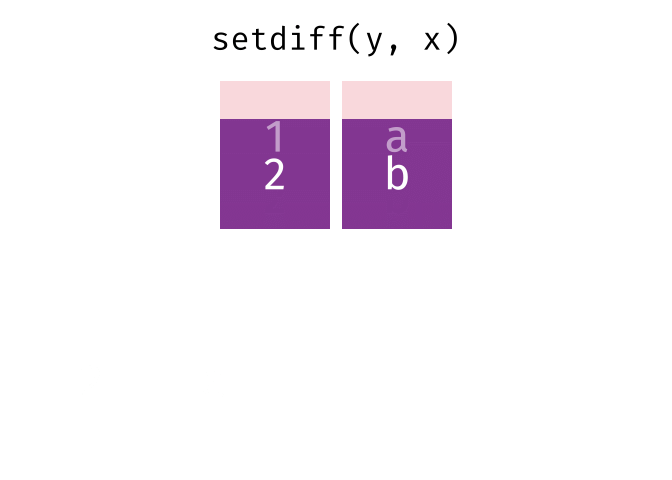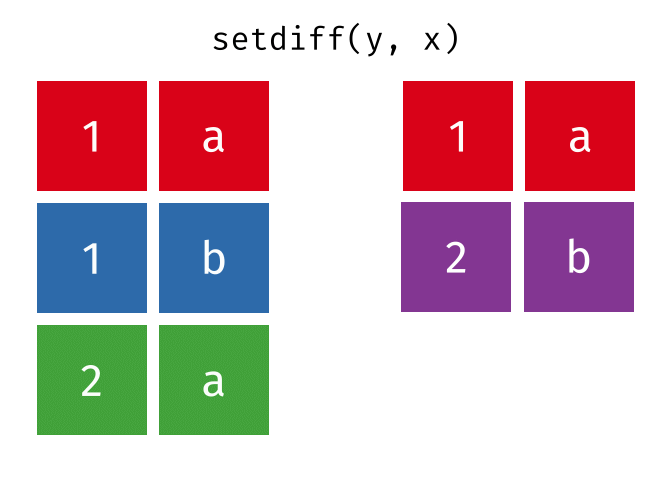
Set operations, which combine the observations in the data sets as if they were set elements.
