library(fpp3)
# Wrangling
# library(tsibble) # loads with ffp3
# library(tsibbledata) # loads with fpp3
# devtools::install_github("FinYang/tsdl")
library(tsdl)
library(TSstudio)
library(timetk)
library(tsbox)
library(gghighlight) # Highlight specific parts of charts
library(ggtime) # Mitchell Ohara-Wild June 2025
##
library(mosaic)
library(ggformula) # Our Formula based graphing package
library(skimr)
# library(lubridate) # Deal with dates. Loads with tidyverse
library(tidyverse)
Time Series
Line Graphs
Time Series
Abstract
Events, Trends, Seasons, and Changes over Time
Slides and Tutorials
| TimeSeries Wrangling | Time Series Analysis-WIP |
“Remember that sometimes not getting what you want is a wonderful stroke of luck.”
— Dalai Lama XIV
The fpp3 packages loads a good few other packages:
[1] "cli" "crayon" "dplyr" "fable" "fabletools"
[6] "feasts" "ggplot2" "lubridate" "purrr" "rstudioapi"
[11] "tibble" "tidyr" "tsibble" "tsibbledata"Plot Fonts and Theme
Show the Code
library(systemfonts)
library(showtext)
## Clean the slate
systemfonts::clear_local_fonts()
systemfonts::clear_registry()
##
showtext_opts(dpi = 96) # set DPI for showtext
sysfonts::font_add(
family = "Alegreya",
regular = "../../../../../../fonts/Alegreya-Regular.ttf",
bold = "../../../../../../fonts/Alegreya-Bold.ttf",
italic = "../../../../../../fonts/Alegreya-Italic.ttf",
bolditalic = "../../../../../../fonts/Alegreya-BoldItalic.ttf"
)
sysfonts::font_add(
family = "Roboto Condensed",
regular = "../../../../../../fonts/RobotoCondensed-Regular.ttf",
bold = "../../../../../../fonts/RobotoCondensed-Bold.ttf",
italic = "../../../../../../fonts/RobotoCondensed-Italic.ttf",
bolditalic = "../../../../../../fonts/RobotoCondensed-BoldItalic.ttf"
)
showtext_auto(enable = TRUE) # enable showtext
##
theme_custom <- function() {
font <- "Alegreya" # assign font family up front
theme_classic(base_size = 14, base_family = font) %+replace% # replace elements we want to change
theme(
text = element_text(family = font), # set base font family
# text elements
plot.title = element_text( # title
family = font, # set font family
size = 24, # set font size
face = "bold", # bold typeface
hjust = 0, # left align
margin = margin(t = 5, r = 0, b = 5, l = 0)
), # margin
plot.title.position = "plot",
plot.subtitle = element_text( # subtitle
family = font, # font family
size = 14, # font size
hjust = 0, # left align
margin = margin(t = 5, r = 0, b = 10, l = 0)
), # margin
plot.caption = element_text( # caption
family = font, # font family
size = 9, # font size
hjust = 1
), # right align
plot.caption.position = "plot", # right align
axis.title = element_text( # axis titles
family = "Roboto Condensed", # font family
size = 12
), # font size
axis.text = element_text( # axis text
family = "Roboto Condensed", # font family
size = 9
), # font size
axis.text.x = element_text( # margin for axis text
margin = margin(5, b = 10)
)
# since the legend often requires manual tweaking
# based on plot content, don't define it here
)
}Show the Code
```{r}
#| cache: false
#| code-fold: true
## Set the theme
theme_set(new = theme_custom())
```Error in theme_set(new = theme_custom()): could not find function "theme_set"Show the Code
```{r}
#| cache: false
#| code-fold: true
## Use available fonts in ggplot text geoms too!
update_geom_defaults(geom = "text", new = list(
family = "Roboto Condensed",
face = "plain",
size = 3.5,
color = "#2b2b2b"
))
```Error in update_geom_defaults(geom = "text", new = list(family = "Roboto Condensed", : could not find function "update_geom_defaults"
| Variable #1 | Variable #2 | Chart Names | Chart Shape | |
|---|---|---|---|---|
| Quant | Qual | Line Chart, CandleStick Plot, Heatmap |
|
| No | Pronoun | Answer | Variable/Scale | Example | What Operations? |
|---|---|---|---|---|---|
| 1 | How Many / Much / Heavy? Few? Seldom? Often? When? | Quantities, with Scale and a Zero Value.Differences and Ratios /Products are meaningful. | Quantitative/Ratio | Length,Height,Temperature in Kelvin,Activity,Dose Amount,Reaction Rate,Flow Rate,Concentration,Pulse,Survival Rate | Correlation |
| 4 | What, Who, Where, Whom, Which | Name, Place, Animal, Thing | Qualitative/Nominal | Name | Count no. of cases,Mode |
Shown below are the temperatures over time in two US cities:
Where would need ACs in all rooms? And heaters?
Any metric that is measured over regular time intervals forms a time series. Analysis of Time Series is commercially important because of industrial need and relevance, especially with respect to Forecasting (Weather data, sports scores, population growth figures, stock prices, demand, sales, supply…).
What can we do with Time Series? As with other datasets, we have to begin by answering fundamental questions, such as:
- What are the types of time series?
- How do we visualize time series?
- How might we summarize time series to get aggregate numbers, say by week, month, quarter or year?
- How do we decompose the time series into level, trend, and seasonal components?
- How might we make a model of the underlying process that creates these time series?
- How do we make useful forecasts with the data we have?
We will first look at the multiple data formats for time series in R. Alongside we will look at the R packages that work with these formats and create graphs and measures using those objects. Then we examine data wrangling of time series, where we look at packages that offer dplyr-like ability to group and summarize time series using the time variable. We will finally look at obtaining the components of the time series and try our hand at modelling and forecasting.
