Alert - I have split up this Huge website into smaller ones. Please check out the new site URLs on the Home page for the latest course content. This website will not be updated anymore. Thanks for your patience and support! 🙏
On this page
🃏 Inference for Two Independent Means
How different are you?
Published
November 22, 2022
Modified
July 29, 2025
To be nobody but myself – in a world which is doing its best, night and day, to make you everybody else – means to fight the hardest battle which any human being can fight, and never stop fighting.
library(systemfonts)library(showtext)## Clean the slatesystemfonts::clear_local_fonts()systemfonts::clear_registry()##showtext_opts(dpi =96)# set DPI for showtextsysfonts::font_add( family ="Alegreya", regular ="../../../../../../fonts/Alegreya-Regular.ttf", bold ="../../../../../../fonts/Alegreya-Bold.ttf", italic ="../../../../../../fonts/Alegreya-Italic.ttf", bolditalic ="../../../../../../fonts/Alegreya-BoldItalic.ttf")
Error in check_font_path(bold, "bold"): font file not found for 'bold' type
Show the Code
sysfonts::font_add( family ="Roboto Condensed", regular ="../../../../../../fonts/RobotoCondensed-Regular.ttf", bold ="../../../../../../fonts/RobotoCondensed-Bold.ttf", italic ="../../../../../../fonts/RobotoCondensed-Italic.ttf", bolditalic ="../../../../../../fonts/RobotoCondensed-BoldItalic.ttf")showtext_auto(enable =TRUE)# enable showtext##theme_custom<-function(){font<-"Alegreya"# assign font family up fronttheme_classic(base_size =14, base_family =font)%+replace%# replace elements we want to changetheme( text =element_text(family =font), # set base font family# text elements plot.title =element_text(# title family =font, # set font family size =24, # set font size face ="bold", # bold typeface hjust =0, # left align margin =margin(t =5, r =0, b =5, l =0)), # margin plot.title.position ="plot", plot.subtitle =element_text(# subtitle family =font, # font family size =14, # font size hjust =0, # left align margin =margin(t =5, r =0, b =10, l =0)), # margin plot.caption =element_text(# caption family =font, # font family size =9, # font size hjust =1), # right align plot.caption.position ="plot", # right align axis.title =element_text(# axis titles family ="Roboto Condensed", # font family size =12), # font size axis.text =element_text(# axis text family ="Roboto Condensed", # font family size =9), # font size axis.text.x =element_text(# margin for axis text margin =margin(5, b =10))# since the legend often requires manual tweaking# based on plot content, don't define it here)}
Show the Code
```{r}#| cache: false#| code-fold: true## Set the themetheme_set(new =theme_custom())## Use available fonts in ggplot text geoms too!update_geom_defaults(geom ="text", new =list(family ="Roboto Condensed",face ="plain",size =3.5,color ="#2b2b2b"))```
Introduction
Case Study #1: A Simple Data set with Two Quant Variables
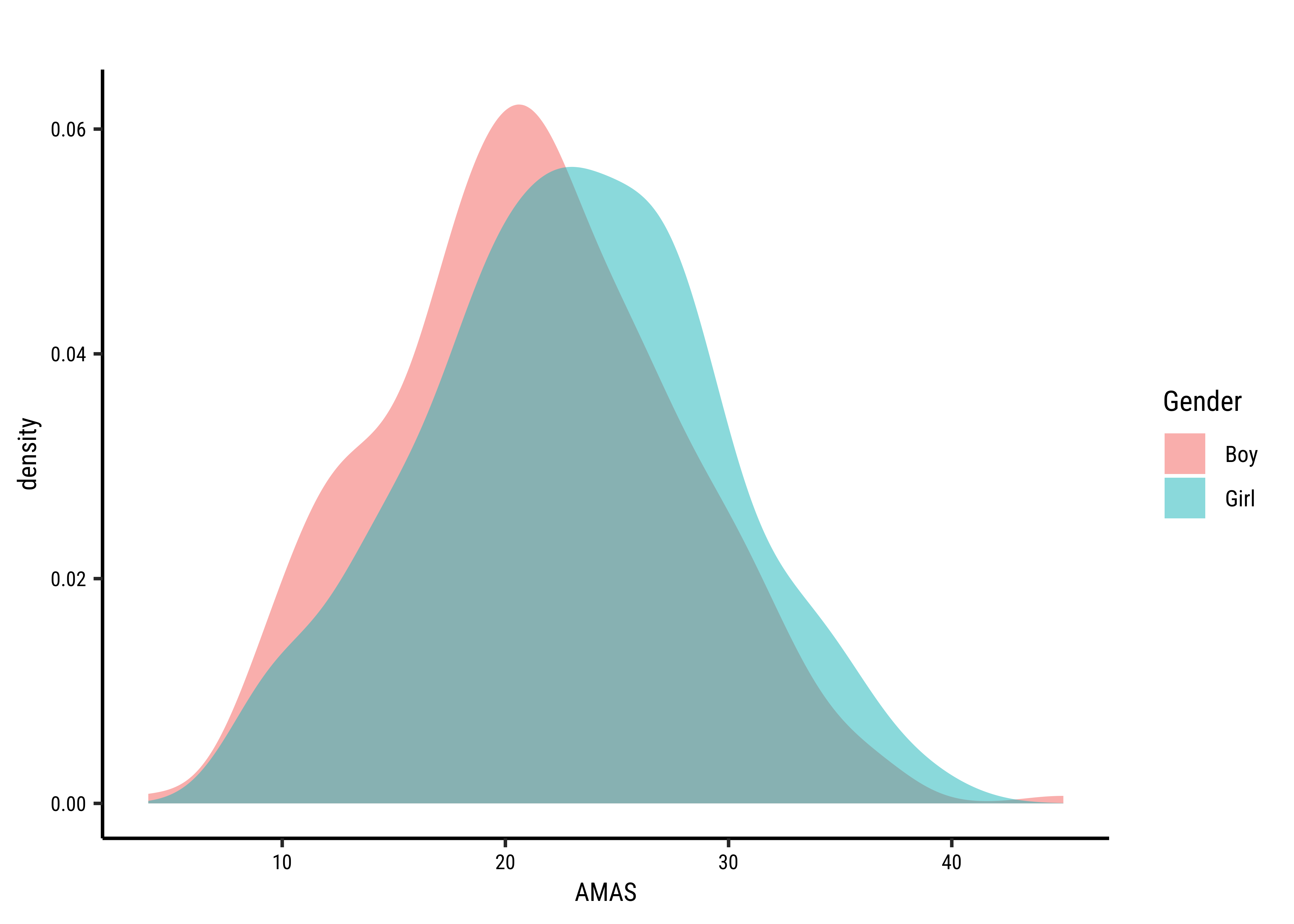
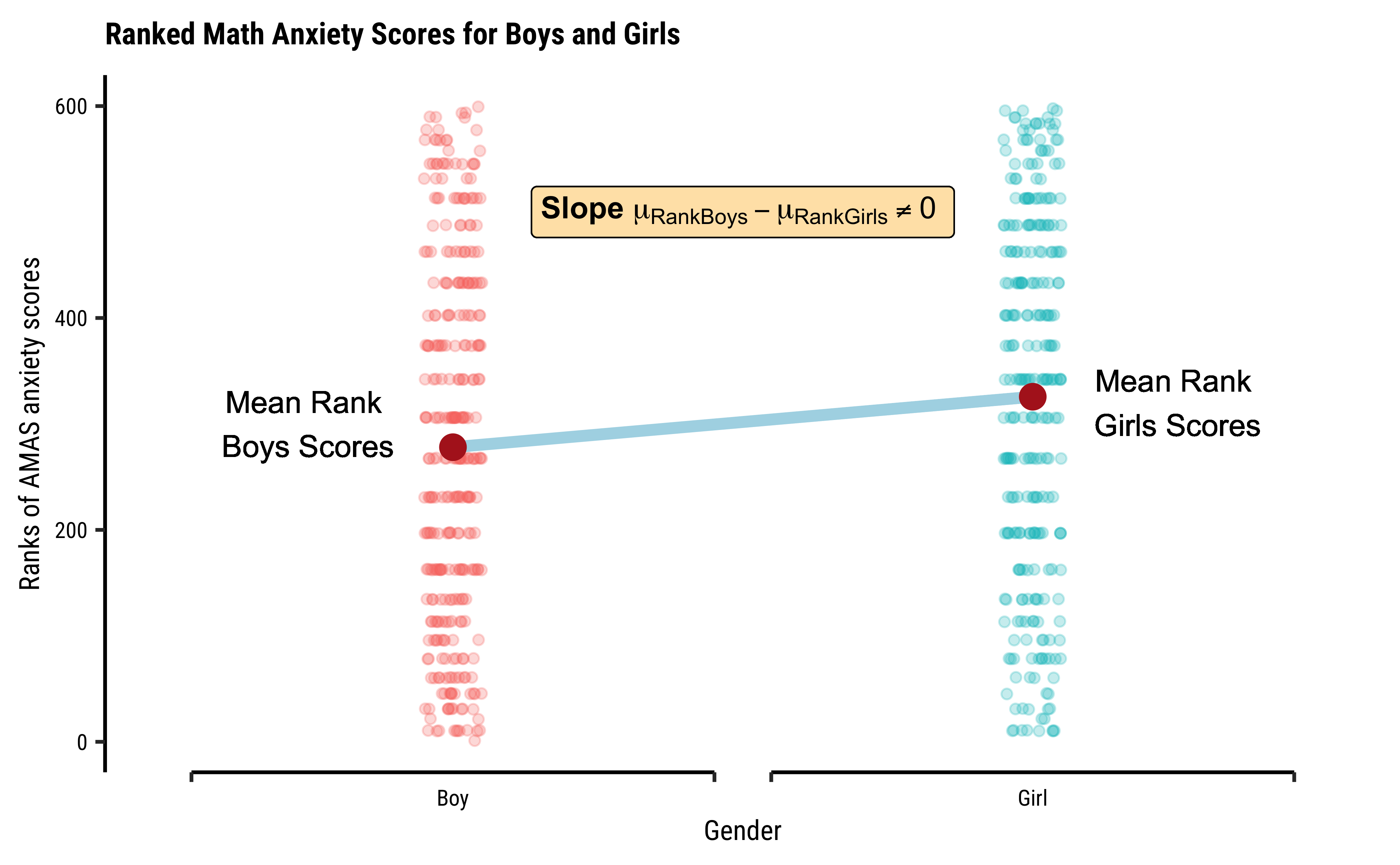
Let us look at the MathAnxiety dataset from the package resampledata. Here we have “anxiety” scores for boys and girls, for different components of mathematics.
We have ~600 data entries, and with 4 Quant variables; Age,AMAS, RCMAS, and AMAS; and two Qual variables, Gender and Grade. A simple dataset, with enough entries to make it worthwhile to explore as our first example.
Research Question
Is there a difference between boy and girl “anxiety” levels for AMAS (test) in the population from which the MathAnxiety dataset is a sample?
First, histograms, densities and counts of the variable we are interested in, after converting data into long format:
Show the Code
# Set graph themetheme_set(new =theme_custom())#MathAnxiety%>%gf_density(~AMAS, fill =~Gender, alpha =0.5, title ="Math Anxiety Score Densities", subtitle ="Boys vs Girls")##MathAnxiety%>%pivot_longer( cols =-c(Gender, Age, Grade), names_to ="type", values_to ="value")%>%dplyr::filter(type=="AMAS")%>%gf_jitter(value~Gender, group =~type, color =~Gender, width =0.08, alpha =0.3, ylab ="AMAS Anxiety Scores", title ="Math Anxiety Score Jitter Plots", subtitle ="Illustrating Difference in Means")%>%gf_summary(geom ="point", size =3, colour ="black")%>%gf_line( stat ="summary", linewidth =1, geom ="line", colour =~"MeanDifferenceLine")##MathAnxiety%>%count(Gender)MathAnxiety%>%group_by(Gender)%>%summarise(mean =mean(AMAS))
ABCDEFGHIJ0123456789
Gender
<fct>
n
<int>
Boy
323
Girl
276
ABCDEFGHIJ0123456789
Gender
<fct>
mean
<dbl>
Boy
21.16718
Girl
22.93478
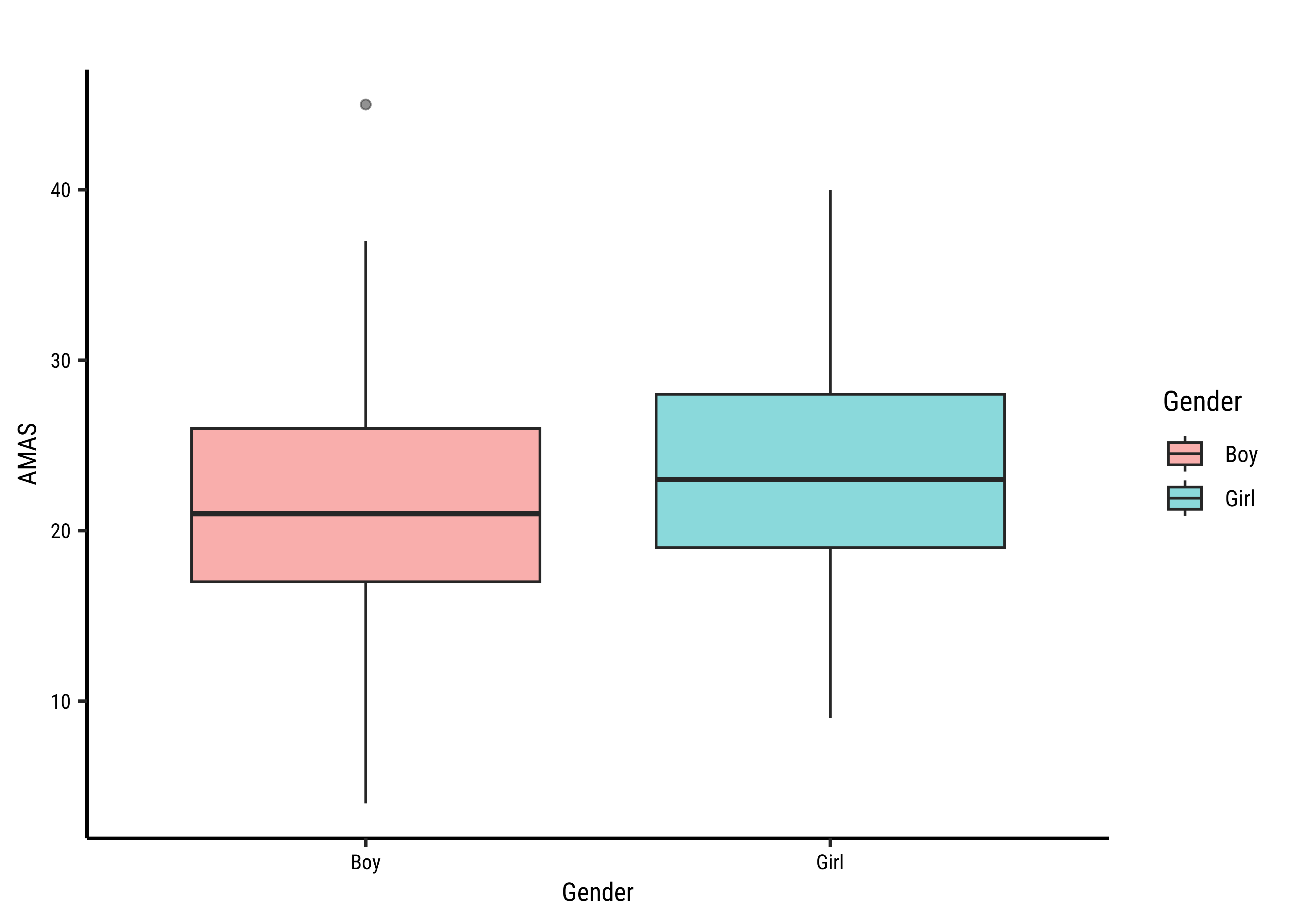
The distributions for anxiety scores for boys and girls overlap considerably and are very similar, though the boxplot for boys shows a significant outlier. Are they close to being normal distributions too? We should check.
