The perceptron was invented by Frank Rosenblatt is considered one of the foundational pieces of neural network structures. The output is viewed as a decision from the neuron and is usually propagated as an input to other neurons inside the neural network.
Perceptron
Math Intuition
We can imagine this as a set of inputs that averaged in weighted fashion.
\[
y_k = sigmoid~(~\sum_{k=1}^n W_k*x_k + b~)
\]
Since the inputs are added with linear weighting, this effectively acts like a linear transformation of the input data.
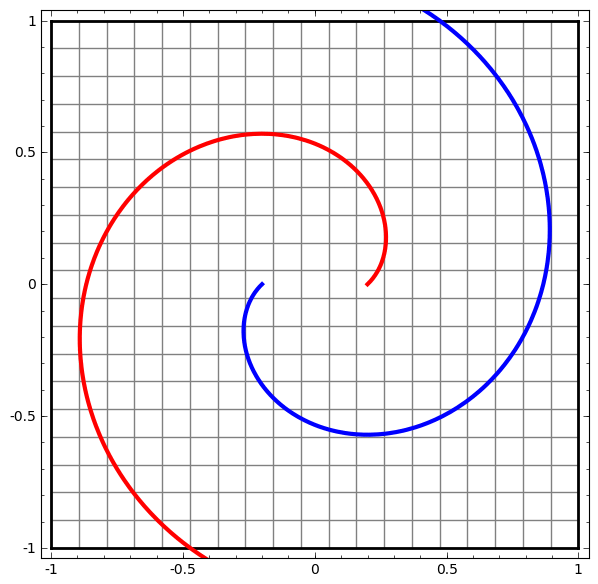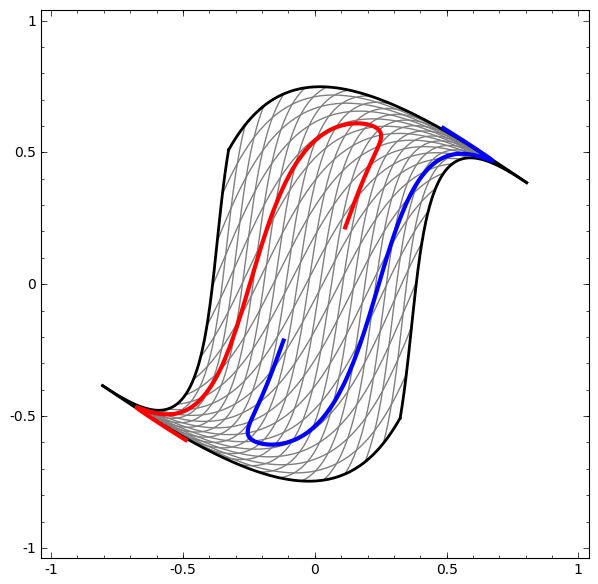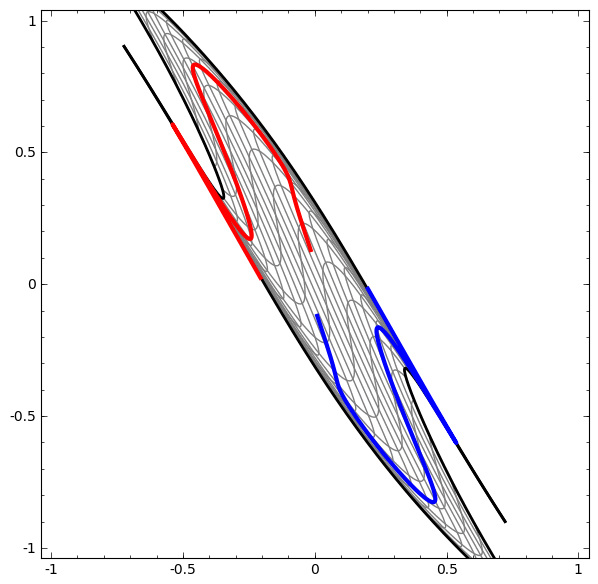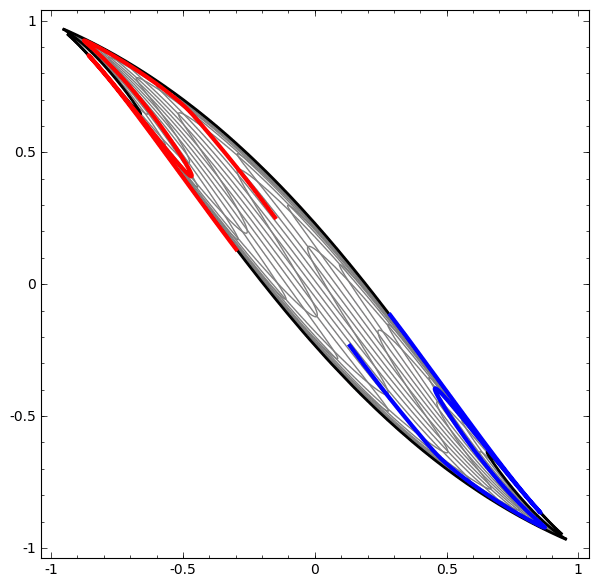
If we imagine the input as representing the n-coordinates in a plane, then the multiplications scale/stretch/compress the plane, like a rubber sheet. (But do not fold it.)
If there were only 2 inputs, we could mentally picture this.
More metaphorically, it seems like the neuron is consulting each of the inputs, asking for their opinion, and then making a decision by attaching different amounts of significance to each opinion.
We want the weighted sum of the inputs to mean something significant, before we accept it.
The bias is subtracted from the weighted sum of inputs, and the bias input could also (notionally) have a weight.
The bias is like a threshold which the weighted sum has to exceed; if it does, the neuron is said to fire.
What is the Activation Block?
We said earlier that the weighting and adding is a linear operation.
While this is great, simple linear translations of data are not capable of generating what we might call learning or generalization ability.
We need to have some non-linear block to allow the data to create nonlinear transformations of the data space, such as curving it, or folding it, or creating bumps, depressions, twists, and so on.
Activation