There are multiple formats for time series data. The ones that we are likely to encounter most are:
The ts format: We may simply have a single series of measurements that are made over time, stored as a numerical vector. The
stats::ts()function will convert a numeric vector into an R time seriestsobject, which is the most basic time series object in R. The base-Rtsobject is used by established packagesforecastand is also supported by newer packages such astsbox.The tibble format: the simplest and most familiar data format is of course the standard tibble/data frame, with or without an explicit
timecolumn/variable to indicate that the other variables vary with time. The standard tibble object is used by many packages, e.g.timetk&modeltime.The tsibble format: this is a new format for time series analysis. The special
tsibbleobject (“time series tibble”) is used byfable,feastsand others from thetidyvertsset of packages.
There are many other time-oriented data formats too…probably too many, such a tibbletime and TimeSeries objects. For now the best way to deal with these, should you encounter them, is to convert them (Using the package tsbox) to a tibble or a tsibble and work with these.

To start, we will use simple ts data first, and then do another with a “vanilla” tibble format that we can plot as is. We will then look at a tibbledata that does have a time-oriented variable. We will then perform conversion to tsibble format to plot it, and then a final example with a ground-up tsibble dataset.
ts format data
There are a few datasets in base R that are in ts format already.
AirPassengers Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec
1949 112 118 132 129 121 135 148 148 136 119 104 118
1950 115 126 141 135 125 149 170 170 158 133 114 140
1951 145 150 178 163 172 178 199 199 184 162 146 166
1952 171 180 193 181 183 218 230 242 209 191 172 194
1953 196 196 236 235 229 243 264 272 237 211 180 201
1954 204 188 235 227 234 264 302 293 259 229 203 229
1955 242 233 267 269 270 315 364 347 312 274 237 278
1956 284 277 317 313 318 374 413 405 355 306 271 306
1957 315 301 356 348 355 422 465 467 404 347 305 336
1958 340 318 362 348 363 435 491 505 404 359 310 337
1959 360 342 406 396 420 472 548 559 463 407 362 405
1960 417 391 419 461 472 535 622 606 508 461 390 432str(AirPassengers) Time-Series [1:144] from 1949 to 1961: 112 118 132 129 121 135 148 148 136 119 ...This can be easily plotted using base R:
# Base R
plot(AirPassengers)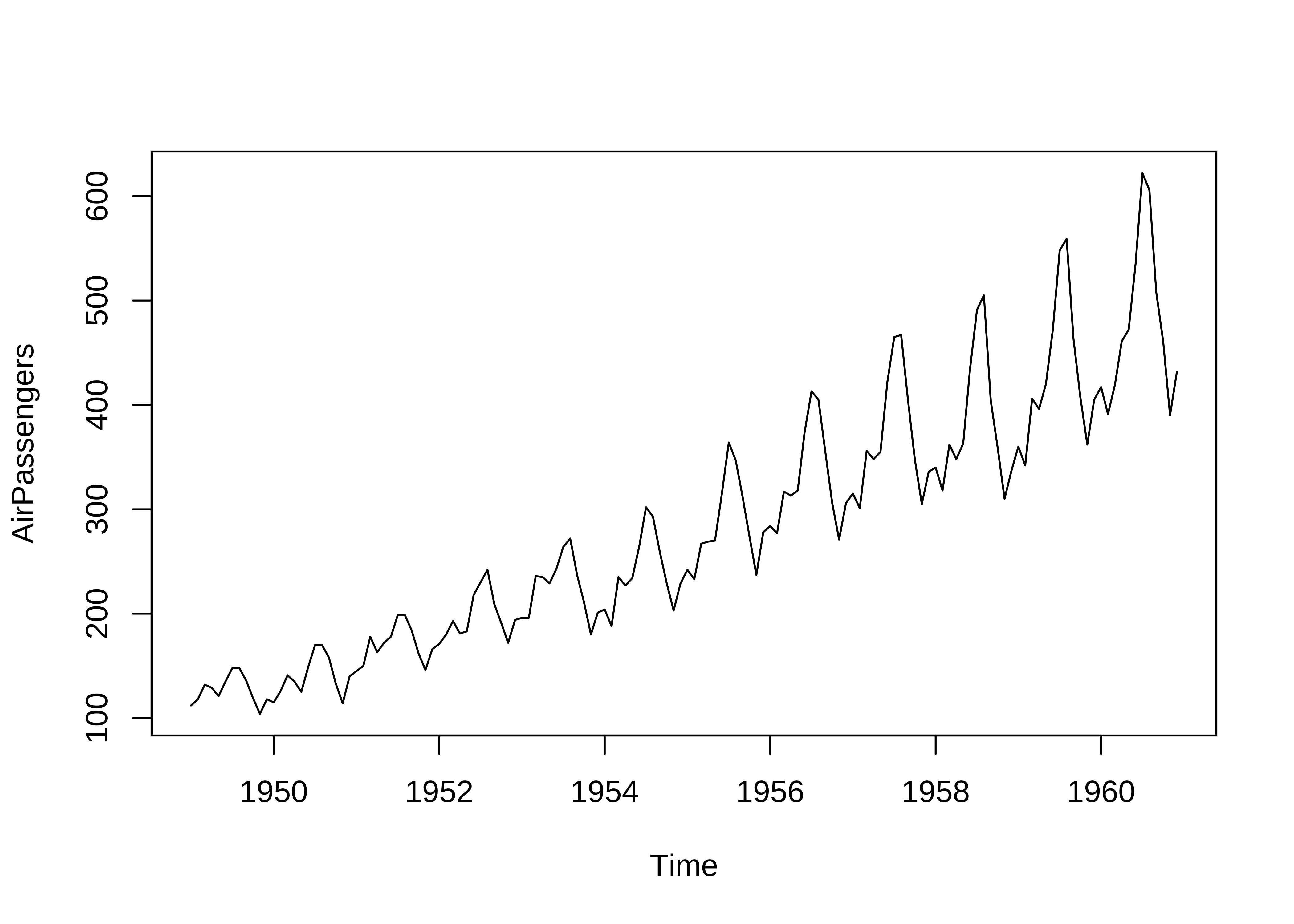
One can see that there is an upward trend and also seasonal variations that also increase over time. This is an example of a multiplicative time series, which we will discuss later.