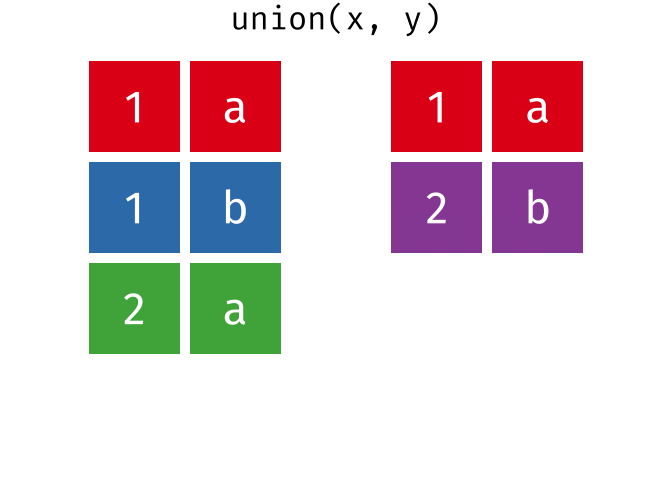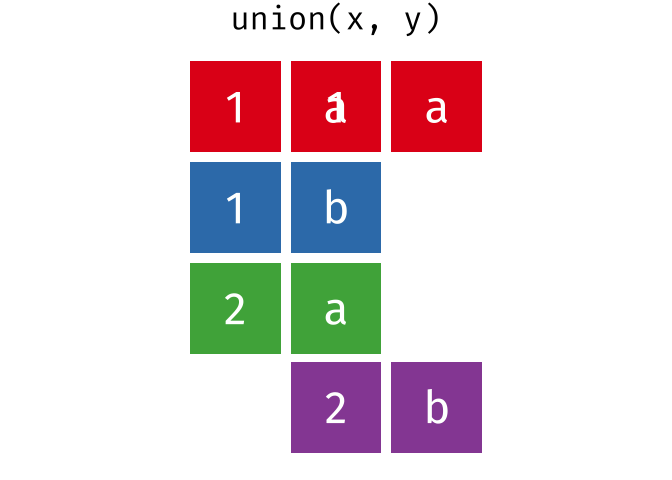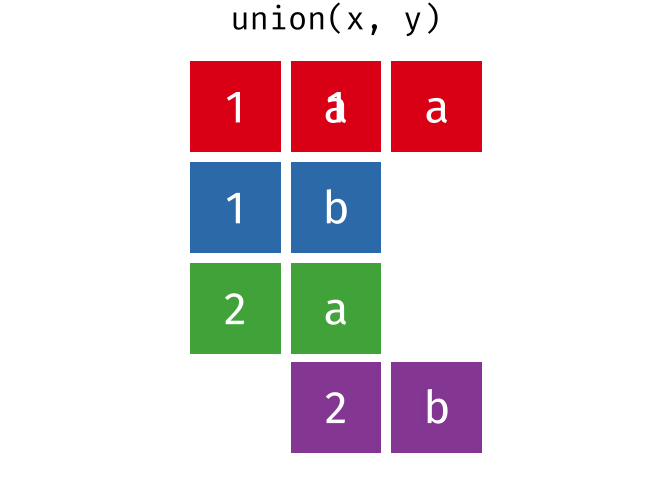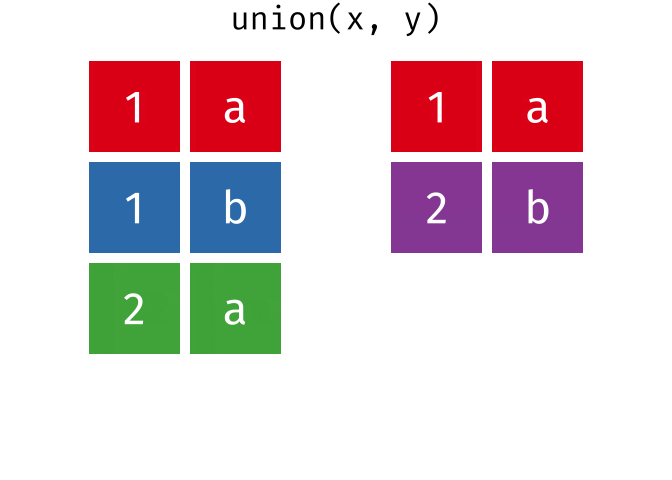
- union()
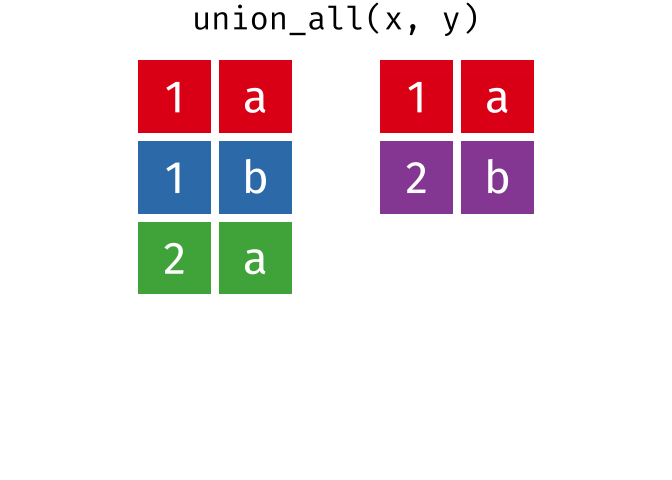