| No | Pronoun | Answer | Variable/Scale | Example | What Operations? |
|---|---|---|---|---|---|
| 1 | How Many / Much / Heavy? Few? Seldom? Often? When? | Quantities, with Scale and a Zero Value.Differences and Ratios /Products are meaningful. | Quantitative/Ratio | Length,Height,Temperature in Kelvin,Activity,Dose Amount,Reaction Rate,Flow Rate,Concentration,Pulse,Survival Rate | Correlation |
The clocks were striking thirteen.
Qual Variables and Quant Variables
Histograms and Density Plots
| Variable #1 | Variable #2 | Chart Names | Chart Shape | |
|---|---|---|---|---|
| Quant | None | Histogram |
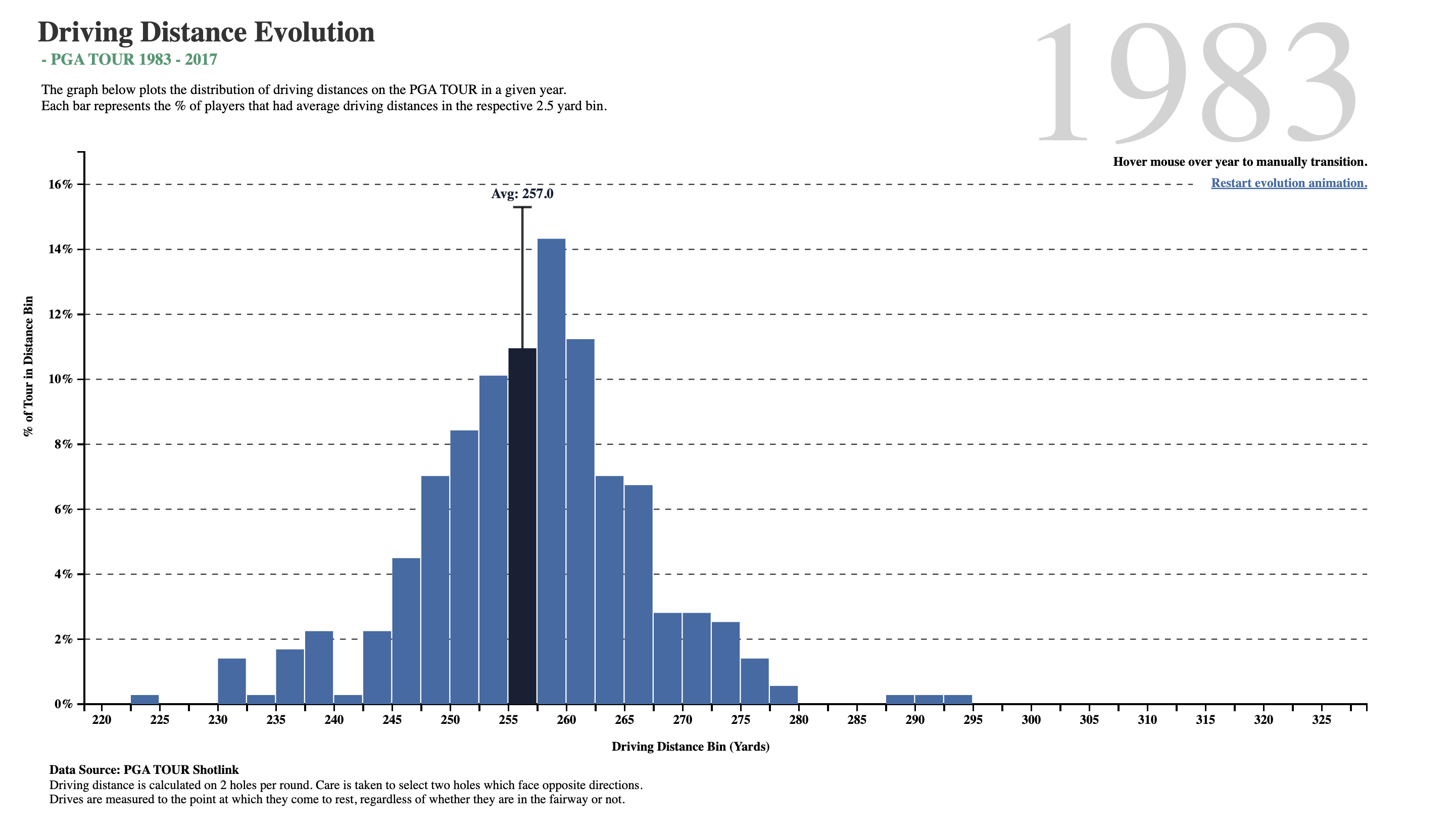
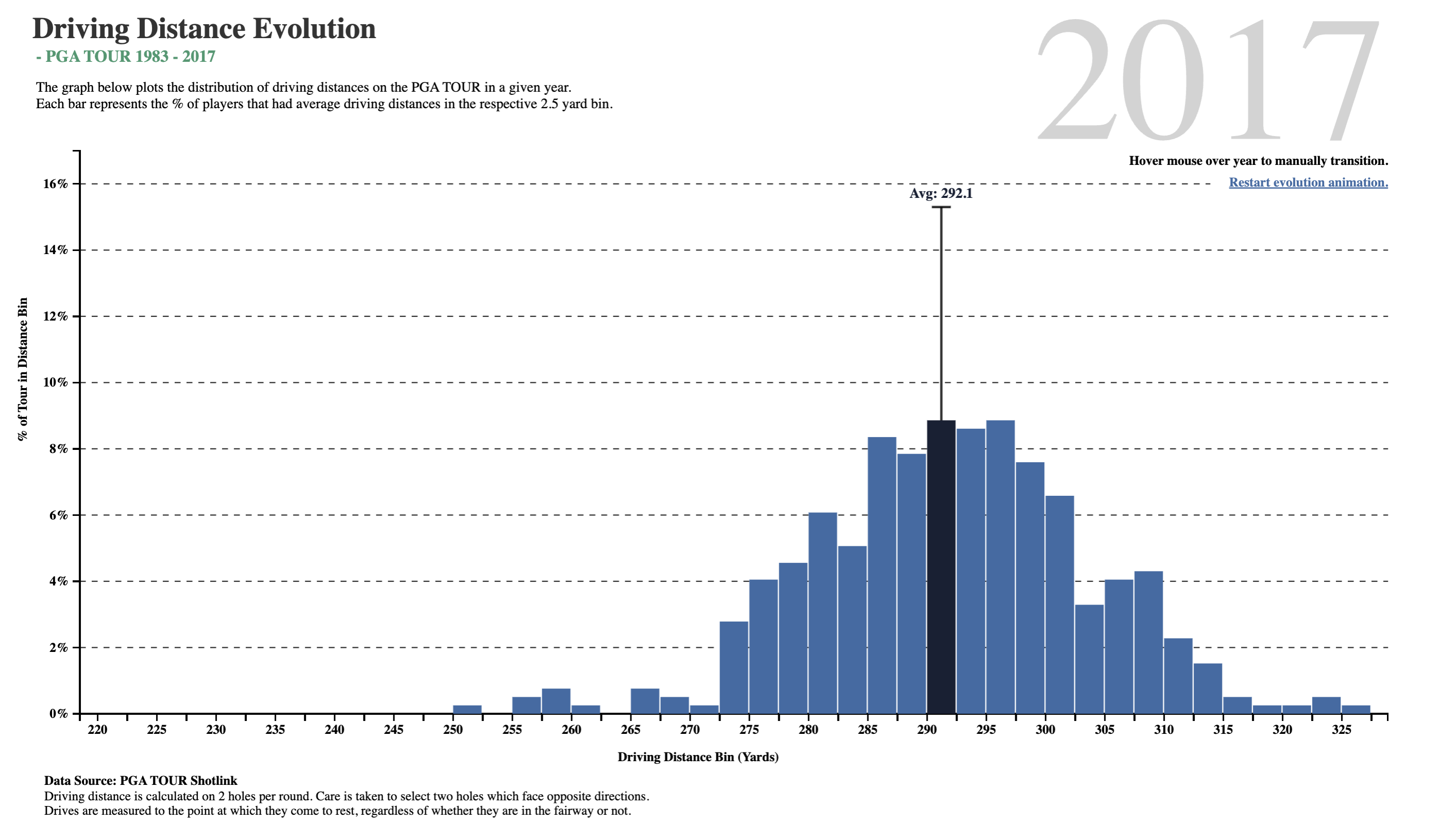
What do we see here? In about two-and-a-half decades, golf drive distances have increased, on the average, by 35 yards. The maximum distance has also gone up by 30 yards, and the minimum is now at 250 yards, which was close to average in 1983! What was a decent average in 1983 is just the bare minimum in 2017!!
Is it the dimples that the golf balls have? But these have been around a long time…or is it the clubs, and the swing technique invented by more recent players?