Let us take data that is “time oriented” but not in ts format. We use the command ts to convert a numeric vector to ts format: the syntax of ts() is:
Syntax: objectName <- ts(data, start, end, frequency), where,
-
data: represents the data vector -
start: represents the first observation in time series -
end: represents the last observation in time series -
frequency: represents number of observations per unit time. For example 1=annual, 4=quarterly, 12=monthly, 7=weekly, etc.
We will pick simple numerical vector data ( i.e. not a time series ) ChickWeight:
Classes 'nfnGroupedData', 'nfGroupedData', 'groupedData' and 'data.frame': 578 obs. of 4 variables:
$ weight: num 42 51 59 64 76 93 106 125 149 171 ...
$ Time : num 0 2 4 6 8 10 12 14 16 18 ...
$ Chick : Ord.factor w/ 50 levels "18"<"16"<"15"<..: 15 15 15 15 15 15 15 15 15 15 ...
$ Diet : Factor w/ 4 levels "1","2","3","4": 1 1 1 1 1 1 1 1 1 1 ...
- attr(*, "formula")=Class 'formula' language weight ~ Time | Chick
.. ..- attr(*, ".Environment")=<environment: R_EmptyEnv>
- attr(*, "outer")=Class 'formula' language ~Diet
.. ..- attr(*, ".Environment")=<environment: R_EmptyEnv>
- attr(*, "labels")=List of 2
..$ x: chr "Time"
..$ y: chr "Body weight"
- attr(*, "units")=List of 2
..$ x: chr "(days)"
..$ y: chr "(gm)"head(ChickWeight)weight <dbl> | Time <dbl> | Chick <ord> | Diet <fct> | |
|---|---|---|---|---|
| 1 | 42 | 0 | 1 | 1 |
| 2 | 51 | 2 | 1 | 1 |
| 3 | 59 | 4 | 1 | 1 |
| 4 | 64 | 6 | 1 | 1 |
| 5 | 76 | 8 | 1 | 1 |
| 6 | 93 | 10 | 1 | 1 |
# Filter for Chick #1 and for Diet #1
ChickWeight_ts <- ChickWeight %>%
dplyr::filter(Chick == 1, Diet == 1) %>%
dplyr::select(weight, Time)
## stats::ts does not accept pipe format
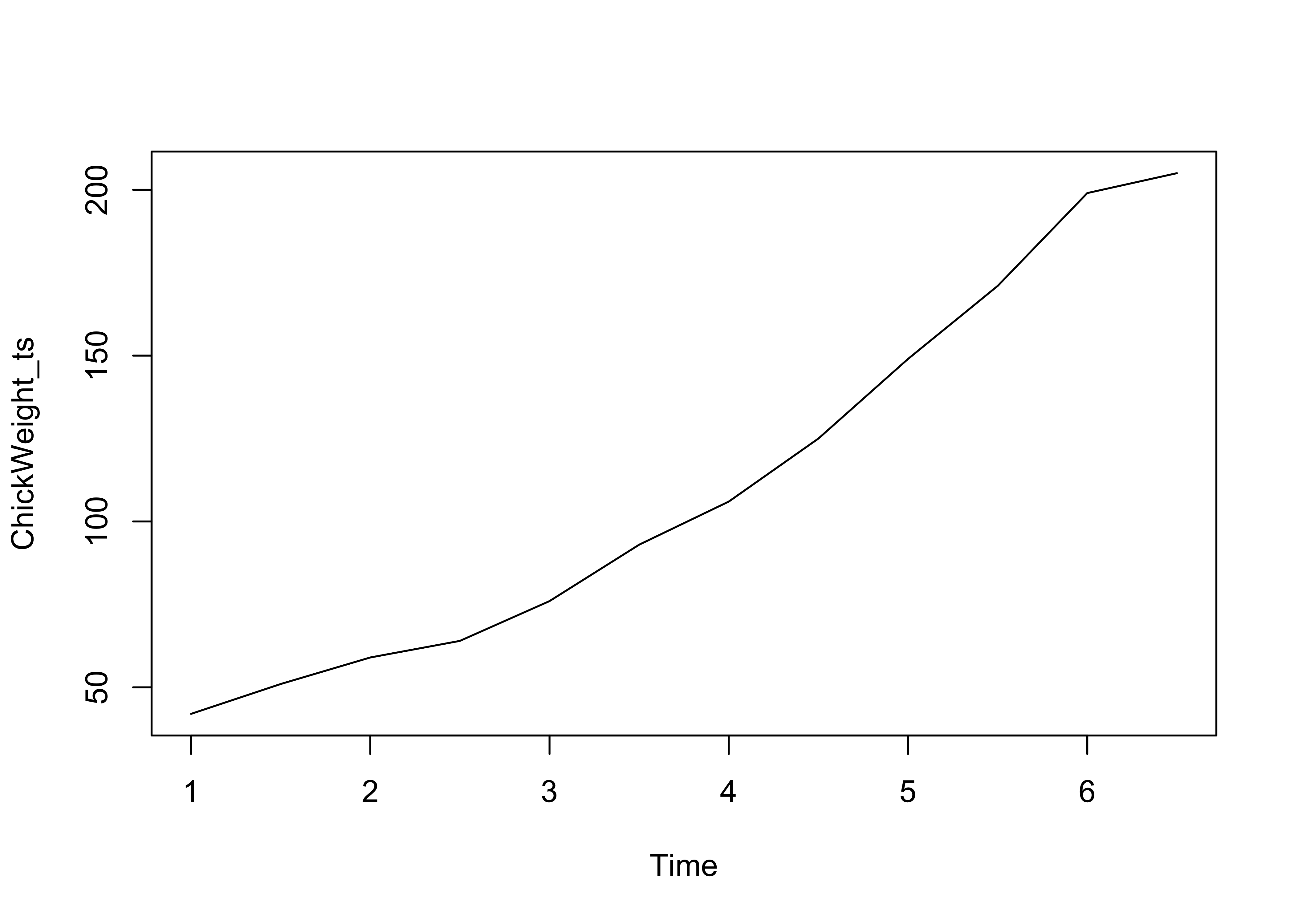
ChickWeight_ts <- stats::ts(ChickWeight_ts$weight,
frequency = 2
)
str(ChickWeight_ts) Time-Series [1:12] from 1 to 6.5: 42 51 59 64 76 93 106 125 149 171 ...plot(ChickWeight_ts) # Using base-R
We see that the weights of a young chick specimen #1 increases over time.