A. Check for Normality
Statistical tests for means usually require a couple of checks12:
Are the data normally distributed?
Are the data variances similar?
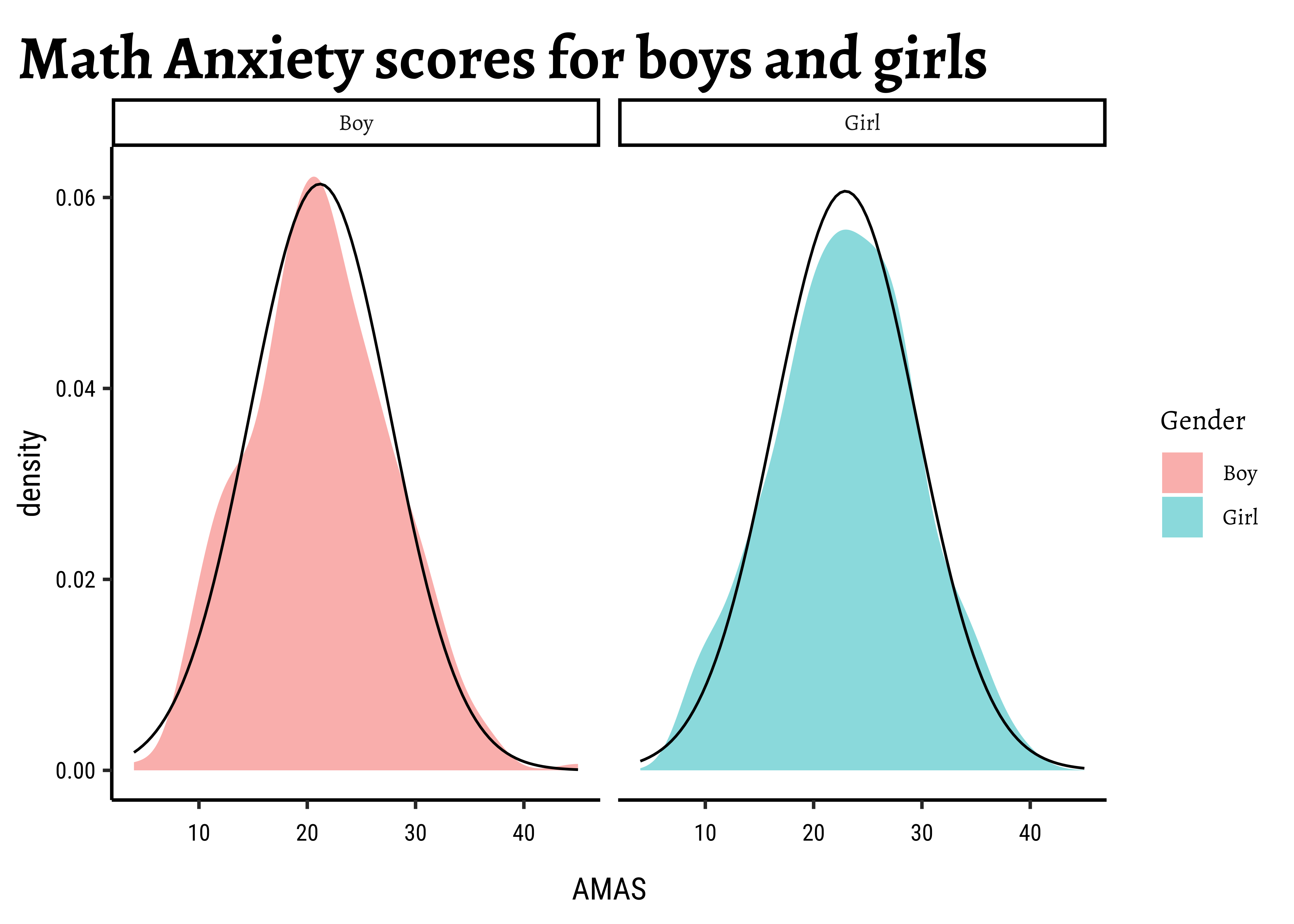
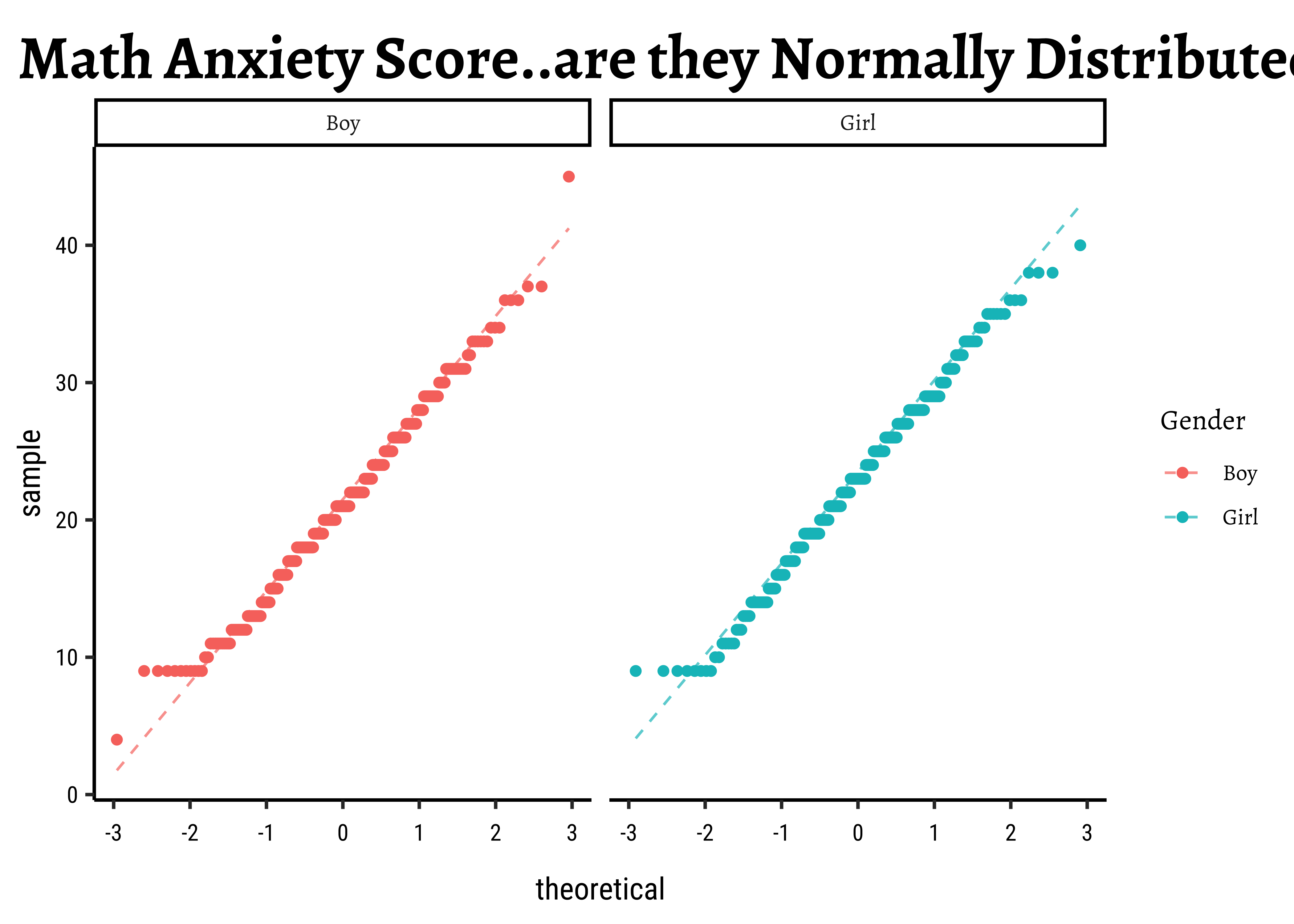
Let us complete a check for normality: the shapiro.wilk test checks whether a Quant variable is from a normal distribution; the NULL hypothesis is that the data are from a normal distribution. We will also look at Q-Q plots for both variables:
Show the Code
# Set graph themetheme_set(new =theme_custom())#MathAnxiety%>%gf_density(~AMAS, fill =~Gender, alpha =0.5, title ="Math Anxiety scores for boys and girls")%>%gf_facet_grid(~Gender)%>%gf_fitdistr(dist ="dnorm")##MathAnxiety%>%gf_qqline(~AMAS, color =~Gender, title ="Math Anxiety Score..are they Normally Distributed?")%>%gf_qq()%>%gf_facet_wrap(~Gender)# independent y-axis
Let us split the dataset into subsets, to execute the normality check test (Shapiro-Wilk test):
Shapiro-Wilk normality test
data: boys_AMAS$AMAS
W = 0.99043, p-value = 0.03343
Shapiro-Wilk normality test
data: girls_AMAS$AMAS
W = 0.99074, p-value = 0.07835
The distributions for anxiety scores for boys and girls are almost normal, visually speaking. With the Shapiro-Wilk test we find that the scores for girlsare normally distributed, but the boys scores are not so. Sigh.
Note
The p.value obtained in the shapiro.wilk test suggests the chances of the data being so, given the Assumption that they are normally distributed.
We see that MathAnxiety contains discrete-level scores for anxiety for the two variables (for Boys and Girls) anxiety scores. The boys score has a significant outlier, which we saw earlier and perhaps that makes that variable lose out, perhaps narrowly.
B. Check for Variances
Let us check if the two variables have similar variances: the var.test does this for us, with a NULL hypothesis that the variances are not significantly different:
Show the Code
var.test(AMAS~Gender, data =MathAnxiety, conf.int =TRUE, conf.level =0.95)%>%broom::tidy()
The variances are quite similar as seen by the . We also saw it visually when we plotted the overlapped distributions earlier.
Conditions:
The two variables are not both normally distributed.
The two variances are significantly similar.
Hypothesis
Based on the graphs, how would we formulate our Hypothesis? We wish to infer whether there is any difference in the mean anxiety score between Girls and Boys, in the population from which the dataset MathAnxiety has been drawn. So accordingly:
Observed and Test Statistic
What would be the test statistic we would use? The difference in means. Is the observed difference in the means between the two groups of scores non-zero? We use the diffmean function:
Show the Code
obs_diff_amas<-diffmean(AMAS~Gender, data =MathAnxiety)obs_diff_amas
diffmean
1.7676
Girls’ AMAS anxiety scores are, on average, points higher than those for Boys in the dataset/sample.
On Observed Difference Estimates
Different tests here will show the difference as positive or negative, but with the same value! This depends upon the way the factor variable Gender is used, i.e. Boy-Girl or Girl-Boy…
Since the data are not both normally distributed, though the variances similar, we typically cannot use a parametric t.test. However, we can still examine the results:
Show the Code
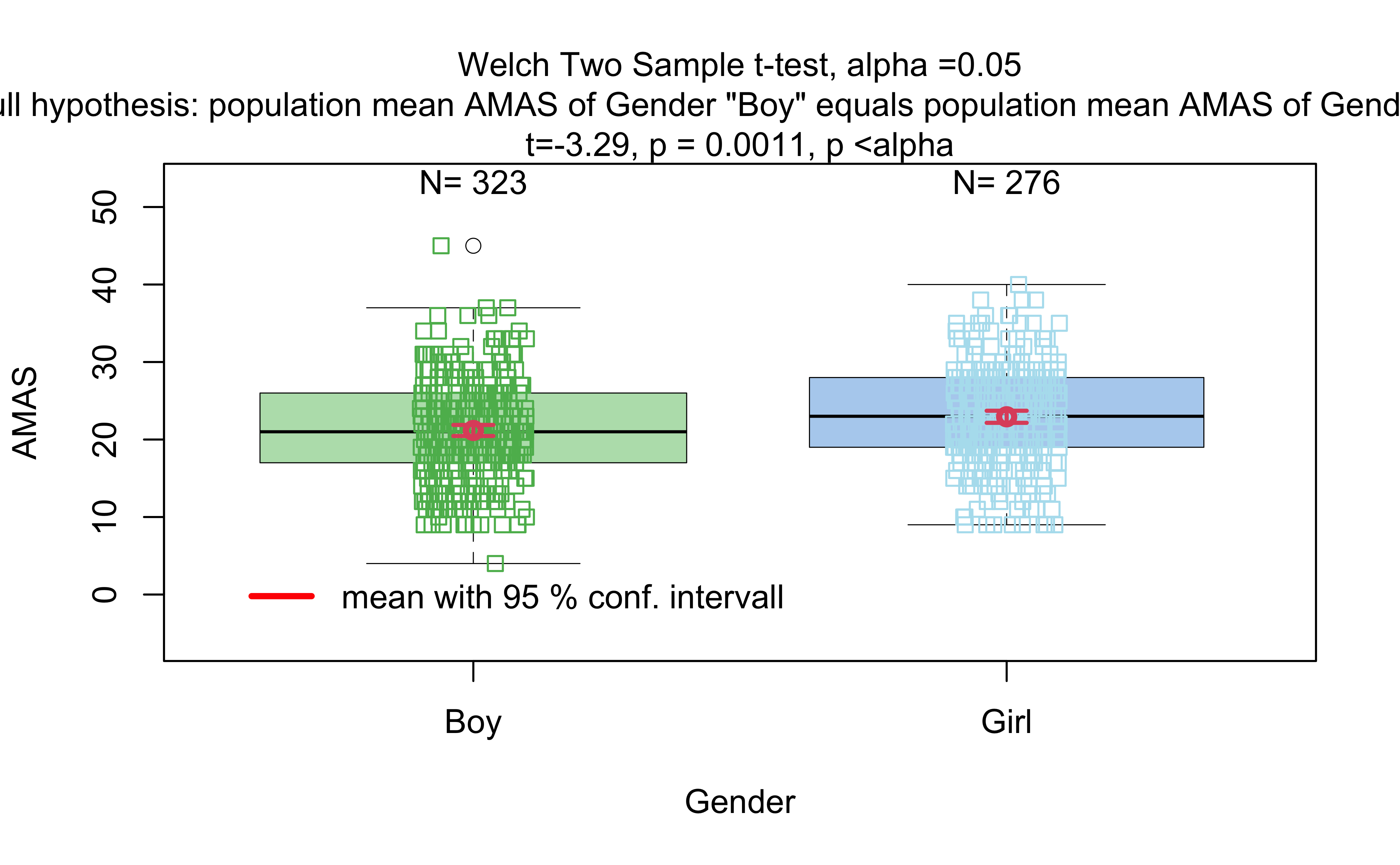
mosaic::t_test(AMAS~Gender, data =MathAnxiety)%>%broom::tidy()
ABCDEFGHIJ0123456789
estimate
<dbl>
estimate1
<dbl>
estimate2
<dbl>
statistic
<dbl>
p.value
<dbl>
parameter
<dbl>
conf.low
<dbl>
conf.high
<dbl>
method
<chr>
alternative
<chr>
-1.7676
21.16718
22.93478
-3.291843
0.001055808
580.2004
-2.822229
-0.7129706
Welch Two Sample t-test
two.sided
The p.value is ! And the Confidence Interval does not straddle . So the t.test gives us good reason to reject the Null Hypothesis that the means are similar and that there is a significant difference between Boys and Girls when it comes to AMAS anxiety. But can we really believe this, given the non-normality of data?