Histograms are best to show the distribution of values of a quantitative variable. A distribution shows how often the variable in question lies within specific value ranges. We plot the histogram by displaying the how often vs defined ranges, often called buckets or bins. For example, in 2017, 8.5% of all drive distances were at the then average distance of 292.1 yards. One can create histogram buckets from Quant variables, such as 0-5, 6-10, 11-15…etc.
Histograms vs Bar/Column Charts
As we will see shortly, Bar/Column charts show categorical data, such as the number of apples, bananas, carrots, etc. Visually speaking, histograms do not usually show spaces between buckets because these are continuous values, while column charts must show spaces to separate each category. More later.
Let us rapidly make some histograms in Orange, so that we know how the tool works here. We start with the iris dataset: Download this Orange workflow file and open it in Orange.
You can see the effect of modifying the bin widths, and of fitting a standard distribution for comparison.
RAWgraphs does not appear to have a histogram plotting tool…
https://academy.datawrapper.de/article/136-histogram-min-max-median-mean
DataWrapper also does not offer a separate histogram-making tool. Histograms in DataWrapper are available as a part of the data-inspection part of the work flow, as a small thumbnail-sized plot.
We are now ready for a more detailed example. Here is a look at this data on Netflix Original Series. Download it to your machine by clicking on the button below.