tibble data
The ts data format can handle only one time series; in the above example, we could not have plotted the weight of two chicks, if we had wanted to. If we want to plot/analyze multiple time series, based on say Qualitative variables, (e.g. sales figures over time across multiple products and locations) we need other data formats. Using the familiar tibble structure opens up new possibilities.
- We can have multiple time series within a tibble (think of numerical time-series data like
GDP,Population,Imports,Exportsfor multiple countries as with thegapminder1data we saw earlier).
gapminder data
| country | year | gdpPercap | pop | lifeExp | continent |
|---|---|---|---|---|---|
| Afghanistan | 1952 | 779.4453 | 8425333 | 28.801 | Asia |
| Afghanistan | 1957 | 820.8530 | 9240934 | 30.332 | Asia |
| Afghanistan | 1962 | 853.1007 | 10267083 | 31.997 | Asia |
| Afghanistan | 1967 | 836.1971 | 11537966 | 34.020 | Asia |
| Afghanistan | 1972 | 739.9811 | 13079460 | 36.088 | Asia |
- It also allows for data processing with
dplyrsuch as filtering and summarizing.
Let us read and inspect in the US births data from 2000 to 2014. Download this data by clicking on the icon below, and saving the downloaded file in a sub-folder called data inside your project.
Read this data in and inspect it.
Rows: 5,479
Columns: 5
$ year <dbl> 2000, 2000, 2000, 2000, 2000, 2000, 2000, 2000, 2000, 20…
$ month <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,…
$ date_of_month <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 1…
$ day_of_week <dbl> 6, 7, 1, 2, 3, 4, 5, 6, 7, 1, 2, 3, 4, 5, 6, 7, 1, 2, 3,…
$ births <dbl> 9083, 8006, 11363, 13032, 12558, 12466, 12516, 8934, 794…inspect(births_2000_2014)
quantitative variables:
name class min Q1 median Q3 max mean sd
1 year numeric 2000 2003 2007 2011 2014 2006.999270 4.321085
2 month numeric 1 4 7 10 12 6.522723 3.449075
3 date_of_month numeric 1 8 16 23 31 15.730243 8.801151
4 day_of_week numeric 1 2 4 6 7 3.999817 2.000502
5 births numeric 5728 8740 12343 13082 16081 11350.068261 2325.821049
n missing
1 5479 0
2 5479 0
3 5479 0
4 5479 0
5 5479 0skim(births_2000_2014)| Name | births_2000_2014 |
| Number of rows | 5479 |
| Number of columns | 5 |
| _______________________ | |
| Column type frequency: | |
| numeric | 5 |
| ________________________ | |
| Group variables | None |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|
| year | 0 | 1 | 2007.00 | 4.32 | 2000 | 2003 | 2007 | 2011 | 2014 | ▇▇▇▇▇ |
| month | 0 | 1 | 6.52 | 3.45 | 1 | 4 | 7 | 10 | 12 | ▇▅▅▅▇ |
| date_of_month | 0 | 1 | 15.73 | 8.80 | 1 | 8 | 16 | 23 | 31 | ▇▇▇▇▆ |
| day_of_week | 0 | 1 | 4.00 | 2.00 | 1 | 2 | 4 | 6 | 7 | ▇▃▃▃▇ |
| births | 0 | 1 | 11350.07 | 2325.82 | 5728 | 8740 | 12343 | 13082 | 16081 | ▂▂▁▇▁ |
births_2000_2014year <dbl> | month <dbl> | date_of_month <dbl> | day_of_week <dbl> | births <dbl> |
|---|---|---|---|---|
| 2000 | 1 | 1 | 6 | 9083 |
| 2000 | 1 | 2 | 7 | 8006 |
| 2000 | 1 | 3 | 1 | 11363 |
| 2000 | 1 | 4 | 2 | 13032 |
| 2000 | 1 | 5 | 3 | 12558 |
| 2000 | 1 | 6 | 4 | 12466 |
| 2000 | 1 | 7 | 5 | 12516 |
| 2000 | 1 | 8 | 6 | 8934 |
| 2000 | 1 | 9 | 7 | 7949 |
| 2000 | 1 | 10 | 1 | 11668 |
This is just a tibble containing a single data variable births that varies over time. All other variables, although depicting time, are numerical columns and not explicitly time columns. There are no Qualitative variables (yet!).