Since the data variables do not satisfy the assumption of being normally distributed, and though the variances are similar, we use the classical wilcox.test (Type help(wilcox.test) in your Console.) which implements what we need here: the Mann-Whitney U test:3
The Mann-Whitney test as a test of mean ranks. It first ranks all your values from high to low, computes the mean rank in each group, and then computes the probability that random shuffling of those values between two groups would end up with the mean ranks as far apart as, or further apart, than you observed. No assumptions about distributions are needed so far. (emphasis mine)
Show the Code
wilcox.test(AMAS~Gender, data =MathAnxiety, conf.int =TRUE, conf.level =0.95)%>%broom::tidy()
ABCDEFGHIJ0123456789
estimate
<dbl>
statistic
<dbl>
p.value
<dbl>
conf.low
<dbl>
conf.high
<dbl>
method
<chr>
alternative
<chr>
-1.999998
37483
0.0007736219
-2.999947
-0.9999882
Wilcoxon rank sum test with continuity correction
two.sided
The p.value is very similar, , and again the Confidence Interval does not straddle , and we are hence able to reject the NULL hypothesis that the means are equal and accept the alternative hypothesis that there is a significant difference in mean anxiety scores between Boys and Girls.
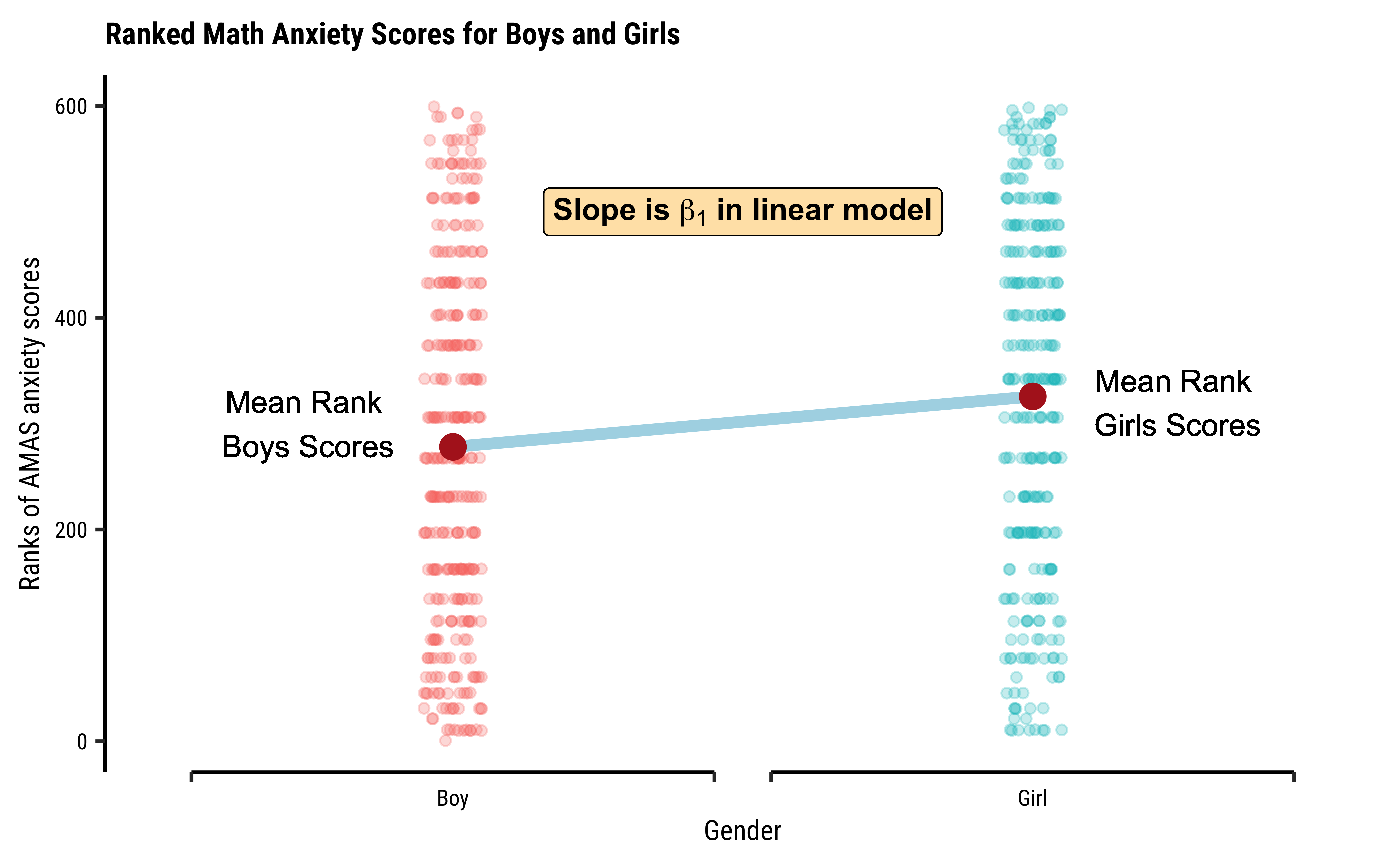
We can apply the linear-model-as-inference interpretation to the ranked data data to implement the non-parametric test as a Linear Model:
Show the Code
lm(rank(AMAS)~Gender, data =MathAnxiety)%>%broom::tidy( conf.int =TRUE, conf.level =0.95)
ABCDEFGHIJ0123456789
term
<chr>
estimate
<dbl>
std.error
<dbl>
statistic
<dbl>
p.value
<dbl>
conf.low
<dbl>
conf.high
<dbl>
(Intercept)
278.04644
9.535561
29.158898
6.848992e-117
259.31912
296.7738
GenderGirl
47.64559
14.047696
3.391701
7.405210e-04
20.05668
75.2345
Dummy Variables in lm
Note how the Qual variable was used here in Linear Regression! The Gender variable was treated as a binary “dummy” variable4.
Here too we see that the p.value for the slope term (“GenderGirl”) is significant at .
We pretend that Gender has no effect on the AMAS anxiety scores. If this is our position, then the Gender labels are essentially meaningless, and we can pretend that any AMAS score belongs to a Boy or a Girl. This means we can mosaic::shuffle (permute) the Gender labels and see how uncommon our real data is. And we do not have to really worry about whether the data are normally distributed, or if their variances are nearly equal.
Important
The “pretend” position is exactly the NULL Hypothesis!! The “uncommon” part is the p.value under NULL!!
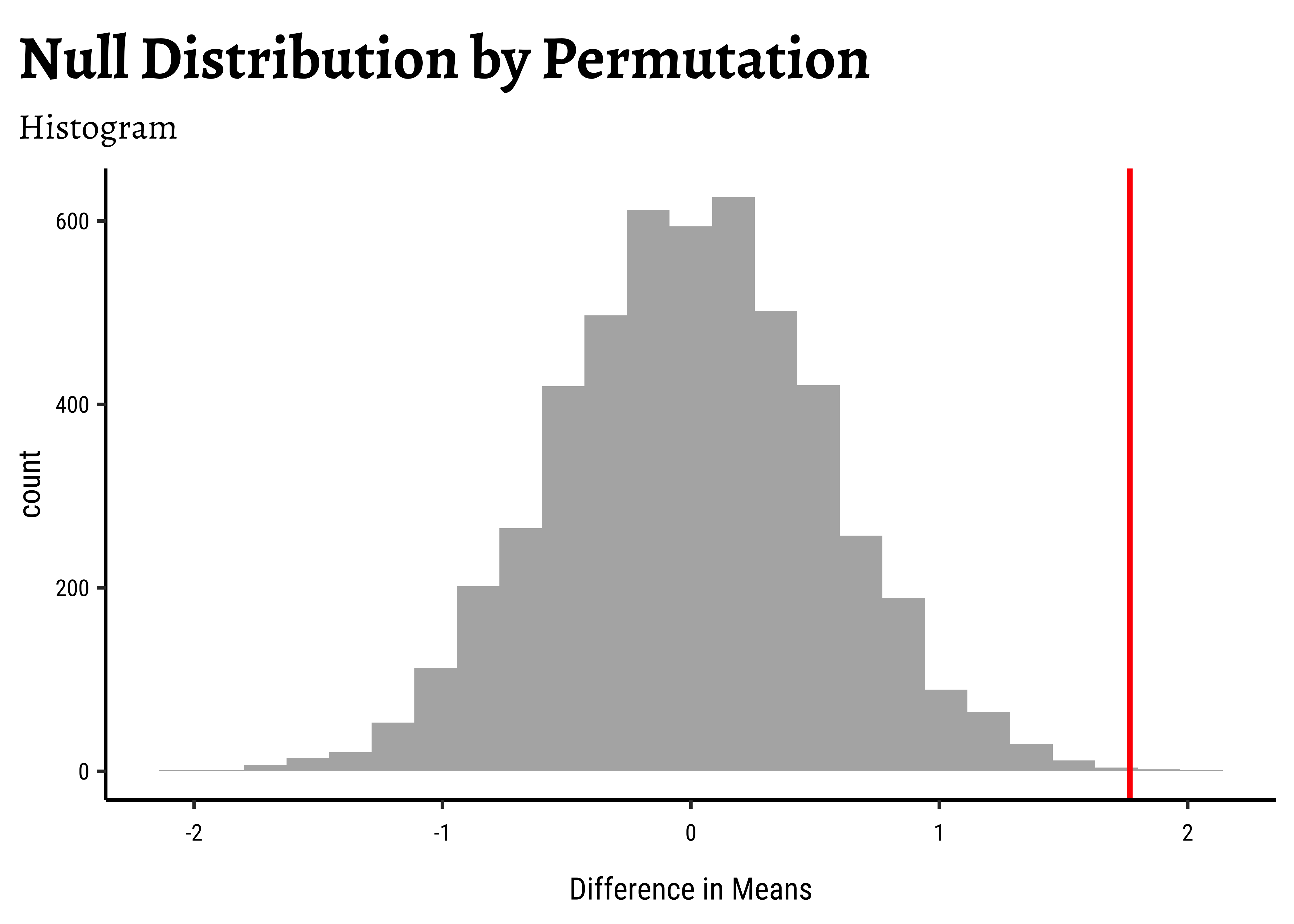
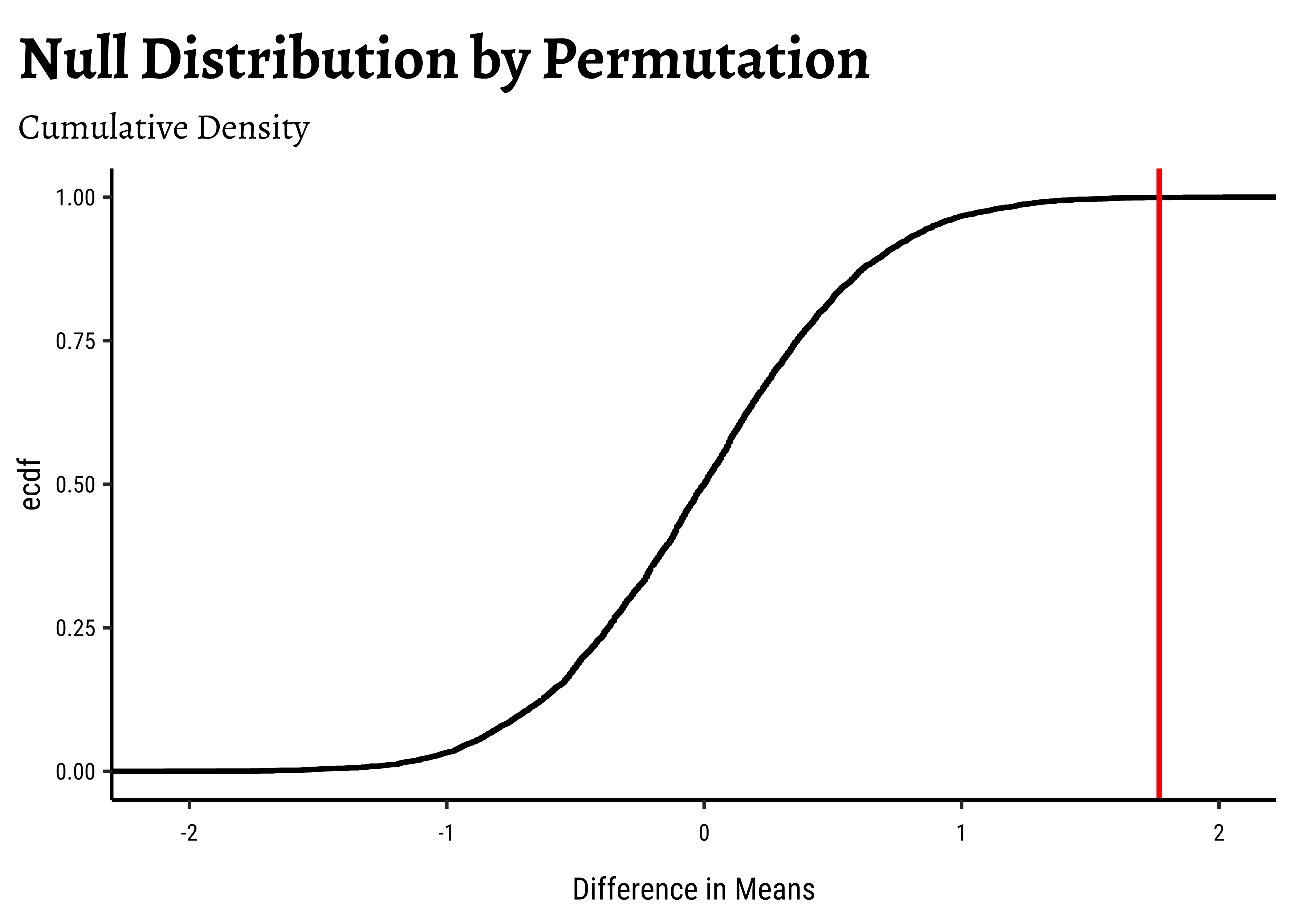
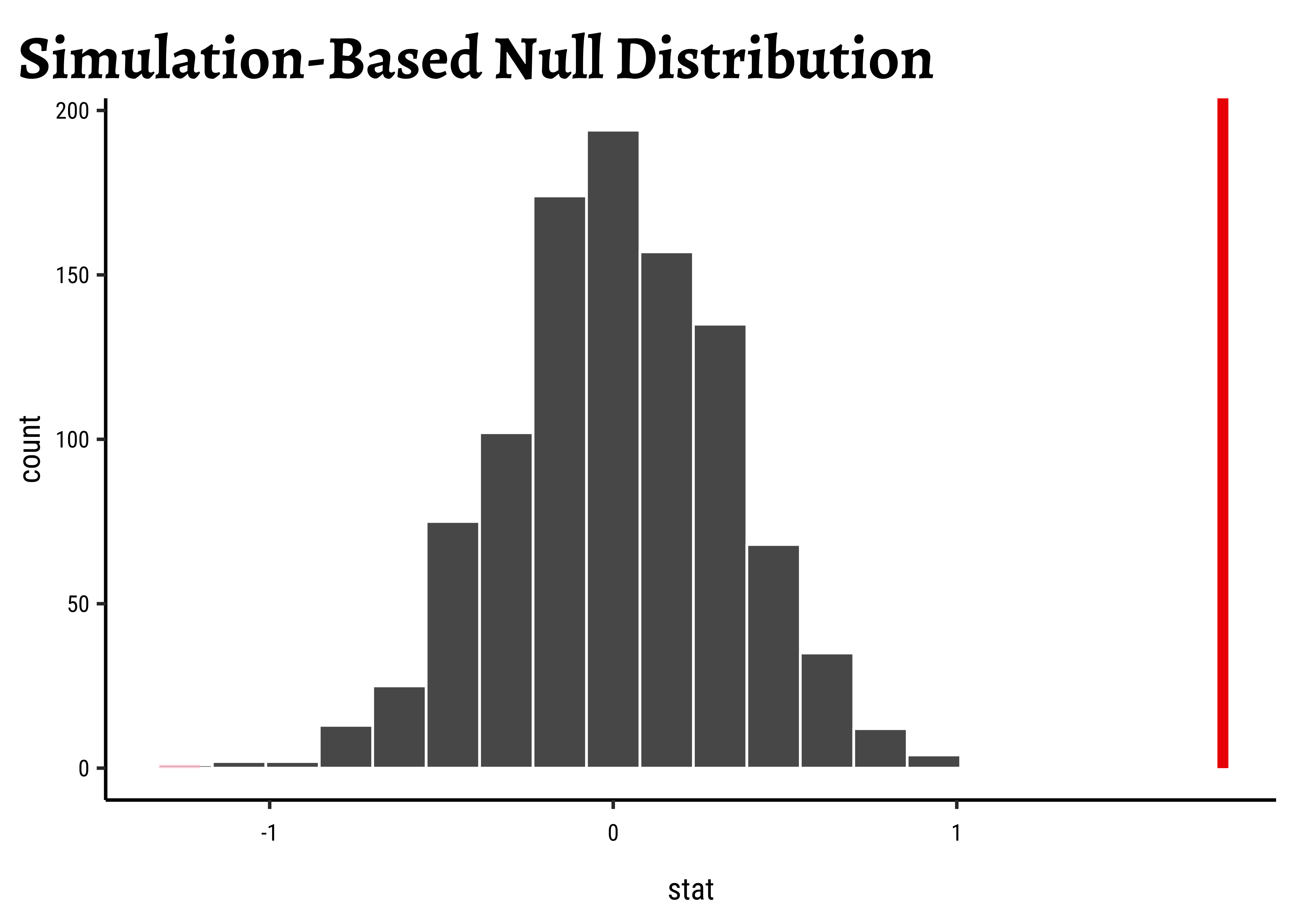
# Set graph themetheme_set(new =theme_custom())#gf_histogram(data =null_dist_amas, ~diffmean, bins =25)%>%gf_vline( xintercept =obs_diff_amas, colour ="red", linewidth =1, title ="Null Distribution by Permutation", subtitle ="Histogram")%>%gf_labs(x ="Difference in Means")###gf_ecdf( data =null_dist_amas, ~diffmean, linewidth =1)%>%gf_vline( xintercept =obs_diff_amas, colour ="red", linewidth =1, title ="Null Distribution by Permutation", subtitle ="Cumulative Density")%>%gf_labs(x ="Difference in Means")
Show the Code
1-prop1(~diffmean<=obs_diff_amas, data =null_dist_amas)
prop_TRUE
6e-04
Clearly the observed_diff_amas is much beyond anything we can generate with permutations with gender! And hence there is a significant difference in weights across gender!
All Tests Together
We can put all the test results together to get a few more insights about the tests:
As we can see, all tests are in agreement that there is a significant effect of Gender on the AMAS anxiety scores!
One Test to Rule Them All: visStatistics
We can use the visStatistics package to run all the tests in one go, using the in-built decision tree. This is a very useful package for teaching statistics, and it can be used to run all the tests we have seen so far, and more. Here goes: we use the visstat function to run all the tests, and then we can summarize the results. The visstat function takes a dataset, a quantitative variable, a qualitative variable, and some options for the tests to run.