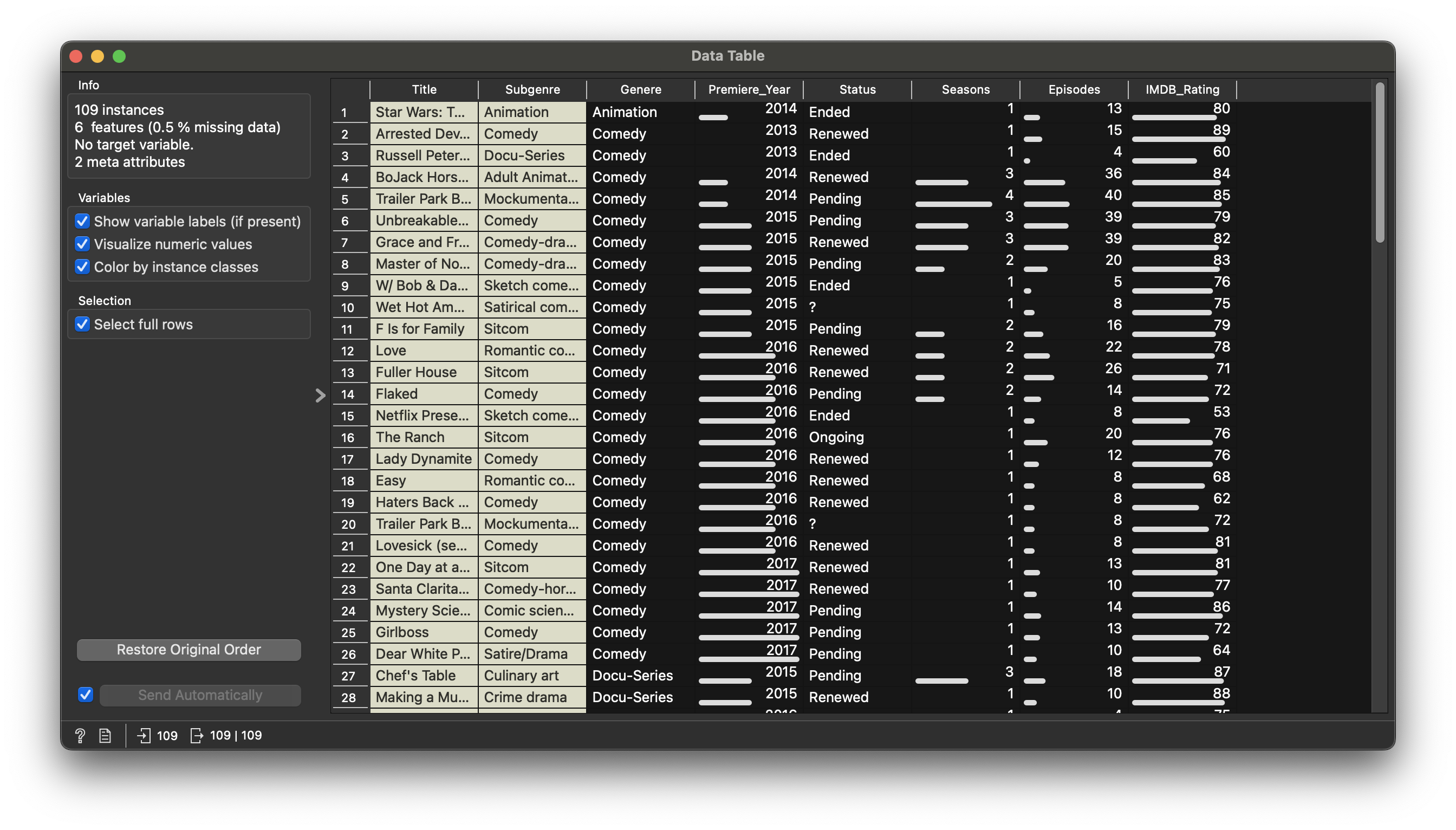
Figure 2 states that there are 109 movies, 6 variables in the dataset.
Quantitative Data
-
Premiere_Year: (int) Year the movie premiered -
Seasons: (int) No. of Seasons -
Episodes: (int) No. of Episodes -
IMDB_Rating: (int) IMDB Rating!!
Qualitative Data
-
Genere: (chr) types of Genres -