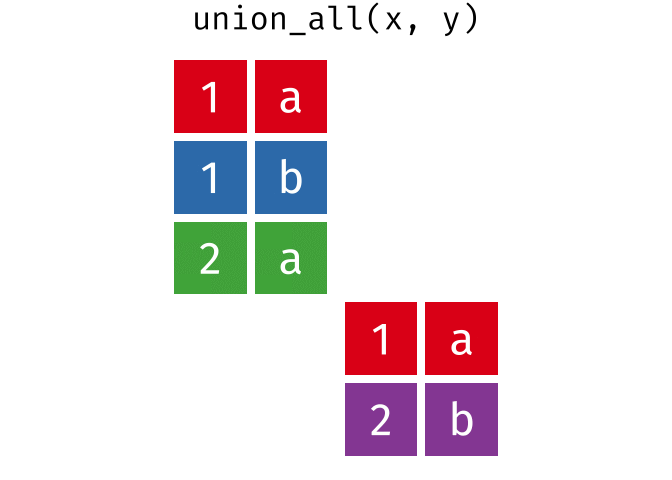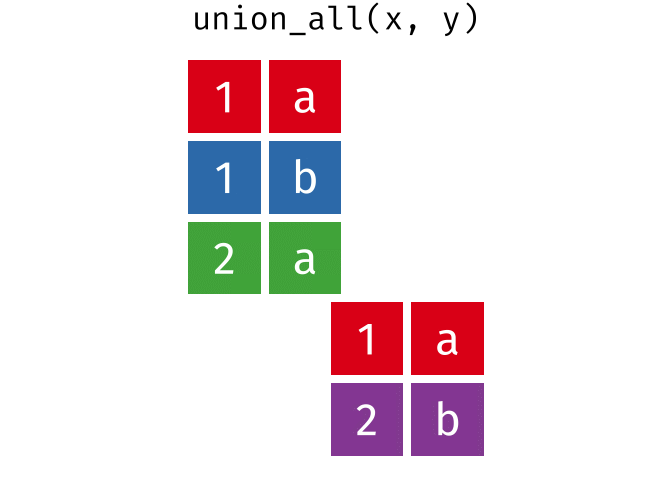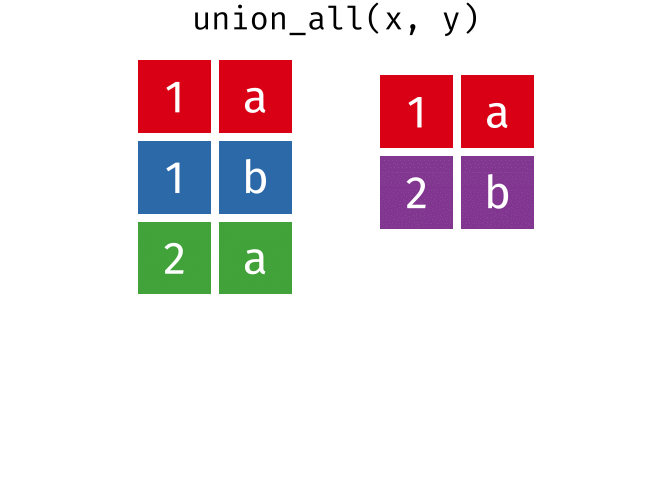
- union_all(),
- intersect(),
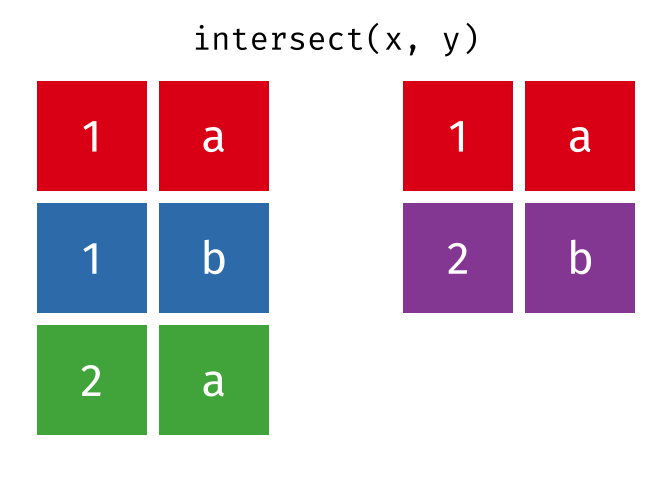