From the visStatistics package documentation:
visStatistics automatically selects and visualises appropriate statistical hypothesis tests between two column vectors of type of class “numeric”, “integer”, or “factor”. The choice of test depends on the class, distribution, and sample size of the vectors, as well as the user-defined ‘conf.level’. The main function visstat() visualises the selected test with appropriate graphs (box plots, bar charts, regression lines with confidence bands, mosaic plots, residual plots, Q-Q plots), annotated with the main test results, including any assumption checks and post-hoc analyses.
Show the Code
# Generate the annotated plots and statisticsvisstat( x =MathAnxiety$Gender, y =MathAnxiety$AMAS, conf.level =0.95, numbers =TRUE)%>%summary()
Summary of visstat object
--- Named components ---
[1] "dependent variable (response)" "independent variables (features)"
[3] "t-test-statistics" "Shapiro-Wilk-test_sample1"
[5] "Shapiro-Wilk-test_sample2"
--- Contents ---
$dependent variable (response):
[1] "AMAS"
$independent variables (features):
[1] Boy Girl
Levels: Boy Girl
$t-test-statistics:
Welch Two Sample t-test
data: x1 and x2
t = -3.2918, df = 580.2, p-value = 0.001056
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-2.8222293 -0.7129706
sample estimates:
mean of x mean of y
21.16718 22.93478
$Shapiro-Wilk-test_sample1:
Shapiro-Wilk normality test
data: x
W = 0.99043, p-value = 0.03343
$Shapiro-Wilk-test_sample2:
Shapiro-Wilk normality test
data: x
W = 0.99074, p-value = 0.07835
--- Attributes ---
$plot_paths
character(0)
The tool runs the Welch t-test and declares the p-value to be significant. The Shapiro-Wilk test results here also confirm what we had performed earlier. Hence we can say that we may reject the NULL Hypothesis and state that there is a statistically significant difference in AMAS anxiety scores between Boys and Girls.
Case Study #2: Youth Risk Behavior Surveillance System (YRBSS) survey
Every two years, the Centers for Disease Control and Prevention in the USA conduct the Youth Risk Behavior Surveillance System (YRBSS) survey, where it takes data from highschoolers (9th through 12th grade), to analyze health patterns. We will work with a selected group of variables from a random sample of observations during one of the years the YRBSS was conducted.The yrbss dataset is part of the openintro package. Type this in your console: help(yrbss).
We have 13K data entries, and with 13 different variables, some Qual and some Quant. Many entries are missing too, typical of real-world data and something we will have to account for in our computations. The meaning of each variable can be found by bringing up the help file.
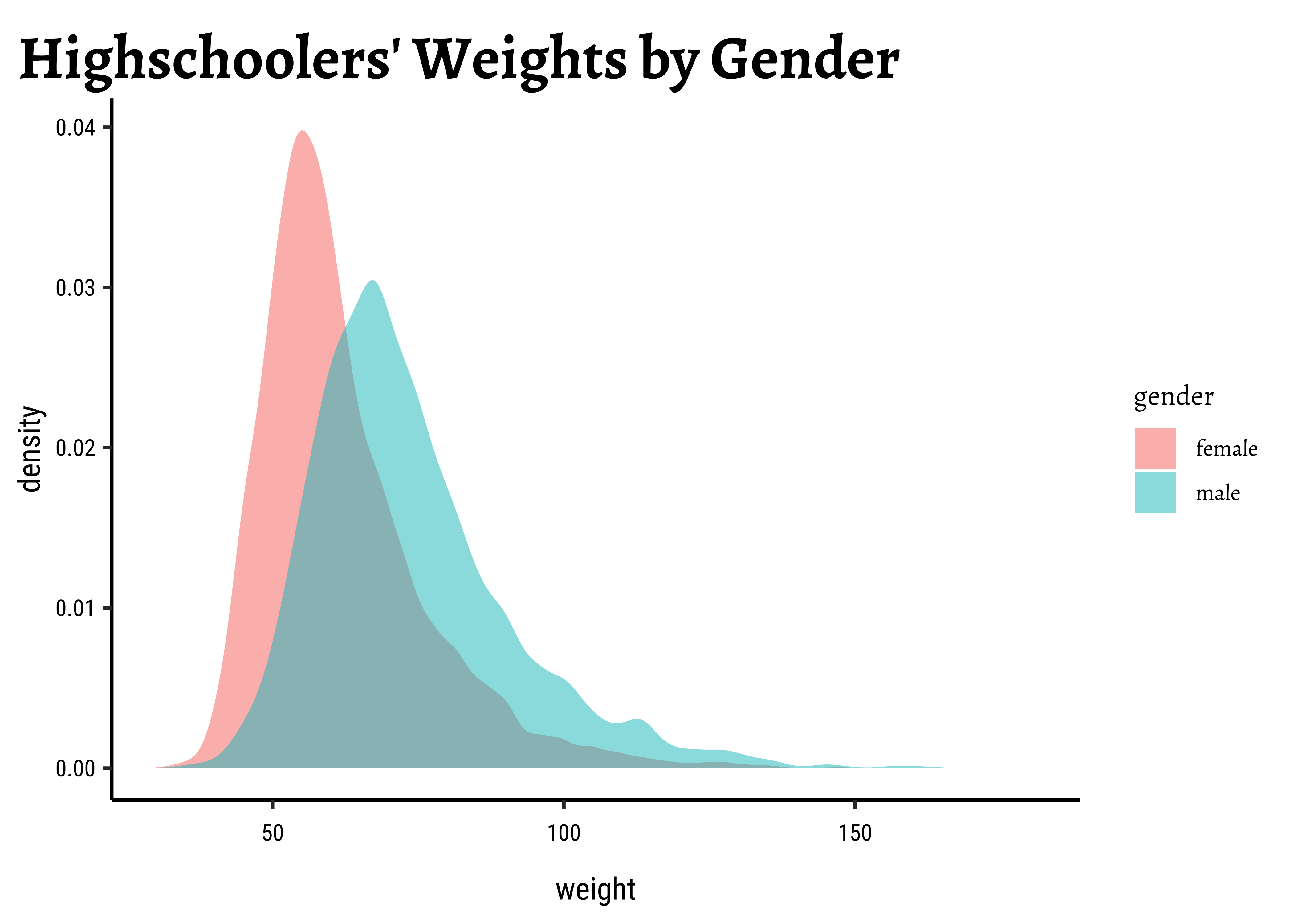
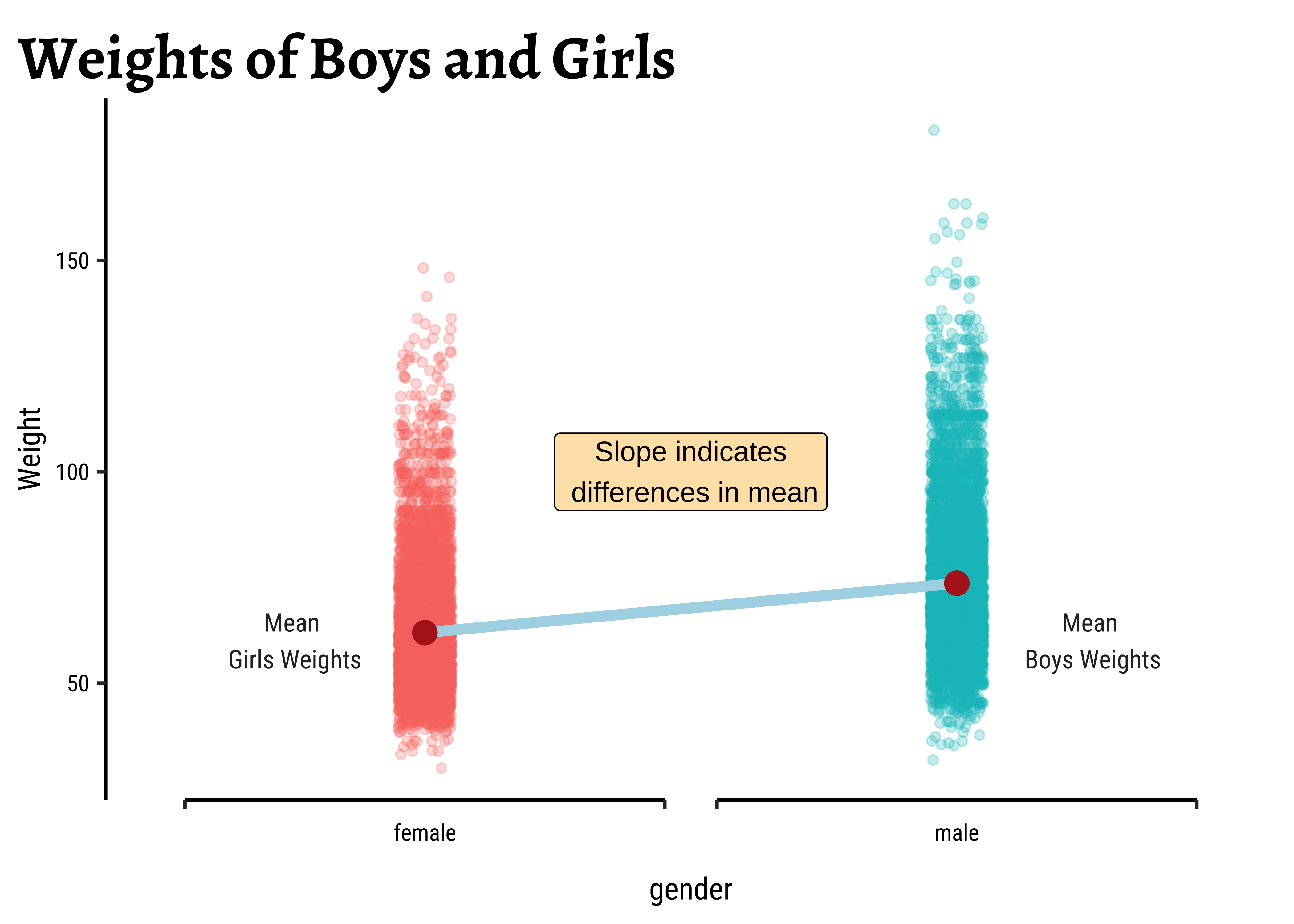
# Set graph themetheme_set(new =theme_custom())##yrbss_select_gender%>%gf_density(~weight, fill =~gender, alpha =0.5, title ="Highschoolers' Weights by Gender")###yrbss_select_gender%>%gf_jitter(weight~gender, color =~gender, show.legend =FALSE, width =0.05, alpha =0.25, ylab ="Weight", title ="Weights of Boys and Girls")%>%gf_summary( group =~1, # See the reference link above. Damn!!! fun ="mean", geom ="line", colour ="lightblue", lty =1, linewidth =2)%>%gf_summary( fun ="mean", colour ="firebrick", size =4, geom ="point")%>%gf_refine(scale_x_discrete( breaks =c("male", "female"), labels =c("male", "female"), guide ="prism_bracket"))%>%gf_refine(annotate(x =0.75, y =60, geom ="text", label ="Mean\n Girls Weights"),annotate(x =2.25, y =60, geom ="text", label ="Mean\n Boys Weights"),annotate(x =1.5, y =100, geom ="label", label ="Slope indicates\n differences in mean", fill ="moccasin"))
Overlapped Distribution plot shows some difference in the means; and the Boxplots show visible difference in the medians. In this Case Study, our research question is:
Hypothesis
Research Question
Does weight of highschoolers in this dataset vary with gender?