Title: (chr) 109 titles -
Subgenre: (chr) types of sub-Genres -
Status: (chr) status on Netflix
Let’s try a few questions and see if they are answerable with Histograms.
Note
Note
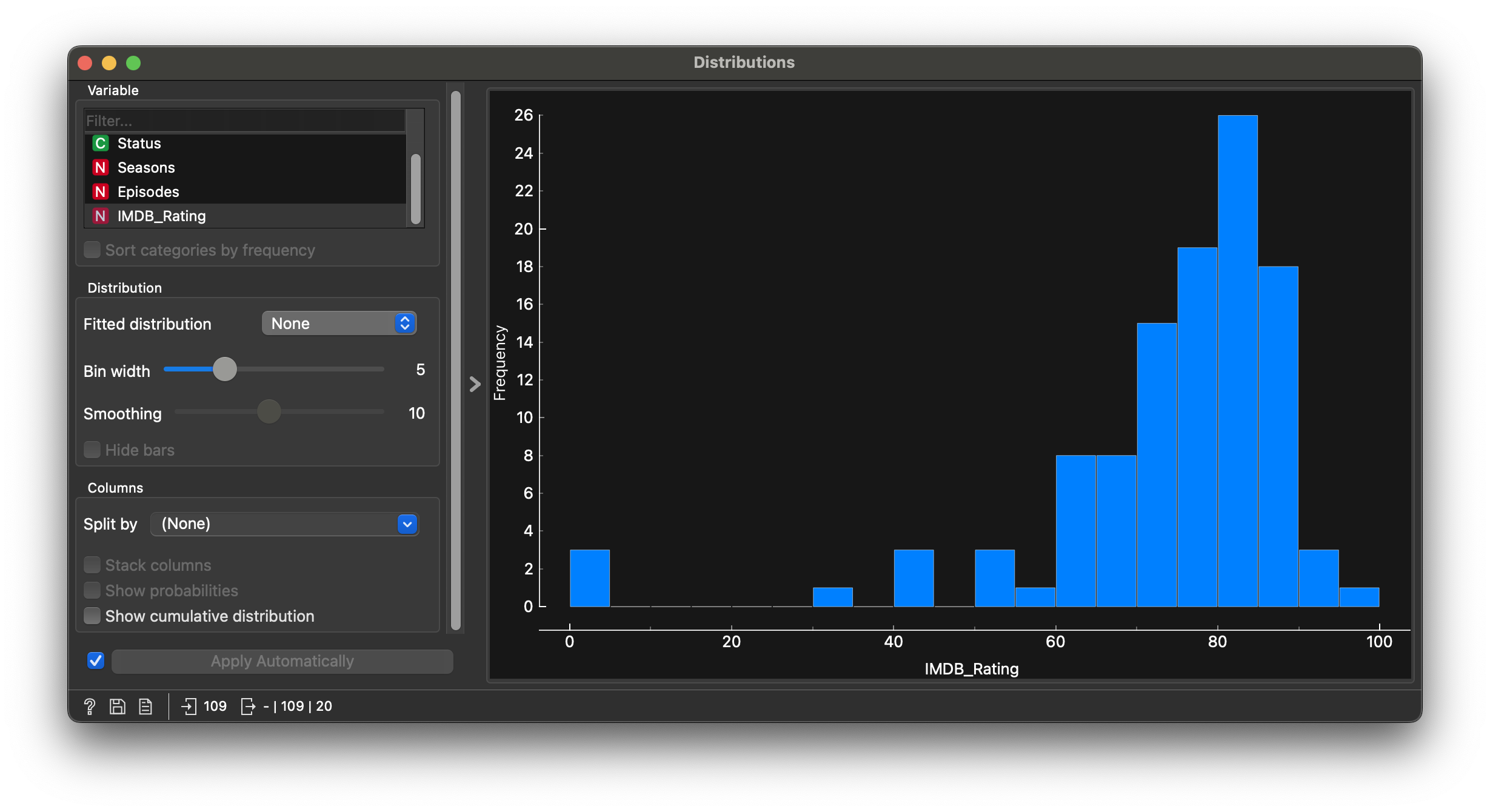
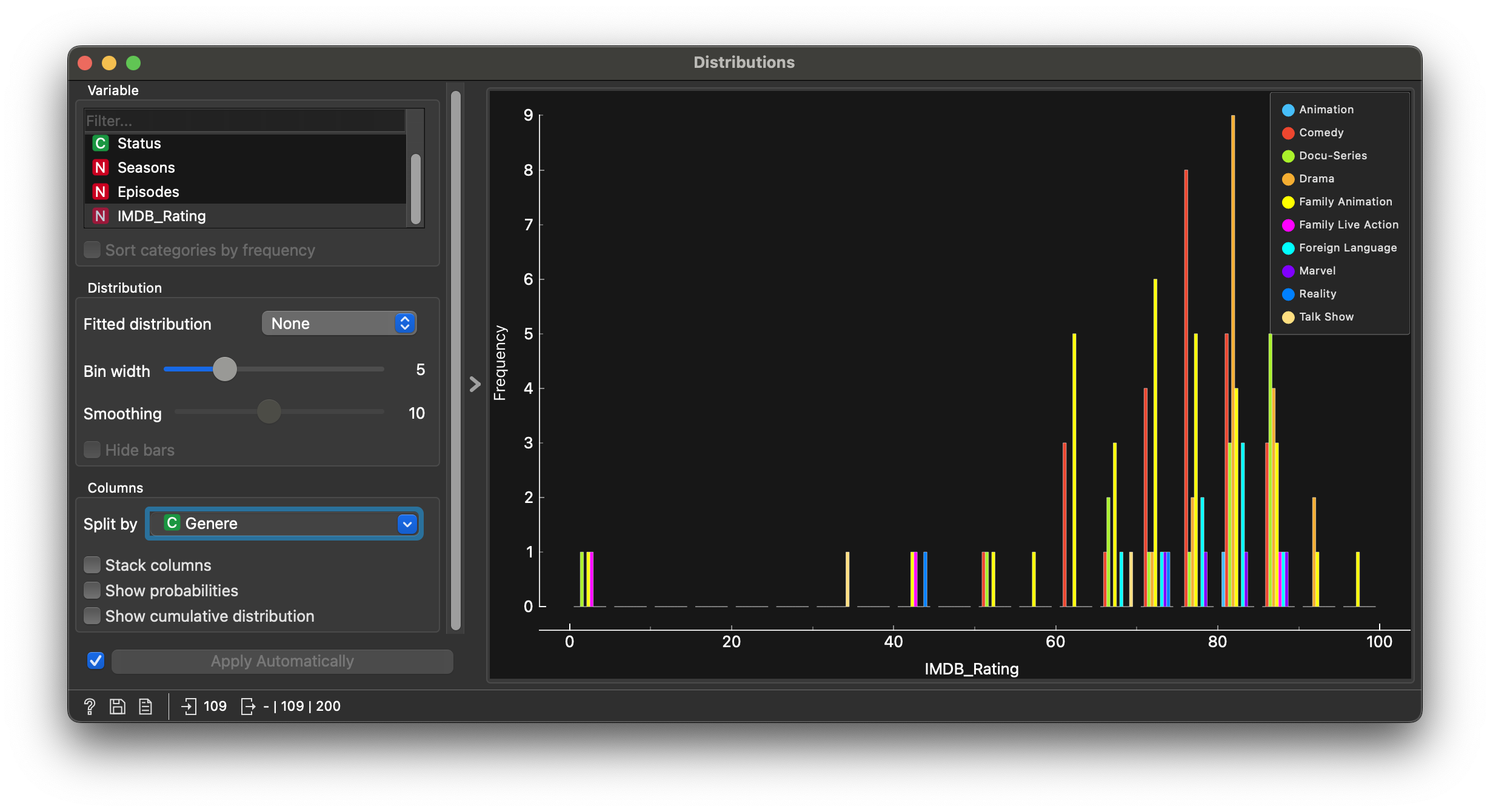
Q2. Are IMDB_Rating affected by the number of Seasons or Episodes?