Plotting tibble-oriented time data
We will now plot this using ggformula. Using the separate year/month/week and day_of_week / day_of_month columns, we can plot births over time, colouring by day_of_week, for example:
## Set the theme
theme_set(new = theme_custom())
# grouping by day_of_week
births_2000_2014 %>%
gf_line(births ~ year,
group = ~day_of_week,
color = ~day_of_week
) %>%
gf_point(
title = "Births, By Day of Week",
subtitle = "Over the Years"
) %>%
gf_refine(scale_colour_distiller(palette = "Paired"))
# Grouping by date_of_month
births_2000_2014 %>%
gf_line(births ~ year,
group = ~date_of_month,
color = ~date_of_month
) %>%
gf_point(
title = "Births, By Date of Month",
subtitle = "Over the Years"
) %>%
gf_refine(scale_colour_distiller(palette = "Paired"))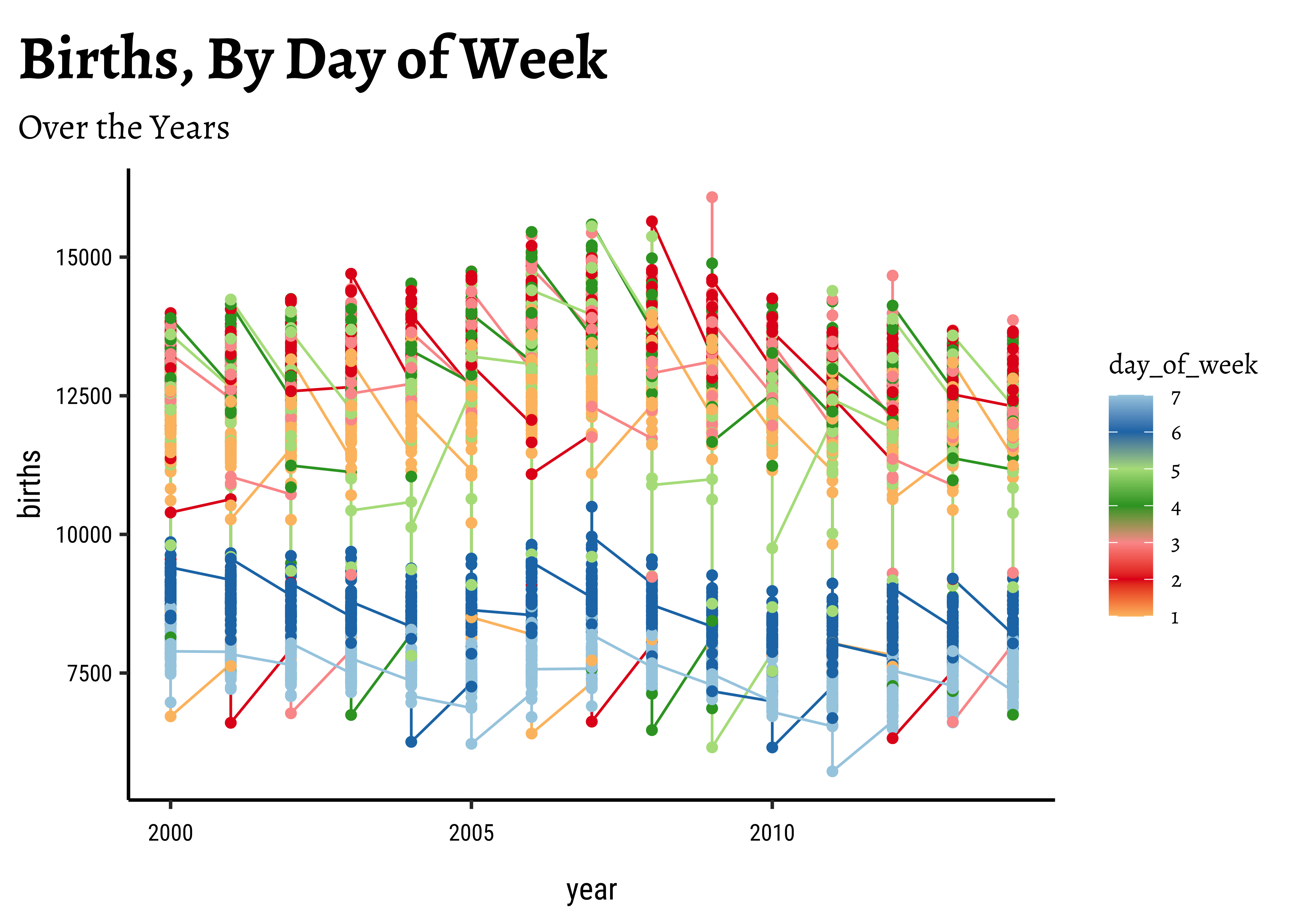
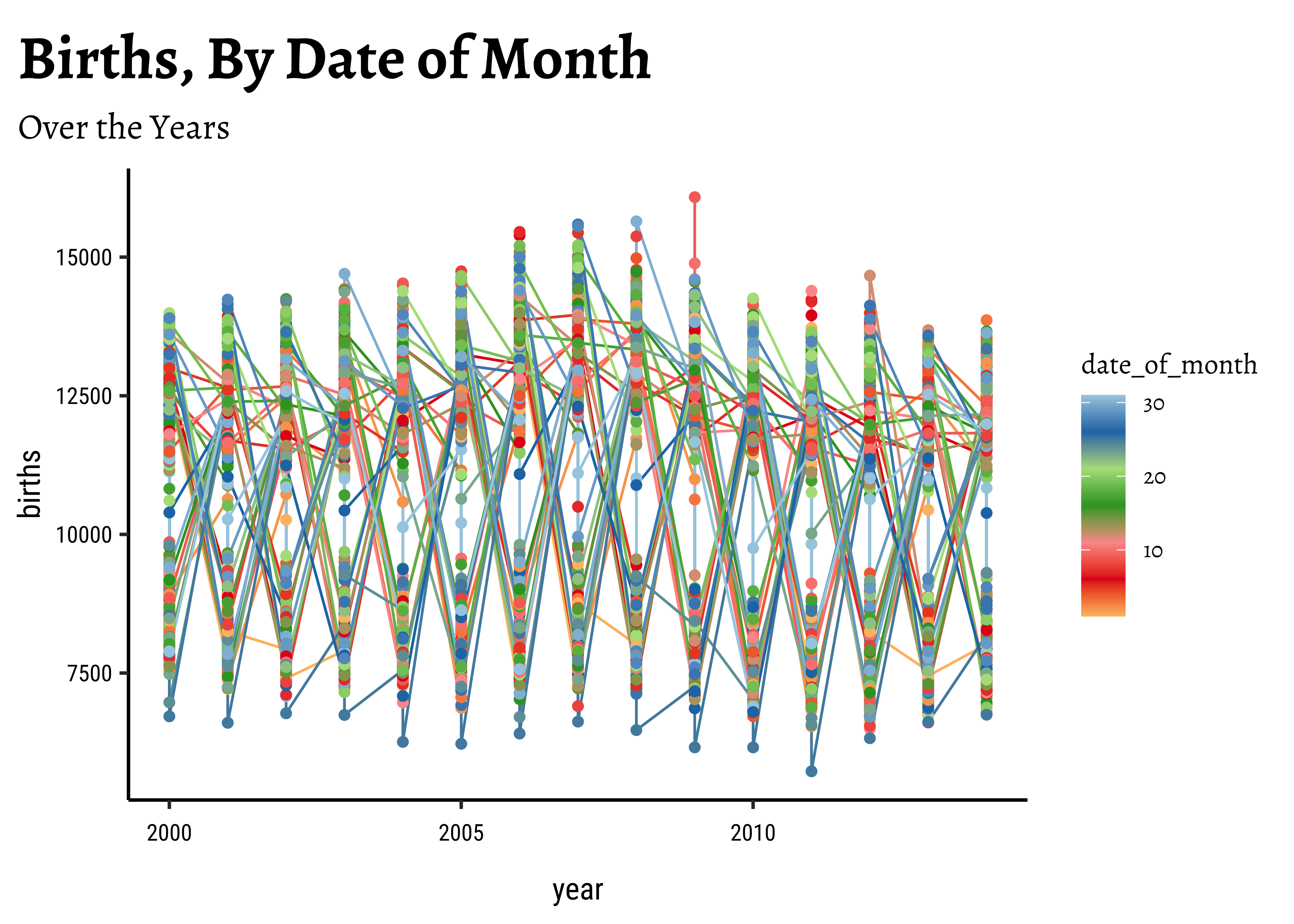