Based on the graphs, how would we formulate our Hypothesis? We wish to infer whether there is difference in mean weight across gender. So accordingly:
A. Check for Normality
As stated before, statistical tests for means usually require a couple of checks:
Are the data normally distributed?
Are the data variances similar?
We will complete a visual check for normality with plots, and since we cannot do a shapiro.test (length(data) >= 5000) we can use the Anderson-Darling test.
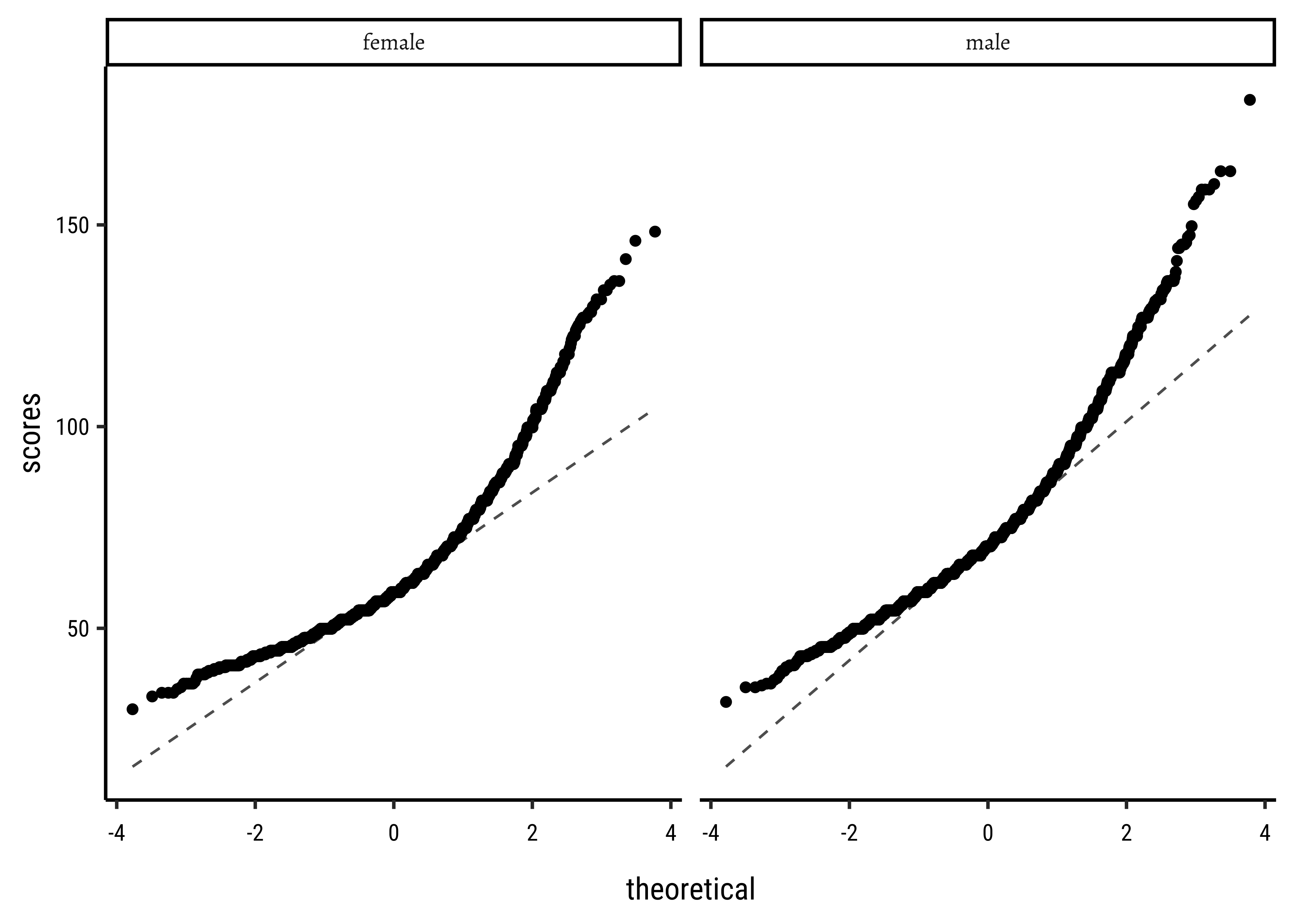
Let us plot frequency distribution and Q-Q plots5 for both variables.
Show the Code
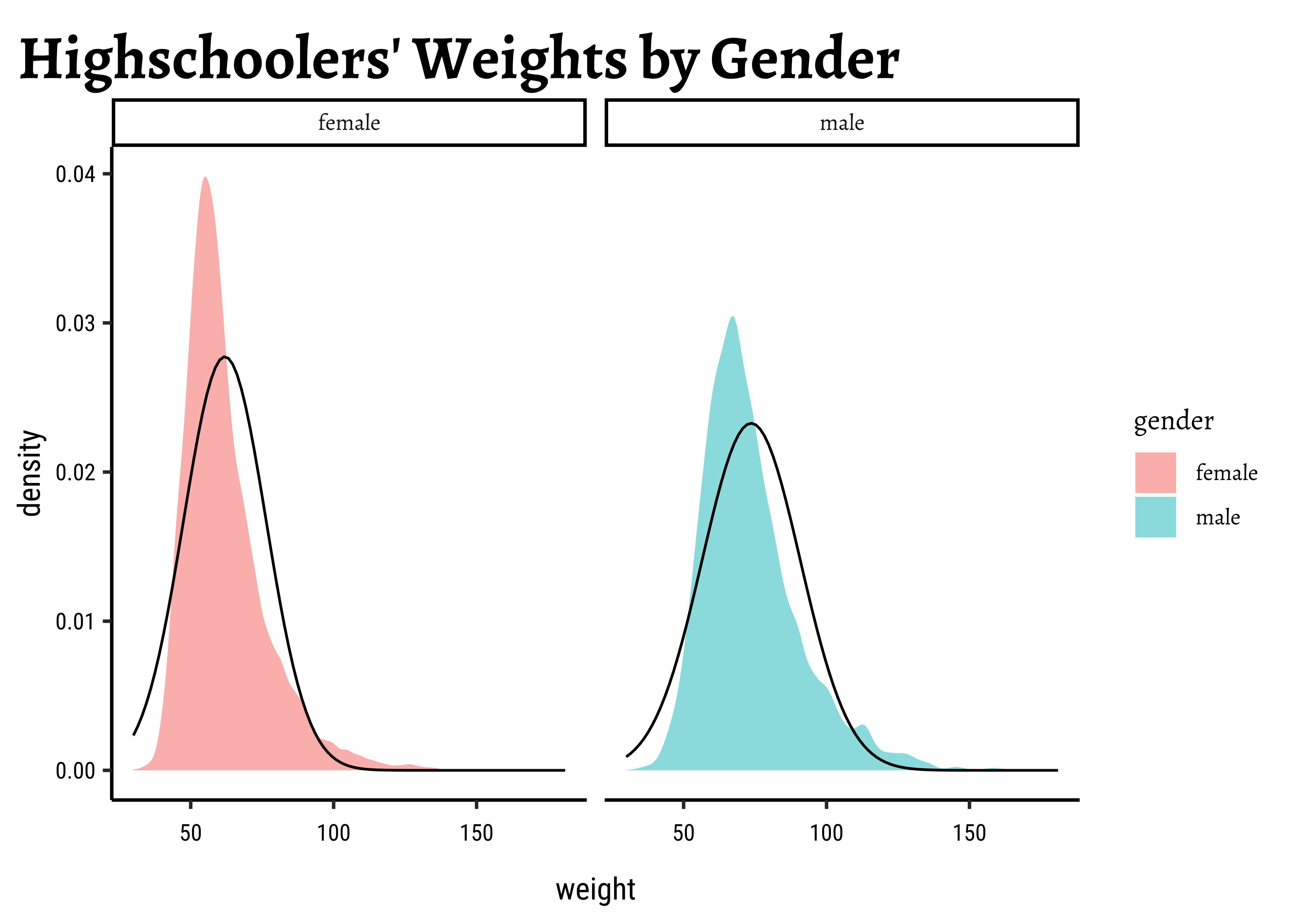
# Set graph themetheme_set(new =theme_custom())#male_student_weights<-yrbss_select_gender%>%filter(gender=="male")%>%select(weight)##female_student_weights<-yrbss_select_gender%>%filter(gender=="female")%>%select(weight)# shapiro.test(male_student_weights$weight)# shapiro.test(female_student_weights$weight)yrbss_select_gender%>%gf_density(~weight, fill =~gender, alpha =0.5, title ="Highschoolers' Weights by Gender")%>%gf_facet_grid(~gender)%>%gf_fitdistr(dist ="dnorm")##yrbss_select_gender%>%gf_qqline(~weight|gender, ylab ="scores")%>%gf_qq()
Distributions are not too close to normal…perhaps a hint of a rightward skew, suggesting that there are some obese students.
No real evidence (visually) of the variables being normally distributed.
Anderson-Darling normality test
data: female_student_weights$weight
A = 157.17, p-value < 2.2e-16
p-values are very low and there is no reason to think that the data is normal.
B. Check for Variances
Let us check if the two variables have similar variances: the var.testdoes this for us, with a NULL hypothesis that the variances are not significantly different:
Show the Code
var.test(weight~gender, data =yrbss_select_gender, conf.int =TRUE, conf.level =0.95)%>%broom::tidy()# qf(0.975,6164, 6413)
ABCDEFGHIJ0123456789
estimate
<dbl>
num.df
<int>
den.df
<int>
statistic
<dbl>
p.value
<dbl>
conf.low
<dbl>
conf.high
<dbl>
method
<chr>
alternative
<chr>
0.703976
6164
6413
0.703976
1.065068e-43
0.6700221
0.7396686
F test to compare two variances
two.sided
The p.value being so small, we are able to reject the NULL Hypothesis that the variances of weight are nearly equal across the two exercise regimes.
Conditions
The two variables are not normally distributed.
The two variances are also significantly different.
This means that the parametric t.test must be eschewed in favour of the non-parametric wilcox.test. We will use that, and also attempt linear models with rank data, and a final permutation test.
Observed and Test Statistic
What would be the test statistic we would use? The difference in means. Is the observed difference in the means between the two groups of scores non-zero? We use the diffmean function, from mosaic:
Show the Code
obs_diff_gender<-diffmean(weight~gender, data =yrbss_select_gender)obs_diff_gender
Since the data variables do not satisfy the assumption of being normally distributed, and the variances are significantly different, we use the classical wilcox.test, which implements what we need here: the Mann-Whitney U test,
Our model would be:
Recall the earlier graph showing ranks of anxiety-scores against Gender.
Show the Code
wilcox.test(weight~gender, data =yrbss_select_gender, conf.int =TRUE, conf.level =0.95)%>%broom::tidy()
ABCDEFGHIJ0123456789
estimate
<dbl>
statistic
<dbl>
p.value
<dbl>
conf.low
<dbl>
conf.high
<dbl>
method
<chr>
alternative
<chr>
-11.33999
10808212
0
-11.34003
-10.87994
Wilcoxon rank sum test with continuity correction
two.sided
The p.value is negligible and we are able to reject the NULL hypothesis that the means are equal.
We can apply the linear-model-as-inference interpretation to the ranked data data to implement the non-parametric test as a Linear Model:
Show the Code
# Create a sign-rank function# signed_rank <- function(x) {sign(x) * rank(abs(x))}lm(rank(weight)~gender, data =yrbss_select_gender)%>%broom::tidy( conf.int =TRUE, conf.level =0.95)
ABCDEFGHIJ0123456789
term
<chr>
estimate
<dbl>
std.error
<dbl>
statistic
<dbl>
p.value
<dbl>
conf.low
<dbl>
conf.high
<dbl>
(Intercept)
4836.157
42.52745
113.71848
0
4752.797
4919.517
gendermale
2851.246
59.55633
47.87478
0
2734.507
2967.986
Dummy Variables in lm
Note how the Qual variable was used here in Linear Regression lm()! The gender variable was treated as a binary “dummy” variable6.
For the specific data at hand, we need to shuffle the gender and take the test statistic (difference in means) each time.