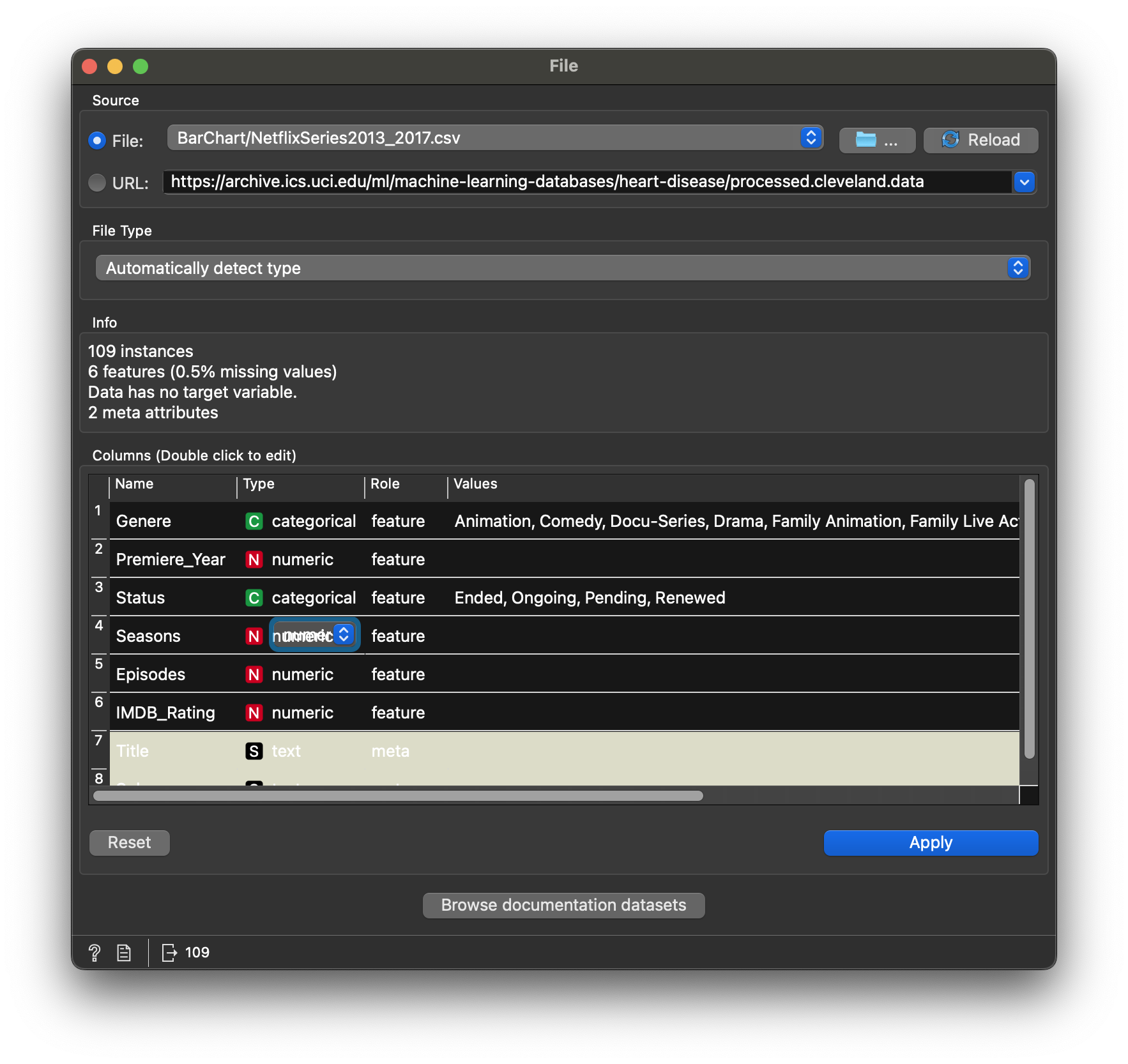
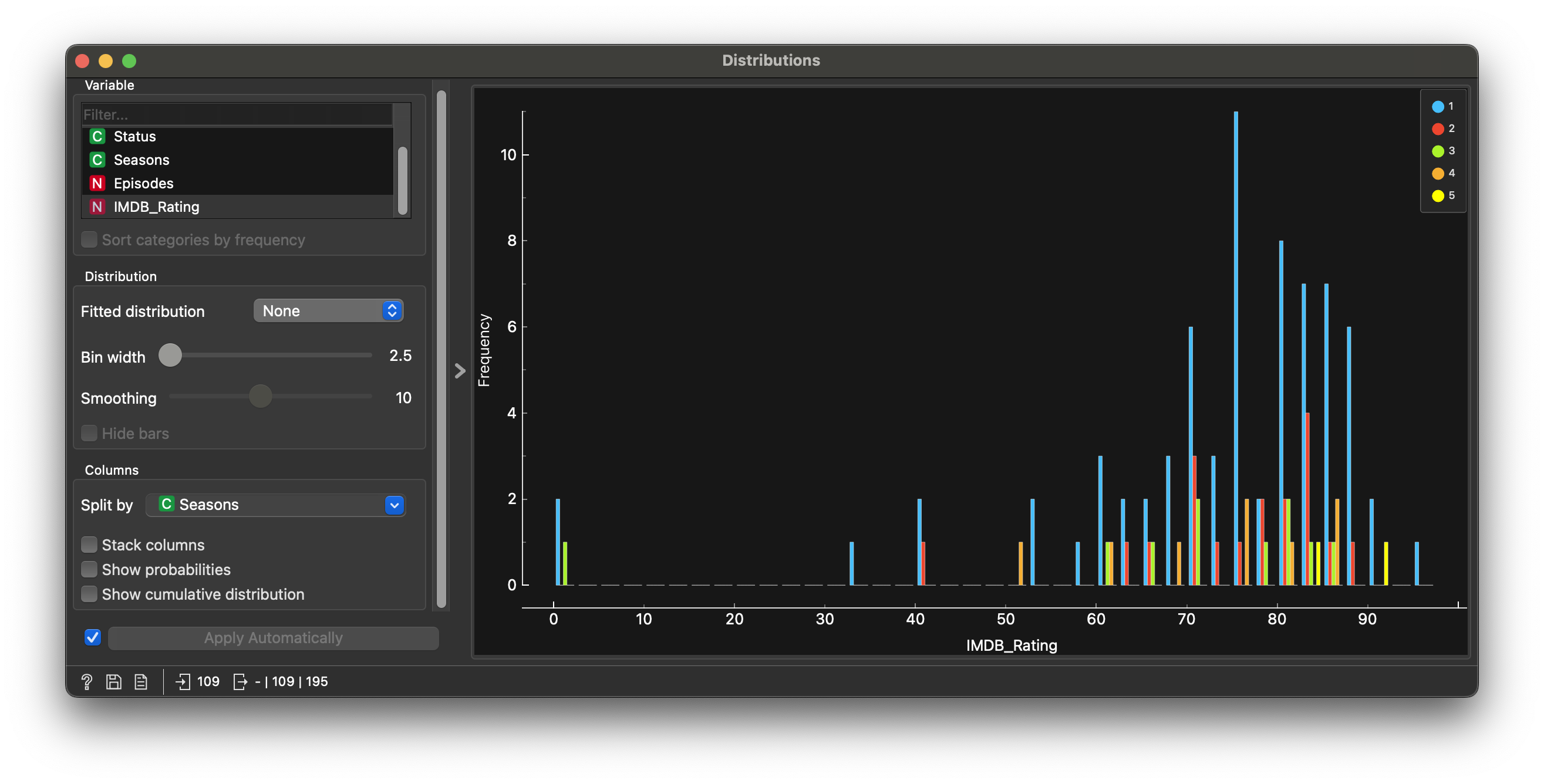
We first need to reformat the Seasons variable from N to C in the data file view. This converts it to Qual. Then we split the IMDB histogram by this new variable.
Most movies have decent IMDB scores; the distribution is left-skewed. Some of course have been trashed!! Splitting IMDBRating by Genere is not too illuminating…
Not much wisdom to be gleaned either from splitting IMDBRating by Seasons…
Here is a dataset about the eruption durations, and wait times between eruptions of the Old Faithful geyser in Yellowstone National Park, USA.
Download this data to your machine and import it into Orange.

Figure 5 states that we have 272 data points, and three variables. All variables are Quantitative!
Quantitative Data
-
eruptions: (dbl Duration Times of Eruptions -
waiting: (dbl) Waiting Times between Eruptions -
