| name | Occupation | Sex | Living | Nationality | genre | pet |
|---|---|---|---|---|---|---|
| Taylor Swift | Singer | F | TRUE | USA | country/rock | Scottish Fold Cats |
| name | Type | Living | human | Nationality | colour | material |
|---|---|---|---|---|---|---|
| Thomas, the Tank Engine | Cartoon Character | FALSE | FALSE | UK | blue | metal |
Alert - I have split up this Huge website into smaller ones. Please check out the new site URLs on the Home page for the latest course content. This website will not be updated anymore. Thanks for your patience and support! 🙏
Have you played a Childhood Game called 20 Questions? Someone has a “target” entity in mind ( a person or a thing or a literary character) and the others need to discover that entity by asking 20 questions.
Assuming we think of a 20Q Target as say, celebrity singer like Taylor Swift, or a cartoon character like Thomas the Tank Engine, what would an underlying “data structure” look like? We would ask Questions for instance in the following order to find the target of Taylor Swift:
Oh…Taylor Swift!!!
Let us try to construct the “datasets” underlying this game!
| name | Occupation | Sex | Living | Nationality | genre | pet |
|---|---|---|---|---|---|---|
| Taylor Swift | Singer | F | TRUE | USA | country/rock | Scottish Fold Cats |
| name | Type | Living | human | Nationality | colour | material |
|---|---|---|---|---|---|---|
| Thomas, the Tank Engine | Cartoon Character | FALSE | FALSE | UK | blue | metal |
It should be fairly clear that the Questions we ask are based on the COLUMNs in the respective 1-row datasets! The TARGET Column in both cases is the name column.
Can you imagine how the 20 Questions Game can be shown as a tree?
Each Question we ask, based on one of the Feature columns, begets a Yes/NO answer and we turn the left or right accordingly. When we arrive at the leaf, we should be in a position to guess the answer !
What if the dataset we had contained many rows, instead of just one row? How would we play the 20Q Game in this situation? Here is a sample of the famous penguins dataset:
| species | island | bill_length_mm | bill_depth_mm | flipper_length_mm | body_mass_g | sex | year |
|---|---|---|---|---|---|---|---|
| Chinstrap | Dream | 45.6 | 19.4 | 194 | 3525 | female | 2009 |
| Gentoo | Biscoe | 43.3 | 13.4 | 209 | 4400 | female | 2007 |
| Chinstrap | Dream | 47.5 | 16.8 | 199 | 3900 | female | 2008 |
| Chinstrap | Dream | 46.0 | 18.9 | 195 | 4150 | female | 2007 |
| Chinstrap | Dream | 50.7 | 19.7 | 203 | 4050 | male | 2009 |
| Adelie | Torgersen | 39.0 | 17.1 | 191 | 3050 | female | 2009 |
| Adelie | Biscoe | 39.7 | 18.9 | 184 | 3550 | male | 2009 |
| Chinstrap | Dream | 47.0 | 17.3 | 185 | 3700 | female | 2007 |
| Gentoo | Biscoe | 50.8 | 15.7 | 226 | 5200 | male | 2009 |
| Chinstrap | Dream | 52.7 | 19.8 | 197 | 3725 | male | 2007 |
| Adelie | Torgersen | 39.3 | 20.6 | 190 | 3650 | male | 2007 |
| Gentoo | Biscoe | 42.6 | 13.7 | 213 | 4950 | female | 2008 |
As before, we would need to look at the dataset as containing a TARGET column which we want to predict using several other FEATURE columns. Let us choose species.
When we look at the FEATURE columns, We would need to formulate questions based on entire columns at a time. For instance:
If the specific FEATURE column is a Numerical (N) variable, the question would use some “thresholding” as shown in the question above, to convert the Numerical Variable into a Categorical variable.
If a specific FEATURE column is a Categorical (C) variable, the question would be like a filter operation in Excel.
Either way, we end up answering with a smaller and smaller subset of rows in the dataset, to which the questions are answered with a Yes. It is as if we played many 20 Questions games in parallel, since there are so many simultaneous “answers”!