Show the Code
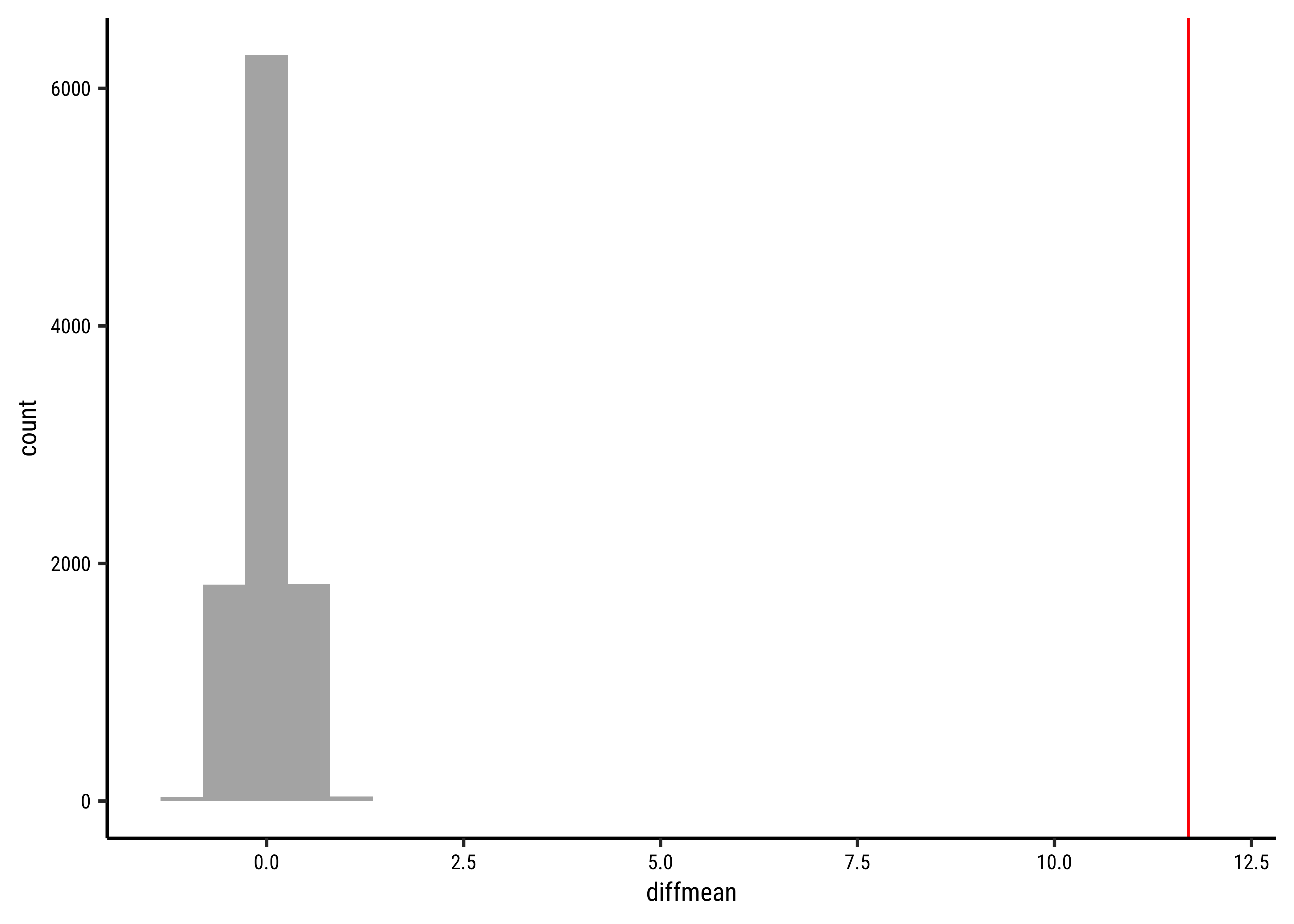
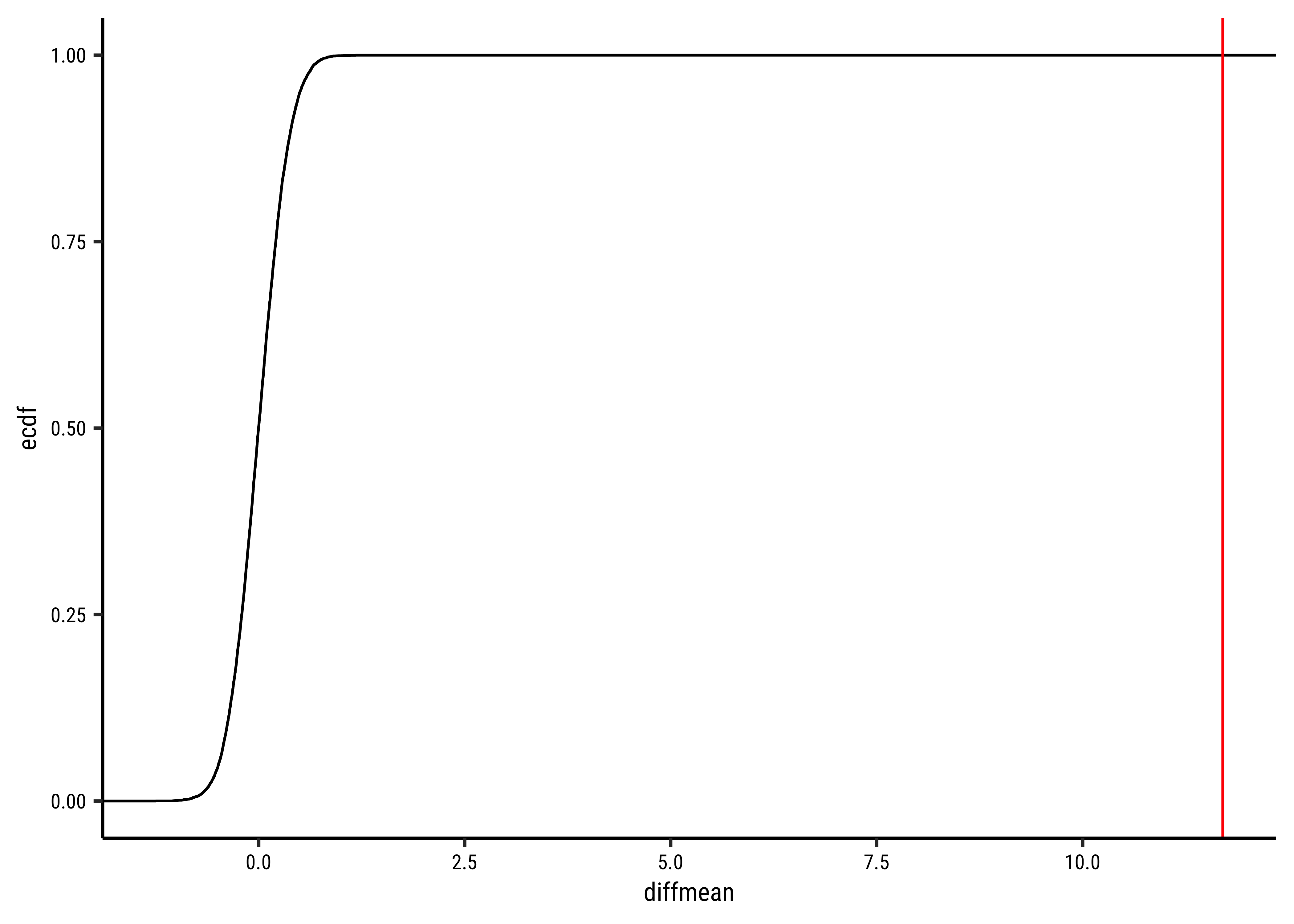
# Set graph themetheme_set(new =theme_custom())#null_dist_weight<-do(4999)*diffmean( data =yrbss_select_gender,weight~shuffle(gender))null_dist_weight###prop1(~diffmean<=obs_diff_gender, data =null_dist_weight)###gf_histogram( data =null_dist_weight, ~diffmean, bins =25)%>%gf_vline( xintercept =obs_diff_gender, colour ="red", linewidth =1, title ="Null Distribution by Permutation", subtitle ="Histogram")%>%gf_labs(x ="Difference in Means")###gf_ecdf( data =null_dist_weight, ~diffmean, linewidth =1)%>%gf_vline( xintercept =obs_diff_gender, colour ="red", linewidth =1, title ="Null Distribution by Permutation", subtitle ="Cumulative Density")%>%gf_labs(x ="Difference in Means")
ABCDEFGHIJ0123456789
diffmean
<dbl>
-0.2345205804
0.1880728637
0.1366527631
-0.3294238136
0.3835640444
0.4474192585
0.3019771030
0.5668427922
-0.2891440986
0.1880665014
prop_TRUE
1
Clearly the observed_diff_weight is much beyond anything we can generate with permutations with gender! And hence there is a significant difference in weights across gender!
All Tests Together
We can put all the test results together to get a few more insights about the tests:
The wilcox.test and the linear model with rank data offer the same results. This is of course not surprising!
One Test to Rule Them All: visStatistics again
We need to use a smaller sample of the dataset yrbss_select_gender, for the (same) reason: visstat() defaults to using the shapiro.wilk test internally:
Show the Code
yrbss_select_gender_sample<-yrbss_select_gender%>%slice_sample(n =4999)visstat( x =yrbss_select_gender_sample$gender, y =yrbss_select_gender_sample$weight, conf.level =0.95, numbers =TRUE)%>%summary()
Summary of visstat object
--- Named components ---
[1] "dependent variable (response)" "independent variables (features)"
[3] "t-test-statistics" "Shapiro-Wilk-test_sample1"
[5] "Shapiro-Wilk-test_sample2"
--- Contents ---
$dependent variable (response):
[1] "weight"
$independent variables (features):
[1] male female
Levels: female male
$t-test-statistics:
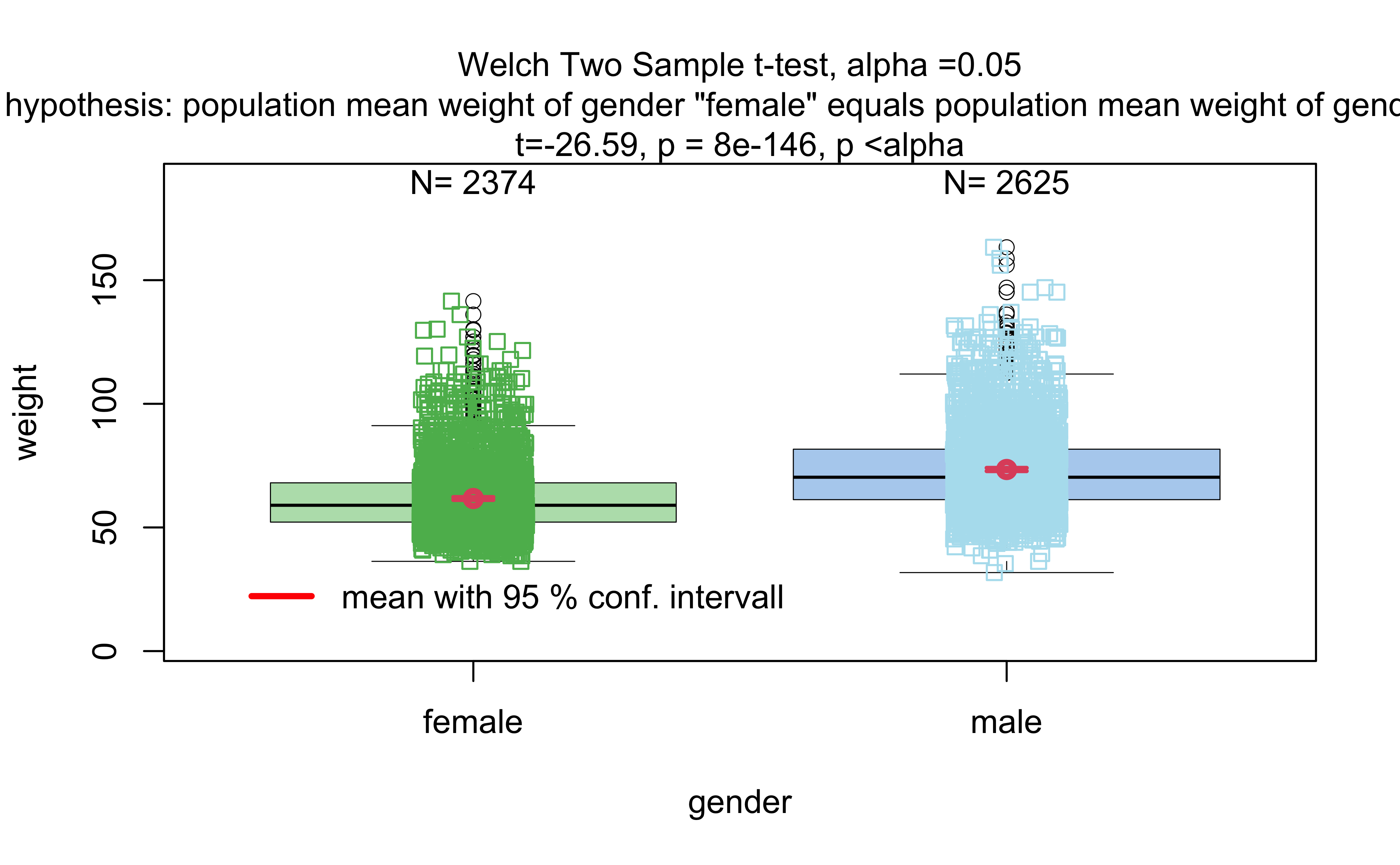
Welch Two Sample t-test
data: x1 and x2
t = -26.238, df = 4920, p-value < 2.2e-16
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-12.87028 -11.08069
sample estimates:
mean of x mean of y
62.05522 74.03070
$Shapiro-Wilk-test_sample1:
Shapiro-Wilk normality test
data: x
W = 0.88784, p-value < 2.2e-16
$Shapiro-Wilk-test_sample2:
Shapiro-Wilk normality test
data: x
W = 0.93506, p-value < 2.2e-16
--- Attributes ---
$plot_paths
character(0)
Compare these results with those calculated earlier!
Case Study #3: Weight vs Exercise in the YRBSS Survey
Finally, consider the possible relationship between a highschooler’s weight and their physical activity.