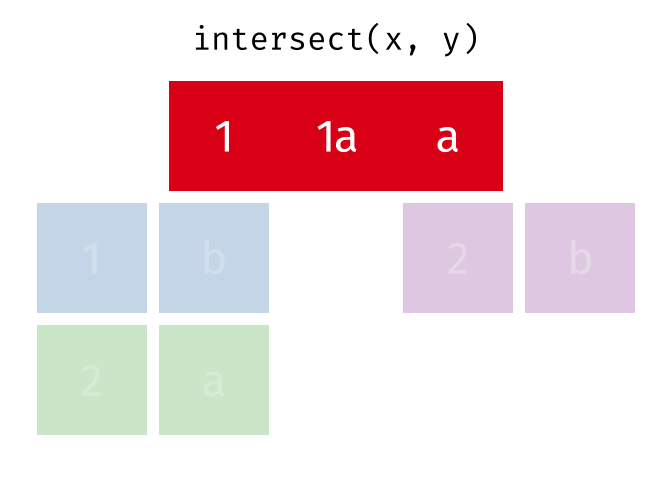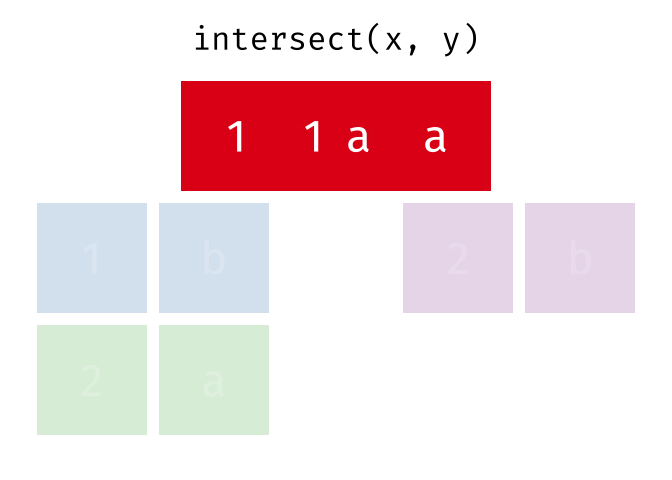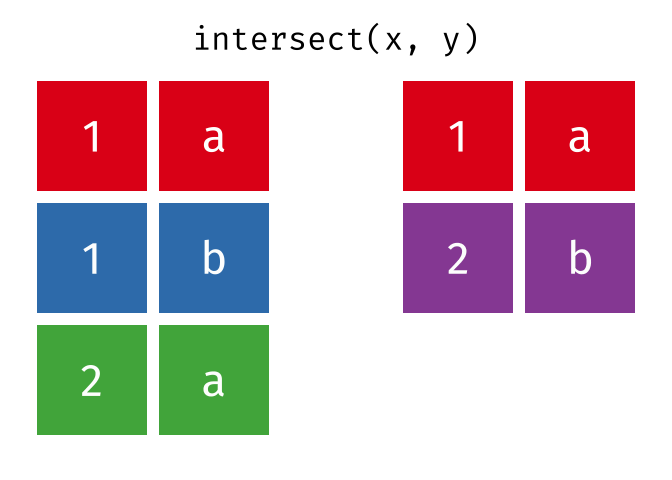
- setdiff()
- Tidyr Operations:
- pivot_longer()
- pivot_wider()