Not particularly illuminating. This is because the data is daily and we have considerable variation over time, and here we have too much data to visualize.
Summaries will help, so we could calculate the the mean births per month in each year and plot that:
## Set the theme
theme_set(new = theme_custom())
births_2000_2014_monthly <- births_2000_2014 %>%
# Convert month to factor/Qual variable!
# So that we can have discrete colours for each month
# Using base::factor()
# Could use forcats::as_factor() also
mutate(month = base::factor(month, labels = month.abb)) %>%
# `month.abb` is a built-in dataset containing names of months.
group_by(year, month) %>%
summarise(mean_monthly_births = mean(births, na.rm = TRUE))
births_2000_2014_monthly
####
births_2000_2014_monthly %>%
##
gf_line(mean_monthly_births ~ year,
group = ~month,
colour = ~month, linewidth = 1
) %>%
##
gf_point(
size = 1.5,
title = "Summaries of Monthly Births over the years"
) %>%
## palette for 12 colours
gf_refine(scale_colour_brewer(palette = "Paired"))year <dbl> | month <fct> | mean_monthly_births <dbl> | ||
|---|---|---|---|---|
| 2000 | Jan | 10894.81 | ||
| 2000 | Feb | 11174.00 | ||
| 2000 | Mar | 11220.13 | ||
| 2000 | Apr | 10778.57 | ||
| 2000 | May | 11224.19 | ||
| 2000 | Jun | 11596.63 | ||
| 2000 | Jul | 11488.10 | ||
| 2000 | Aug | 11867.52 | ||
| 2000 | Sep | 11866.03 | ||
| 2000 | Oct | 11366.71 |
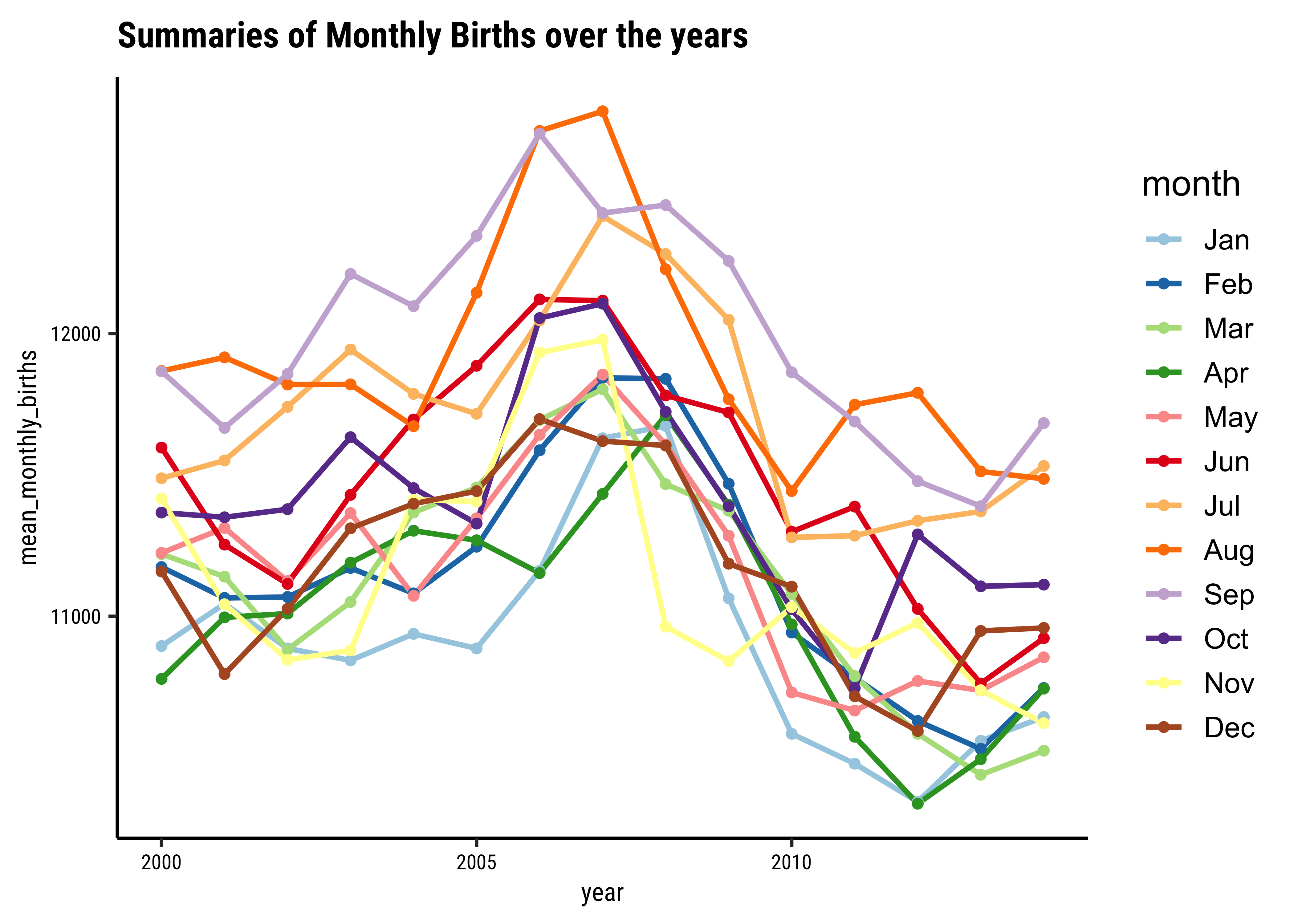
Note
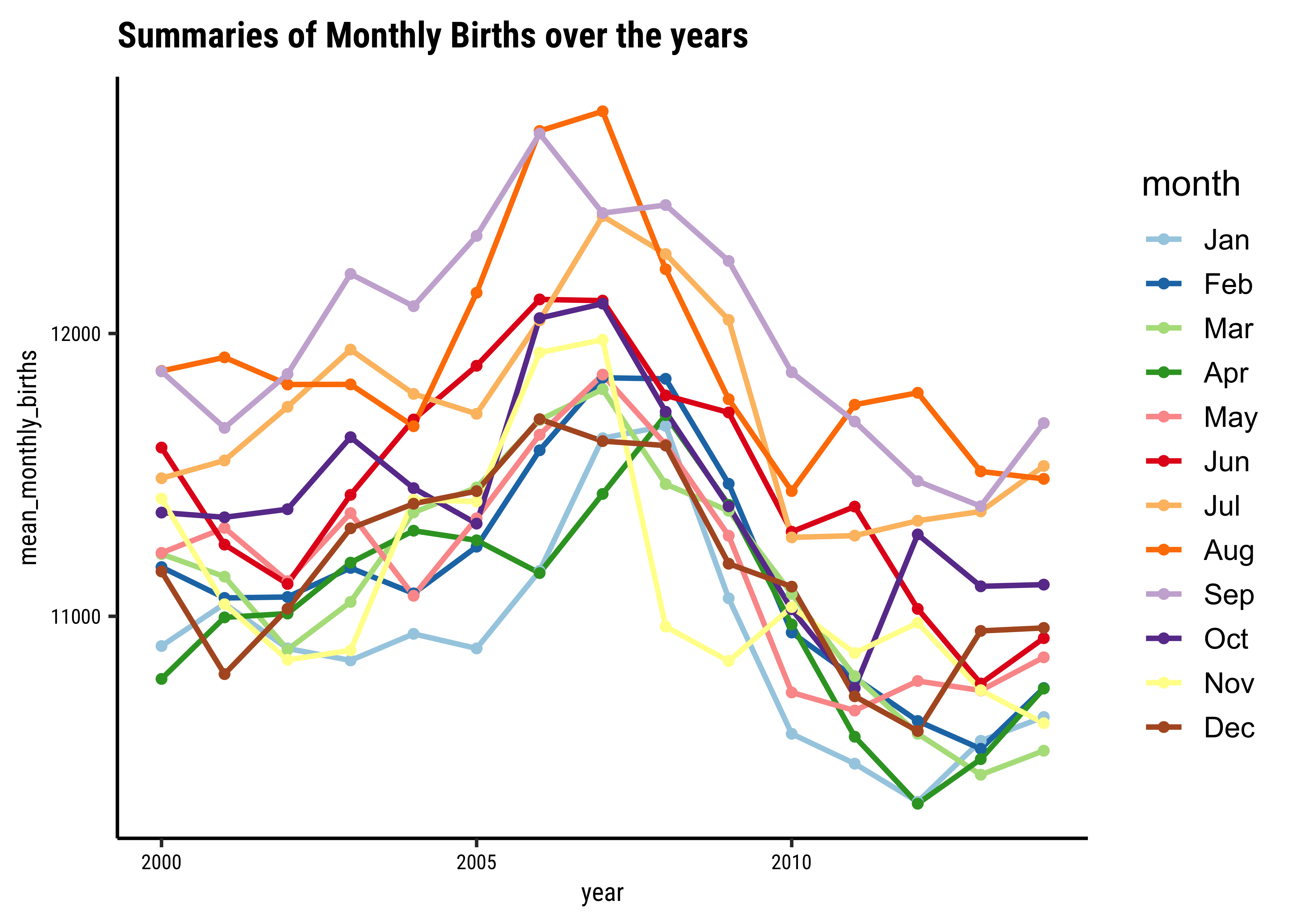
These are graphs for the same month each year: we have a January graph and a February graph and so on. So…average births per month were higher in all months during 2005 to 2007 and have dropped since.