density: (dbl) (Ignore this for now)
Qualitative Data
- No Qual variables!!
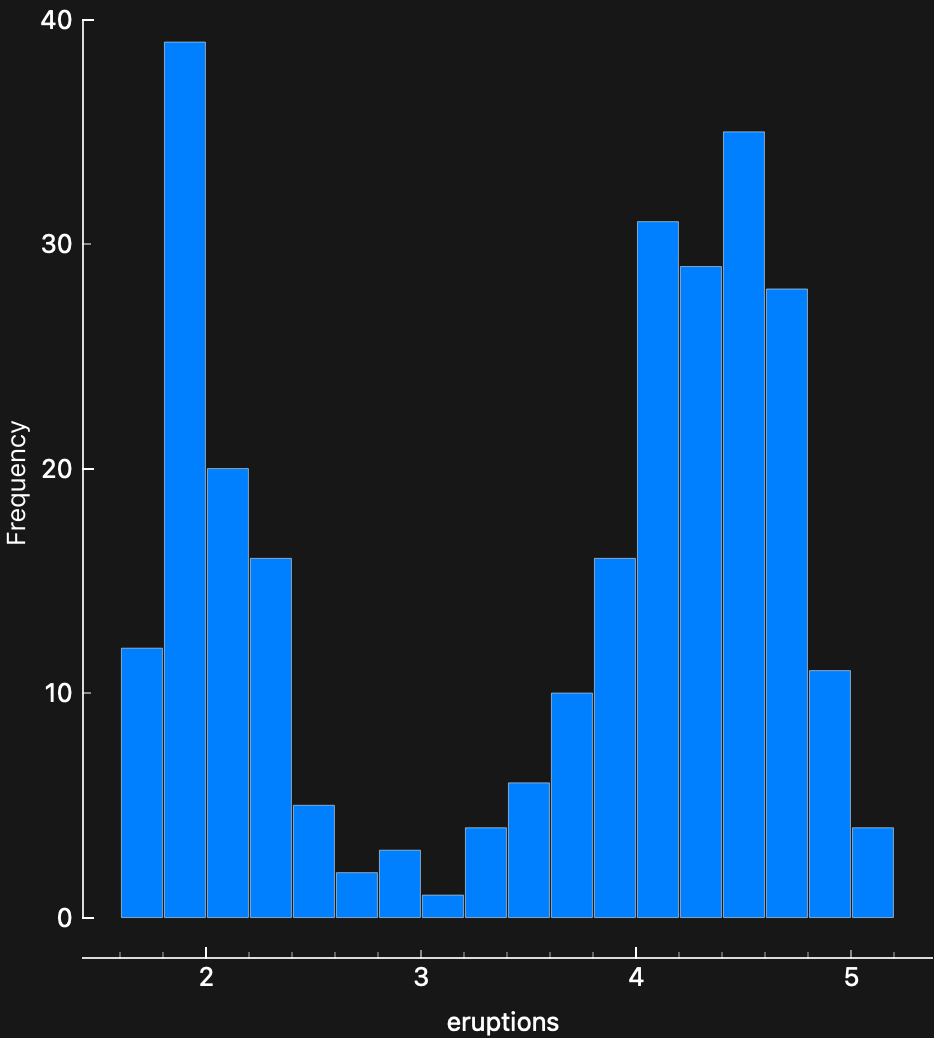
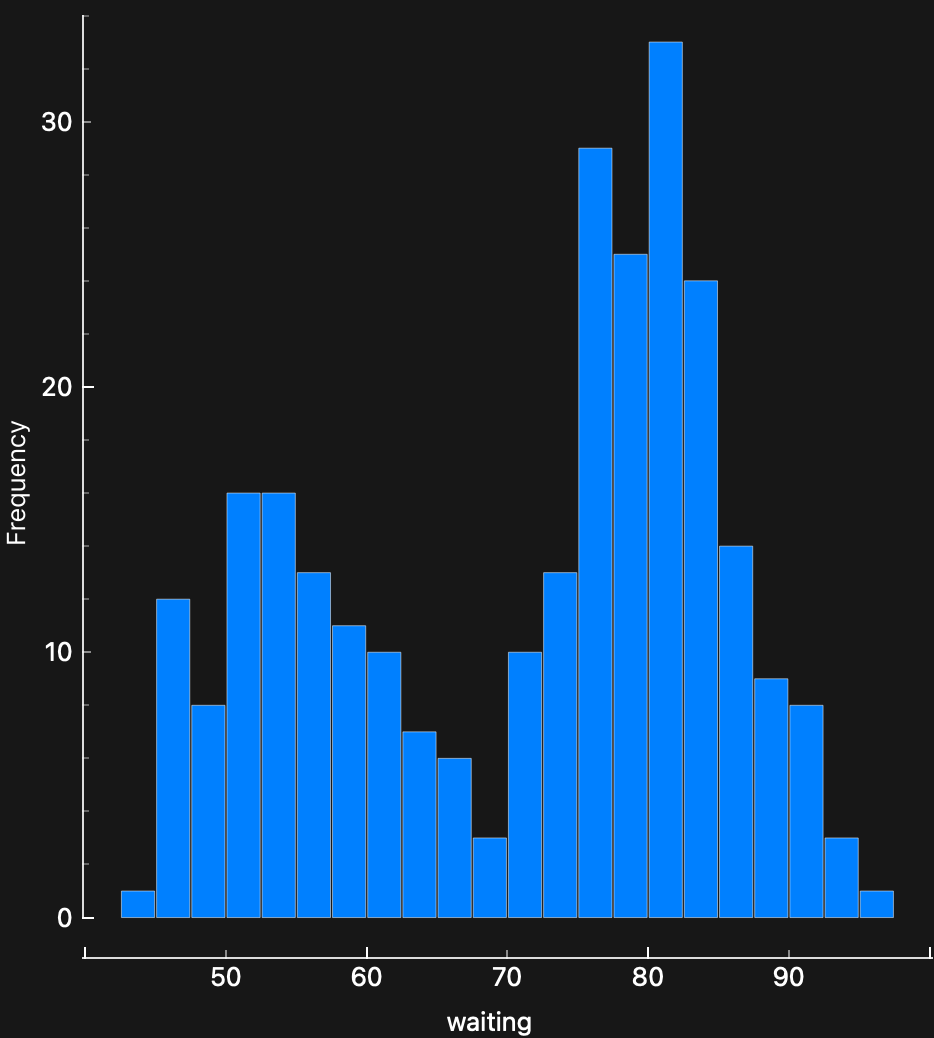
- Both durations have a “double-humped” distribution…
- There are therefore two distinct ranges for both durations.
- Are there two different mechanisms at work in the geyser, that randomly kick in?
Try your hand at these datasets. Look at the data table, state the data dictionary, contemplate a few Research Questions and answer them with graphs in Orange!
Airbnb Price Data on the French Riviera
Time taken to Open or Close Packages
Note
Orange can handle xlsx files directly. Try! How might you disregard the different package types and concentrate on “Opening/Closing Times” vs “Hand Pain or no Hand Pain”?
- Histograms are used to study the distribution of one or a few Quant variables.
- Checking the distribution of your variables one by one is probably the first task you should do when you get a new dataset.
- It delivers a good quantity of information about spread, how frequent the observations are, and if there are some outlandish ones.
- Comparing histograms side-by-side helps to provide insight about whether a Quant measurement varies with situation (a Qual variable). We will see this properly in a statistical way soon.
City Populations, Sales across product categories, Salaries, Instagram connections, number of customers vs Companies, net worth / valuation of Companies, extreme events on stock markets….all of these could have highly skewed distributions. In such a case, the standard statistics of mean/median/sd may not convey too much information. With such distributions, one additional observation on say net worth, like say Mr Gates’, will change these measures completely.