First, let’s create a new variable physical_3plus, which will be coded as either “yes” if the student is physically active for at least 3 days a week, and “no” if not. Recall that we have several missing data in that column, so we will (sadly) drop these before generating the new variable:
Show the Code
yrbss_select_phy<-yrbss%>%drop_na(physically_active_7d, weight)%>%## add new variable physical_3plusmutate( physical_3plus =if_else(physically_active_7d>=3,"yes", "no"),# Convert it to a factor Y/N physical_3plus =factor(physical_3plus, labels =c("yes", "no"), levels =c("yes", "no")))%>%select(weight, physical_3plus)# Let us checkyrbss_select_phy%>%count(physical_3plus)
ABCDEFGHIJ0123456789
physical_3plus
<fct>
n
<int>
yes
8342
no
4022
Research Question
Does weight vary based on whether students exercise on more or less than 3 days a week? (physically_active_7d >= 3 days)
Inspecting and Charting Data
We can make distribution plots for weight by physical_3plus:
Show the Code
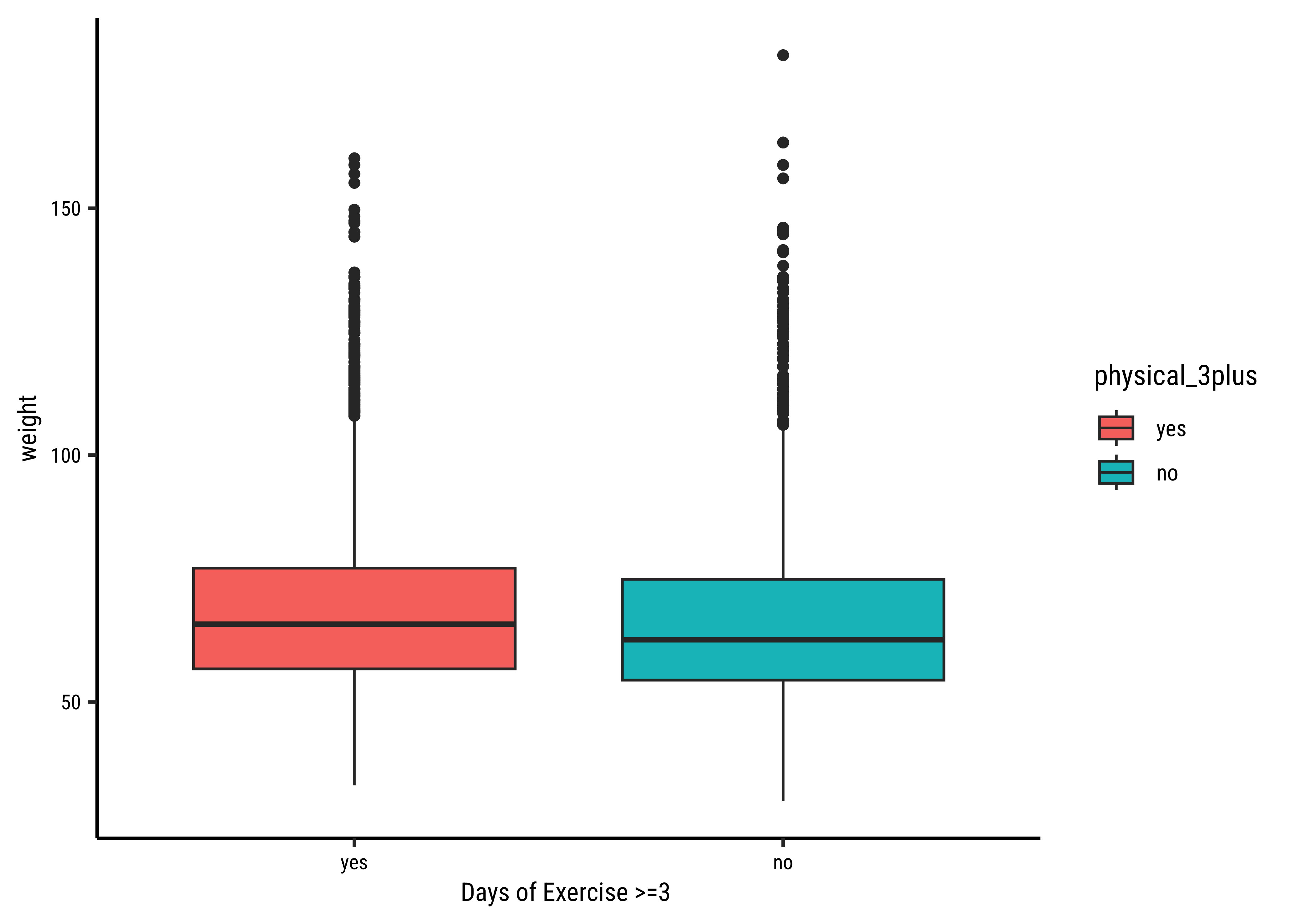
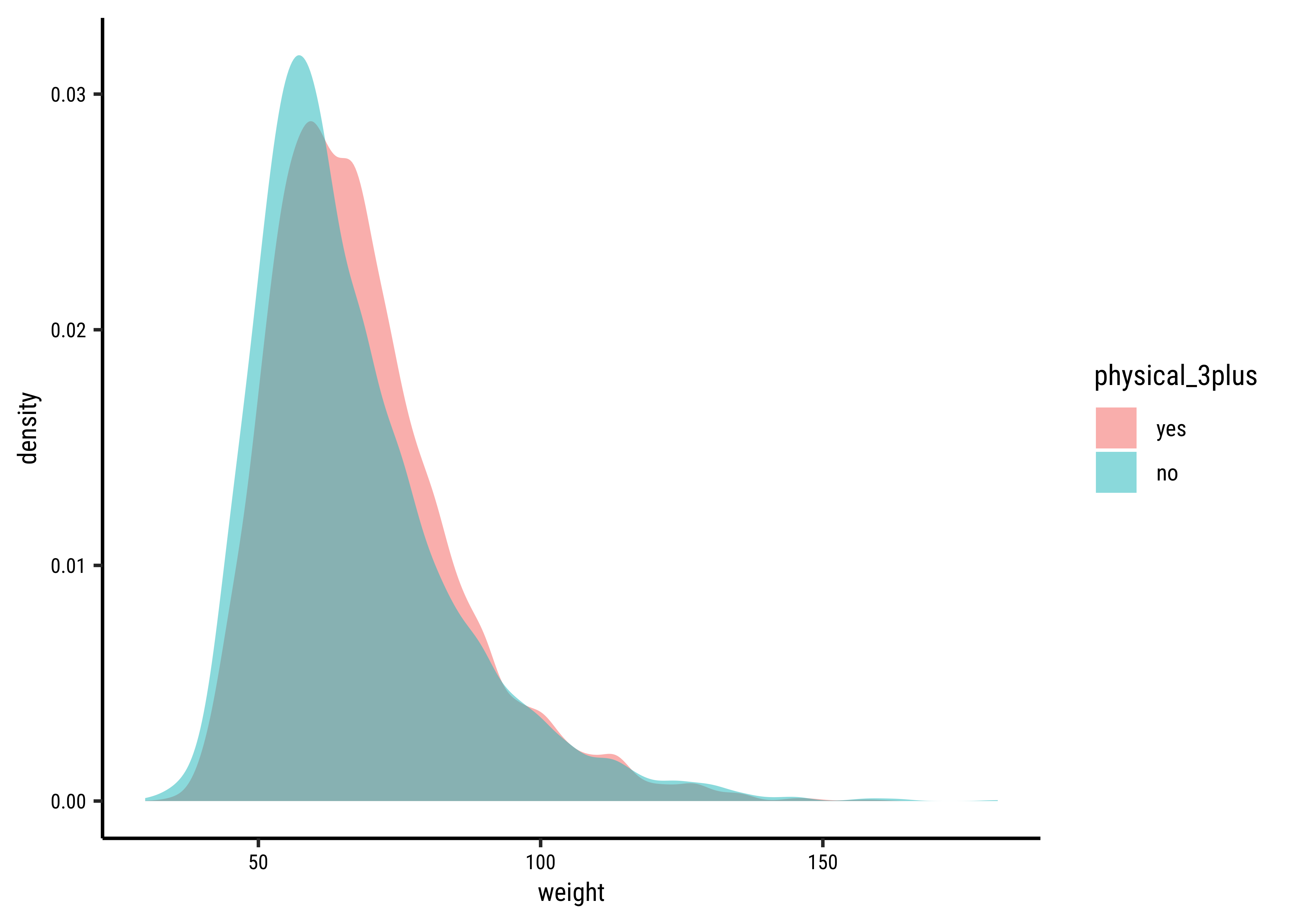
# Set graph themetheme_set(new =theme_custom())###yrbss_select_phy%>%gf_jitter(weight~physical_3plus, group =~physical_3plus, width =0.08, alpha =0.08, xlab ="Days of Exercise >=3")%>%gf_summary( geom ="point", size =3, group =~physical_3plus, colour =~physical_3plus)%>%gf_line( group =1, # weird remedy to fix groups error message! stat ="summary", linewidth =1, geom ="line", colour =~"MeanDifferenceLine")###gf_density(~weight, fill =~physical_3plus, data =yrbss_select_phy)
The jitter and density plots show the comparison between the two means. We can also compare the means of the distributions using the following to first group the data by the physical_3plus variable, and then calculate the mean weight in these groups using the mean function while ignoring missing values by setting the na.rm argument to TRUE.
There is an observed difference, but is this difference large enough to deem it “statistically significant”? In order to answer this question we will conduct a hypothesis test. But before that a few more checks on the data:
A. Check for Normality
As stated before, statistical tests for means usually require a couple of checks:
Are the data normally distributed?
Are the data variances similar?
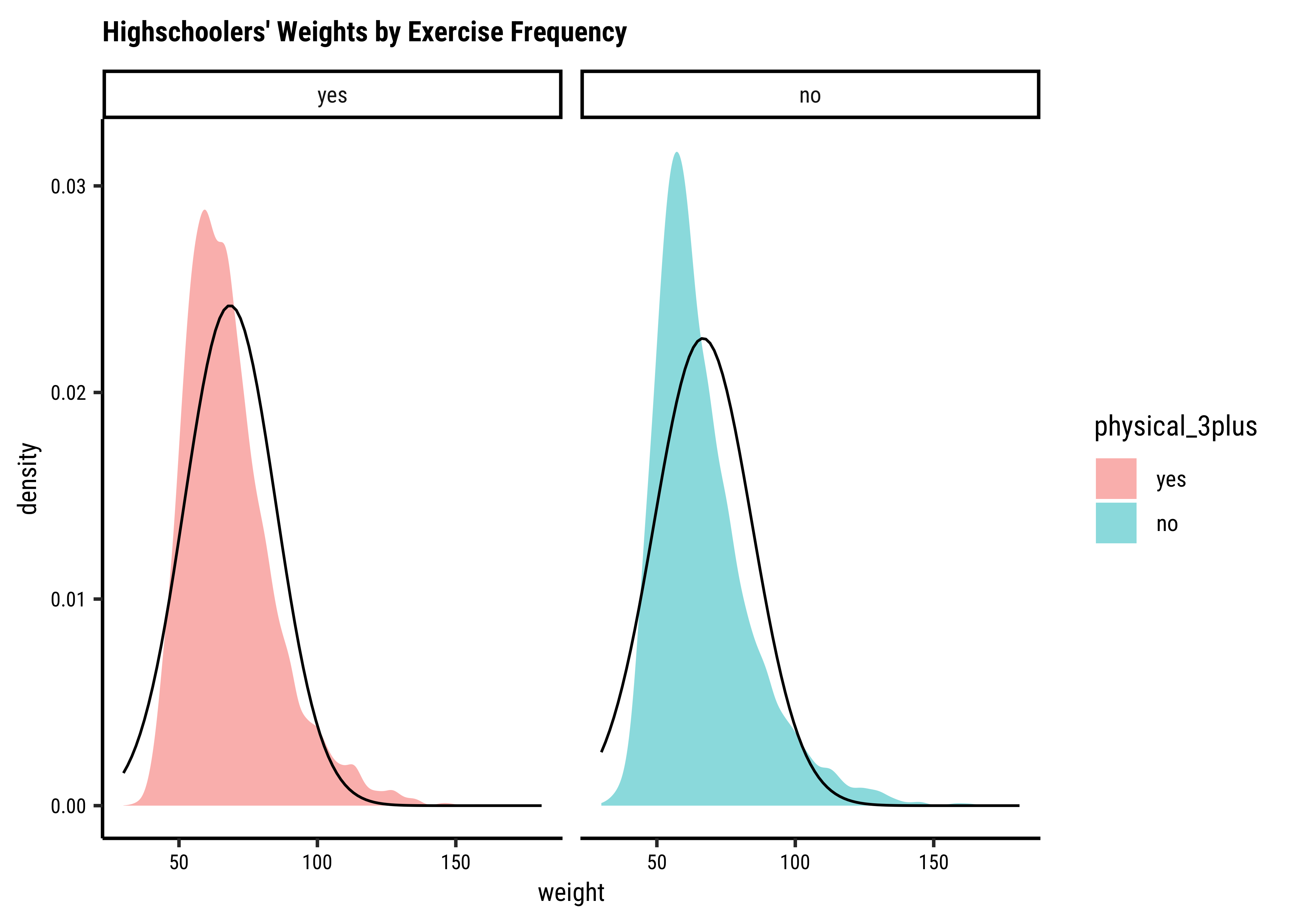
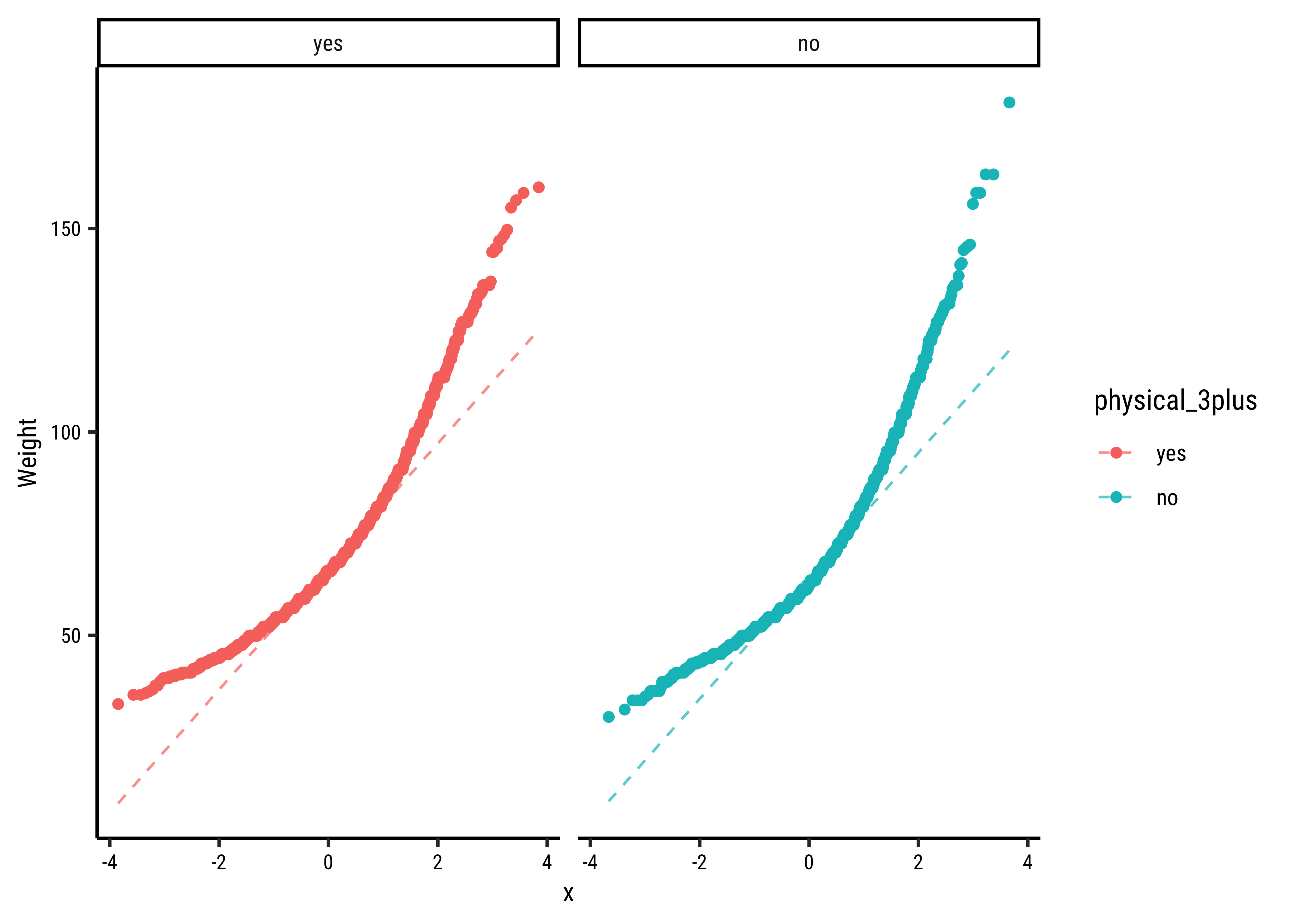
Let us also complete a visual check for normality,with plots since we cannot do a shapiro.test:
Show the Code
# Set graph themetheme_set(new =theme_custom())#yrbss_select_phy%>%gf_density(~weight, fill =~physical_3plus, alpha =0.5, title ="Highschoolers' Weights by Exercise Frequency")%>%gf_facet_grid(~physical_3plus)%>%gf_fitdistr(dist ="dnorm")##yrbss_select_phy%>%gf_qq(~weight|physical_3plus, color =~physical_3plus)%>%gf_qqline(ylab ="Weight")
Again, not normally distributed…
B. Check for Variances
Let us check if the two variables have similar variances: the var.test does this for us, with a NULL hypothesis that the variances are not significantly different:
Show the Code
var.test(weight~physical_3plus, data =yrbss_select_phy, conf.int =TRUE, conf.level =0.95)%>%broom::tidy()# Critical F valueqf(0.975, 4021, 8341)
ABCDEFGHIJ0123456789
estimate
<dbl>
num.df
<int>
den.df
<int>
statistic
<dbl>
p.value
<dbl>
conf.low
<dbl>
conf.high
<dbl>
method
<chr>
alternative
<chr>
0.8728201
8341
4021
0.8728201
4.390179e-07
0.8273749
0.9202997
F test to compare two variances
two.sided
[1] 1.054398
The p.value states the probability of the data being what it is, assuming the NULL hypothesis that variances were similar. It being so small, we are able to reject this NULL Hypothesis that the variances of weight are nearly equal across the two exercise frequencies. (Compare the statistic in the var.test with the critical F-value)
Conditions
The two variables are not normally distributed.