Once we exhaust all the FEATURE columns, then what remains is a subset (i.e. rows) of the original dataset and we read off the TARGET column, which should now contain a set of identical entries, e.g. “Adelie”. Thus we can extend a single-target 20Q game to a multiple-target one using a larger dataset. ( Note how the multiple targets are all the same: “Adelie”, or “Gentoo”, or “Chinstrap”)
This forms the basic intuition for a Machine Learning Algorithm called a Decision Tree.
Let us visualize this Decision Tree in Orange. Look at the now famous penguins dataset, available here:
https://raw.githubusercontent.com/mwaskom/seaborn-data/master/penguins.csv
We see that there are three species of penguins, that live on three islands. The measurements for each penguin are flipper_length_mm, bill_length_mm, bill_depth_mm, and body_mass_g.
Task 1: Create a few data visualizations for the variables, and pairs of variables from this dataset.
Task 2: Can you inspect the visualizations and imagine how each of this dataset can be used in a 20 Questions Game, to create a Decision Tree for this dataset as shown below?
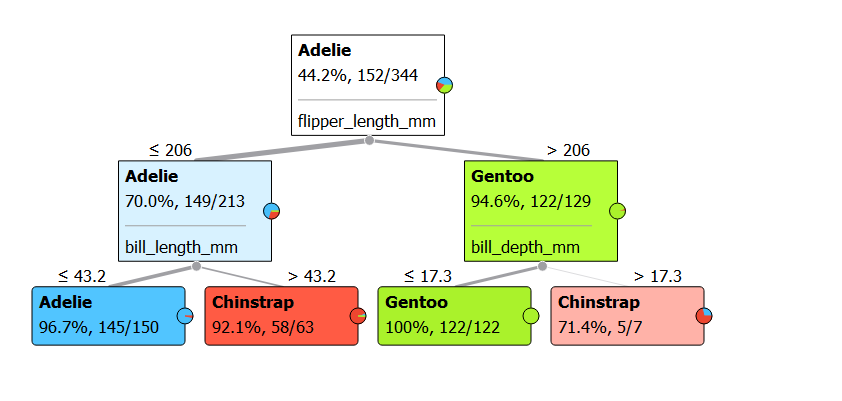
island and the species columns are categories and are especially suited to being the targets for a 20 Questions Game.This is how we will use this Game as a Model for our first ML algorithm, classification using Decision Trees.
Our aim is to make predictions. Predictions of what? When we are given new unseen data in the same format, we should be able to predict TARGET variable using the same FEATURE columns.
NOTE: This that is usually a class/category (We CAN also predict a numerical value with a Decision Tree; but we will deal with that later.)
In order to make predictions with completely unseen data, we need to first check if the algorithm is working well with known data. The way to do this is to use a large portion of data to design the tree, and then use the tree to predict some aspect of the remaining, but similar, data. Let us split the penguins dataset into two pieces: a training set to design our tree, and a test set to check how it is working.
Download this penguin tree file and open it in Orange.
How good are the Predictions? What is the Classification Error Rate?
Check all your individual Decision Trees: do they ask the same Questions? Do they fork in the same way? Yes, they all seem to use the same set of parameters to reach the target. So they are capable of being “biased” and make the same mistakes. So we ask: Does it help to use more than one tree, if all the questions/forks in the Trees are similar?
No…we need different Trees to be able to ask different questions, based on different variables or features in the data. That will make the Trees as different as possible and so…unbiased. This is what we also saw when we played 20Q: offbeat questions opened up some avenues for predicting the answer/target.
A forest of such trees is called the Wild Wood a Random Forest !
In the Random Forest method, we do as follows:
training and test subsets (70::30 proportion is very common). Keep aside the testing dataset for final testing.penguins, if our target is species, then some trees will will use island, some others will use body_mass_g and some others may use bill_length_mm.species predominantly)test set let each tree vote on which species it has decided upon. Take the majority vote.Phew!!
Let’s get a visual sense of how all this works:
Do you want to develop an ML model for heart patients? We have a dataset of heart patients at the University of California, Arvind Irvine ML Dataset Repository
Heart Patient Data. Import into Orange !!
What are the variables?
We will create a Random Forest Model for this dataset, and compare with the Desision Tree for the same dataset.