This nonlinear function needs to be chosen with care so that it is both differentiable and keeps the math analysis tractable. (More later)
Such a nonlinear mathematical function is implemented in the Activation Block.
See this example: red and blue areas, which we wish to separate and classify these with our DLNN, are not separable unless we fold and curve our 2D data space.
The separation is achieved using a linear operation, i.e. a LINE!!
Figure 1: From Colah Blog, used sadly without permission
For instance in Figure 1, no amount of stretching or compressing of the surface can separate the two sets ( blue and red ) using a line or plane, unless the surface can be warped into another dimension by folding.
What is the Sigmoid Function?
So how do we implement this nonlinear Activation Block?
One of the popular functions used in the Activation Block is a function based on the exponential function \(e^x\).
Why? Because this function retains is identity when differentiated! This is a very convenient property!
Sigmoid Activation
Remembering Logistic Regression
Recall your study of Logistic Regression. There, the Sigmoid function was used to model the odds of the (Qualitative) target variable against the (Quantitative) predictor.
Let us try a simple single layer NN in R. We will use the R package neuralnet.
Show the Code
# Load the package# library(neuralnet)# Use iris# Create Training and Testing Datasetsdf_train<-iris%>%slice_sample(n =100)df_test<-iris%>%anti_join(df_train)head(iris)
Show the Code
# Create a simle Neural Netnn<-neuralnet(Species~Sepal.Length+Sepal.Width+Petal.Length+Petal.Width, data =df_train, hidden =0,# act.fct = "logistic", # Sigmoid linear.output =TRUE)# TRUE to ignore activation function# str(nn)# Plotplot(nn)# Predictions# Predict <- compute(nn, df_test)# Predict# cat("Predicted values:\n")# print(Predict$net.result)## probability <- Predict$net.result# pred <- ifelse(probability > 0.5, 1, 0)# cat("Result in binary values:\n")# pred %>% as_tibble()