The two variances are also significantly different.
Hence we will have to use non-parametric tests to infer if the means are similar.
Hypothesis
Based on the graphs, how would we formulate our Hypothesis? We wish to infer whether there is difference in mean weight across physical_3plus. So accordingly:
Observed and Test Statistic
What would be the test statistic we would use? The difference in means. Is the observed difference in the means between the two groups of scores non-zero? We use the diffmean function, from mosaic:
Show the Code
obs_diff_phy<-diffmean(weight~physical_3plus, data =yrbss_select_phy)obs_diff_phy
Well, the variables are not normally distributed, and the variances are significantly different so a standard t.test is not advised. We can still try:
Show the Code
mosaic::t_test(weight~physical_3plus, var.equal =FALSE, # Welch Correction data =yrbss_select_phy)%>%broom::tidy()
ABCDEFGHIJ0123456789
estimate
<dbl>
estimate1
<dbl>
estimate2
<dbl>
statistic
<dbl>
p.value
<dbl>
parameter
<dbl>
conf.low
<dbl>
conf.high
<dbl>
method
<chr>
alternative
<chr>
1.774584
68.44847
66.67389
5.353003
8.907531e-08
7478.84
1.124728
2.424441
Welch Two Sample t-test
two.sided
The p.value is ! And the Confidence Interval is clear of . So the t.test gives us good reason to reject the Null Hypothesis that the means are similar. But can we really believe this, given the non-normality of data?
However, we have seen that the data variables are not normally distributed. So a Wilcoxon Test, using signed-ranks, is indicated: (recall the model!)
Show the Code
# For stability reasons, it may be advisable to use rounded data or to set digits.rank = 7, say,# such that determination of ties does not depend on very small numeric differences (see the example).wilcox.test(weight~physical_3plus, conf.int =TRUE, conf.level =0.95, data =yrbss_select_phy)%>%broom::tidy()
ABCDEFGHIJ0123456789
estimate
<dbl>
statistic
<dbl>
p.value
<dbl>
conf.low
<dbl>
conf.high
<dbl>
method
<chr>
alternative
<chr>
2.269967
18314392
1.262977e-16
1.819992
2.720077
Wilcoxon rank sum test with continuity correction
two.sided
The nonparametric wilcox.test also suggests that the means for weight across physical_3plus are significantly different.
We can apply the linear-model-as-inference interpretation to the ranked data data to implement the non-parametric test as a Linear Model:
Show the Code
lm(rank(weight)~physical_3plus, data =yrbss_select_phy)%>%broom::tidy( conf.int =TRUE, conf.level =0.95)
ABCDEFGHIJ0123456789
term
<chr>
estimate
<dbl>
std.error
<dbl>
statistic
<dbl>
p.value
<dbl>
conf.low
<dbl>
conf.high
<dbl>
(Intercept)
6366.9438
38.96362
163.407391
0.000000e+00
6290.5690
6443.3186
physical_3plusno
-566.9972
68.31527
-8.299715
1.151496e-16
-700.9058
-433.0887
Here too, the linear model using rank data arrives at a conclusion similar to that of the Mann-Whitney U test.
Using Permutation Tests
For this last Case Study, we will do this in two ways, just for fun: one using our familiar mosaic package, and the other using the package infer.
But first, we need to initialize the test, which we will save as obs_diff_**.
Show the Code
obs_diff_infer<-yrbss_select_phy%>%infer::specify(weight~physical_3plus)%>%infer::calculate( stat ="diff in means", order =c("yes", "no"))obs_diff_infer##obs_diff_mosaic<-mosaic::diffmean(~weight|physical_3plus, data =yrbss_select_phy)obs_diff_mosaic##obs_diff_phy
ABCDEFGHIJ0123456789
stat
<dbl>
1.774584
diffmean
-1.774584
diffmean
-1.774584
Important
Note that obs_diff_infer is a 1 X 1 dataframe; obs_diff_mosaic is a scalar!!
Next, we will work through creating a permutation distribution using tools from the infer package.
In infer, the specify() function is used to specify the variables you are considering (notated y ~ x), and you can use the calculate() function to specify the statistic you want to calculate and the order of subtraction you want to use. For this hypothesis, the statistic you are searching for is the difference in means, with the order being yes - no.
After you have calculated your observed statistic, you need to create a permutation distribution. This is the distribution that is created by shuffling the observed weights into new physical_3plus groups, labeled “yes” and “no”.
We will save the permutation distribution as null_dist.
Show the Code
null_dist<-yrbss_select_phy%>%specify(weight~physical_3plus)%>%hypothesize(null ="independence")%>%generate(reps =999, type ="permute")%>%calculate( stat ="diff in means", order =c("yes", "no"))null_dist
ABCDEFGHIJ0123456789
replicate
<int>
stat
<dbl>
1
-0.6398570634
2
-0.0170714254
3
-0.0507014519
4
-0.3727072970
5
0.3859619259
6
-0.3324846651
7
-0.4526108543
8
-0.1202978446
9
-0.0209444429
10
0.0577725191
The hypothesize() function is used to declare what the null hypothesis is. Here, we are assuming that student’s weight is independent of whether they exercise at least 3 days or not.
We should also note that the type argument within generate() is set to "permute". This ensures that the statistics calculated by the calculate() function come from a reshuffling of the data (not a resampling of the data)! Finally, the specify() and calculate() steps should look familiar, since they are the same as what we used to find the observed difference in means!
We can visualize this null distribution with the following code:
Show the Code
# Set graph themetheme_set(new =theme_custom())#null_dist%>%visualise()+# Note this plus sign!shade_p_value(obs_diff_infer, direction ="two-sided")
Now that you have calculated the observed statistic and generated a permutation distribution, you can calculate the p-value for your hypothesis test using the function get_p_value() from the infer package.
Show the Code
null_dist%>%get_p_value( obs_stat =obs_diff_infer, direction ="two_sided")
ABCDEFGHIJ0123456789
p_value
<dbl>
0
What warning message do you get? Why do you think you get this warning message? Let us construct and record a confidence interval for the difference between the weights of those who exercise at least three times a week and those who don’t, and interpret this interval in context of the data.
It does look like the observed_diff_infer is too far away from this confidence interval. Hence if there was no difference in weight caused by physical_3plus, we would never have observed it! Hence the physical_3plus does have an effect on weight!
We already have the observed difference, obs_diff_mosaic. Now we generate the null distribution using permutation, with mosaic:
Show the Code
null_dist_mosaic<-do(999)*diffmean(~weight|shuffle(physical_3plus), data =yrbss_select_phy)
We can also generate the histogram of the null distribution, compare that with the observed diffrence and compute the p-value and confidence intervals:
Show the Code
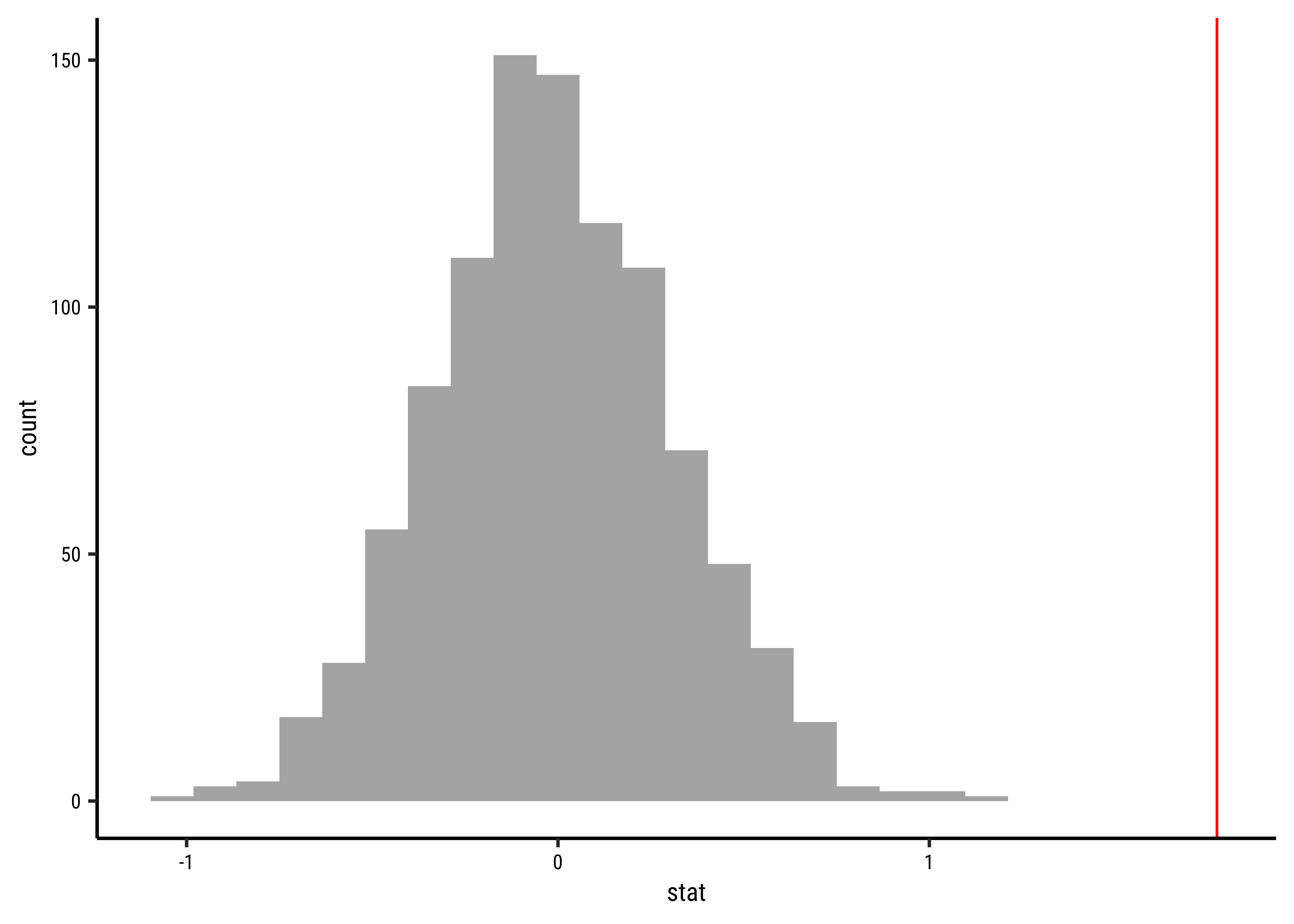
# Set graph themetheme_set(new =theme_custom())#gf_histogram(~diffmean, data =null_dist_mosaic)%>%gf_vline( xintercept =obs_diff_mosaic, colour ="red", linewidth =2)
Show the Code
# p-valueprop(~diffmean!=obs_diff_mosaic, data =null_dist_mosaic)
prop_TRUE
1
Show the Code
# Confidence Intervals for p = 0.95mosaic::cdata(~diffmean, p =0.95, data =null_dist_mosaic)
ABCDEFGHIJ0123456789
lower
<dbl>
upper
<dbl>
central.p
<dbl>
2.5%
-0.6021474
0.602495
0.95
Again, it does look like the observed_diff_infer is too far away from this NULL distribution. Hence if there was no difference in weight caused by physical_3plus, we would never have observed it! Hence the physical_3plus does have an effect on weight!
Clearly there is a serious effect of Physical Exercise on the body weights of students in the population from which this dataset is drawn.
Wait, But Why?
We need often to infer differences in means between Quantitative variables in a Population
We treat our dataset as a sample from the population, which we cannot access
We can apply all the CLT ideas +t.test if the two variables in the dataset satisfy the conditions of normality, equal variance
Else use non-parametric wilcox.test
And by treating the two variables as one Quant in two groups, we can simply perform a Permutation test
Conclusion
We have learnt how to perform inference for independent means.
We have looked at the conditions that make the regular t.test possible, and learnt what to do if the conditions of normality and equal variance are not met.
We have also looked at how these tests can be understood as manifestations of the linear model, with data and sign-ranked data.
Your Turn
Try the SwimRecords dataset from the mosaicData package.
Try some of the datasets in the moderndive package. Install it , peasants. And type in your Console data(package = "moderndive") to see what you have. Teacher evals might interest you!