Since very large observations are indeed possible, if not highly probable, one needs to look at the result of such an observation and its impact on a situation rather than its (mere) probability. Classical statistical measures and analysis cannot apply with long-tailed distributions. More on this later when we discuss Statistical Inference, but for now, here is a video that talks in detail about fat-tailed distributions, and how one should use them and get used to them:
Several distribution shapes exist, here is an illustration of the 6 most common ones:
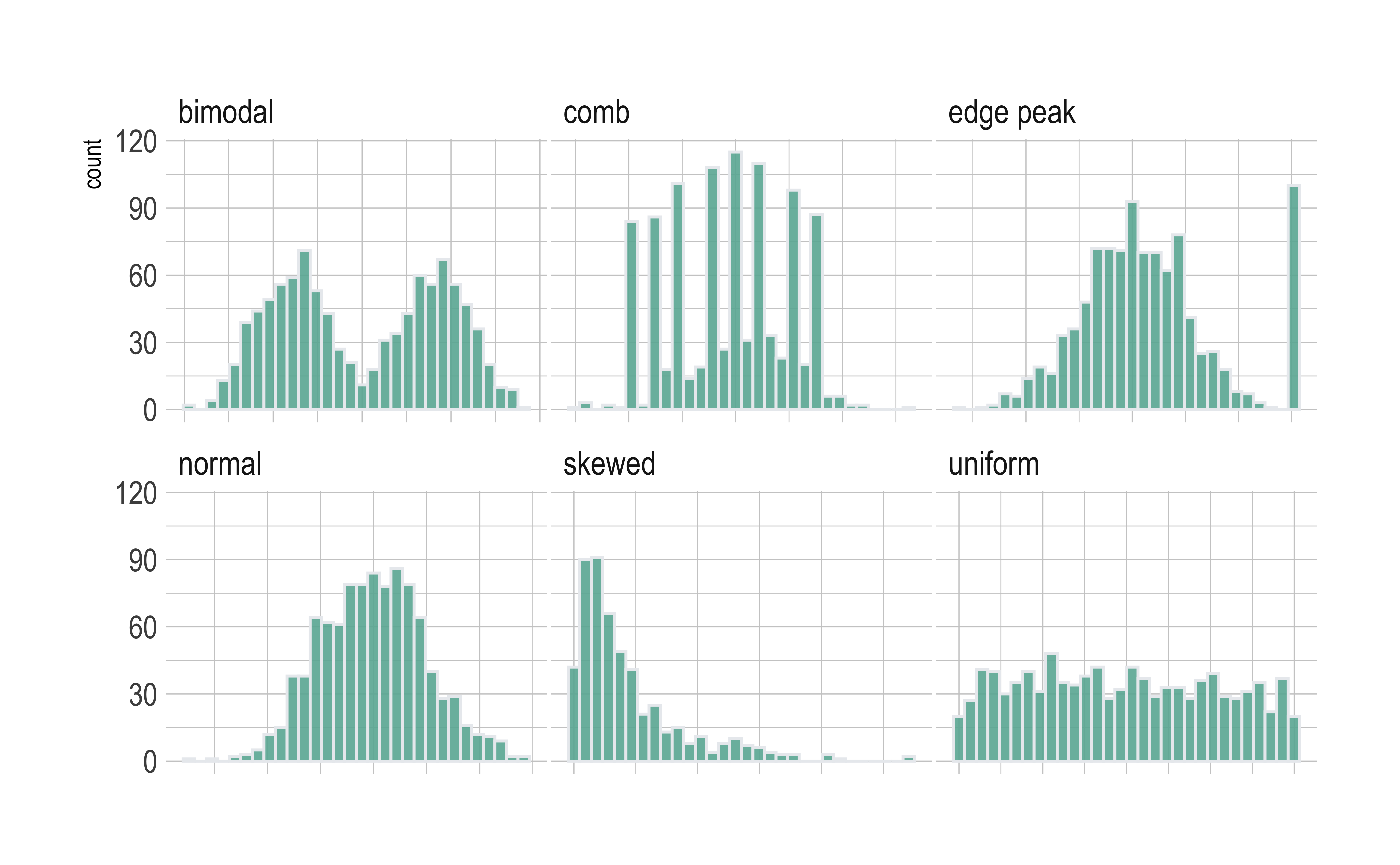
What insights could you develop based on these distribution shapes?
-
Bimodal: Maybe two different systems or phenomena or regimes under which the data unfolds. Like our geyser above. Or a machine that works differently when cold and when hot. Intermittent faulty behaviour…
-
Comb: Some specific Observations occur predominantly, in an otherwise even spread or observations. In a survey many respondents round off numbers to nearest 100 or 1000. Check the distribution of
caratvalues for this diamonds dataset which are suspiciously integer numbers in too many cases.
-
Edge Peak: Could even be a data entry artifact!! All unknown / unrecorded observations are recorded as
-
Normal: Just what it says! Course Marks in a Univ cohort…
-
Skewed: Income, or friends count in a set of people. Do UI/UX peasants have more followers on Insta than say CAP people?
-
Uniform: The World is
notflat. Anything can happen within a range. But not much happens outside! Sharp limits…
In your Design-Project-related research, you will collect data from or about your target audience. The Quantitative parts of that data may obtain with any of these distributions. Inspecting these may give you an insight into the population of your target audience, something that may likely be true, a hunch, which you could verify and convert into …design opportunity.
See the scrolly animation for a histogram at this website: Exploring Histograms, an essay by Aran Lunzer and Amelia McNamara https://tinlizzie.org/histograms/?s=09