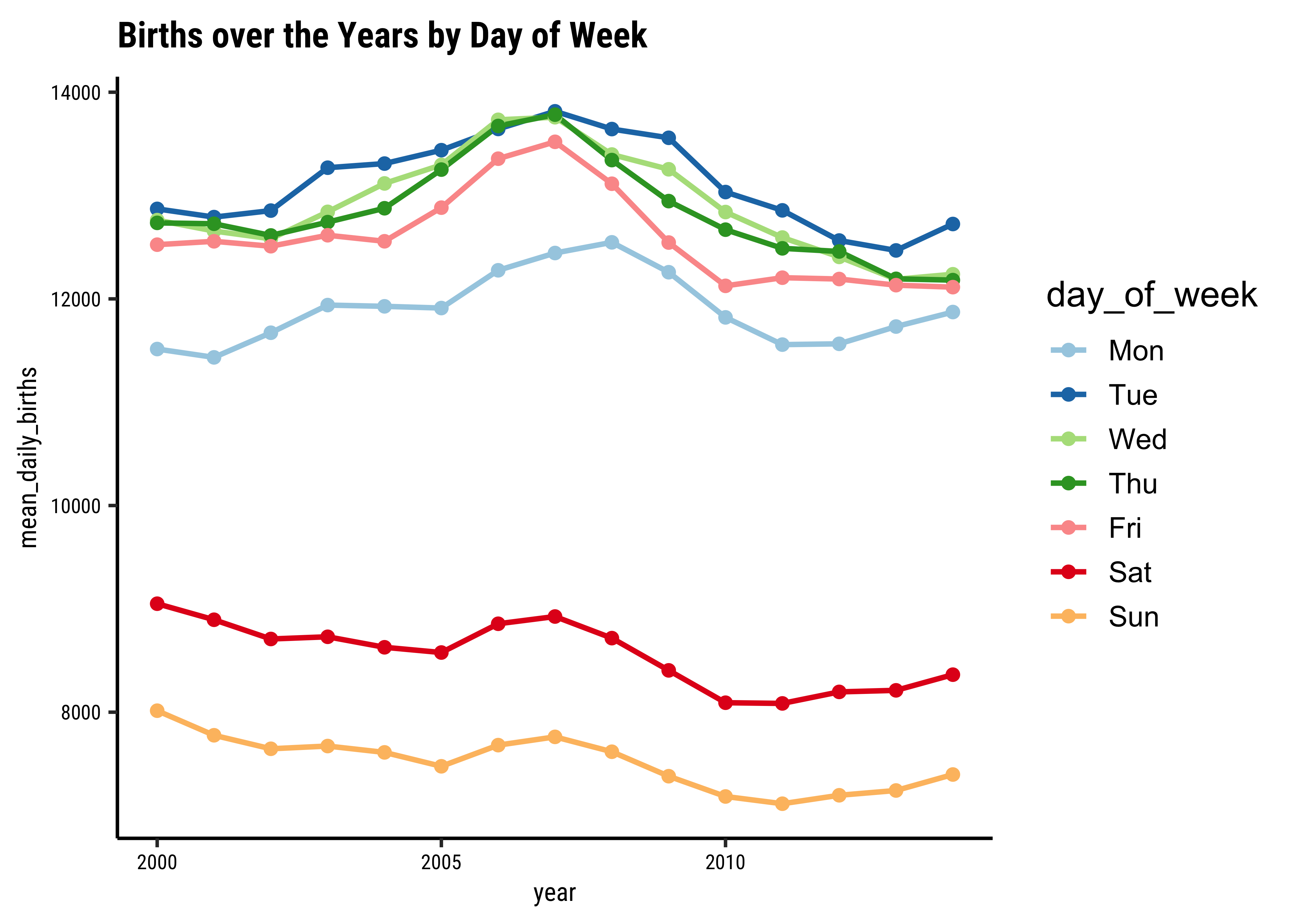
We can do similar graphs using day_of_week as our basis for grouping, instead of month:
## Set the theme
theme_set(new = theme_custom())
births_2000_2014_weekly <- births_2000_2014 %>%
mutate(day_of_week = base::factor(day_of_week,
levels = c(1, 2, 3, 4, 5, 6, 7),
labels = c("Mon", "Tue", "Wed", "Thu", "Fri", "Sat", "Sun")
)) %>%
group_by(year, day_of_week) %>%
summarise(mean_daily_births = mean(births, na.rm = TRUE))
##
births_2000_2014_weekly
##
births_2000_2014_weekly %>%
gf_line(mean_daily_births ~ year,
group = ~day_of_week,
colour = ~day_of_week,
linewidth = 1,
data = .
) %>%
gf_point(size = 2, title = "Births over the Years by Day of Week") %>%
# palette for 12 colours
gf_refine(scale_colour_brewer(palette = "Paired"))year <dbl> | day_of_week <fct> | mean_daily_births <dbl> | ||
|---|---|---|---|---|
| 2000 | Mon | 11514.462 | ||
| 2000 | Tue | 12870.846 | ||
| 2000 | Wed | 12762.269 | ||
| 2000 | Thu | 12735.462 | ||
| 2000 | Fri | 12524.500 | ||
| 2000 | Sat | 9049.830 | ||
| 2000 | Sun | 8014.434 | ||
| 2001 | Mon | 11433.849 | ||
| 2001 | Tue | 12791.385 | ||
| 2001 | Wed | 12656.731 |
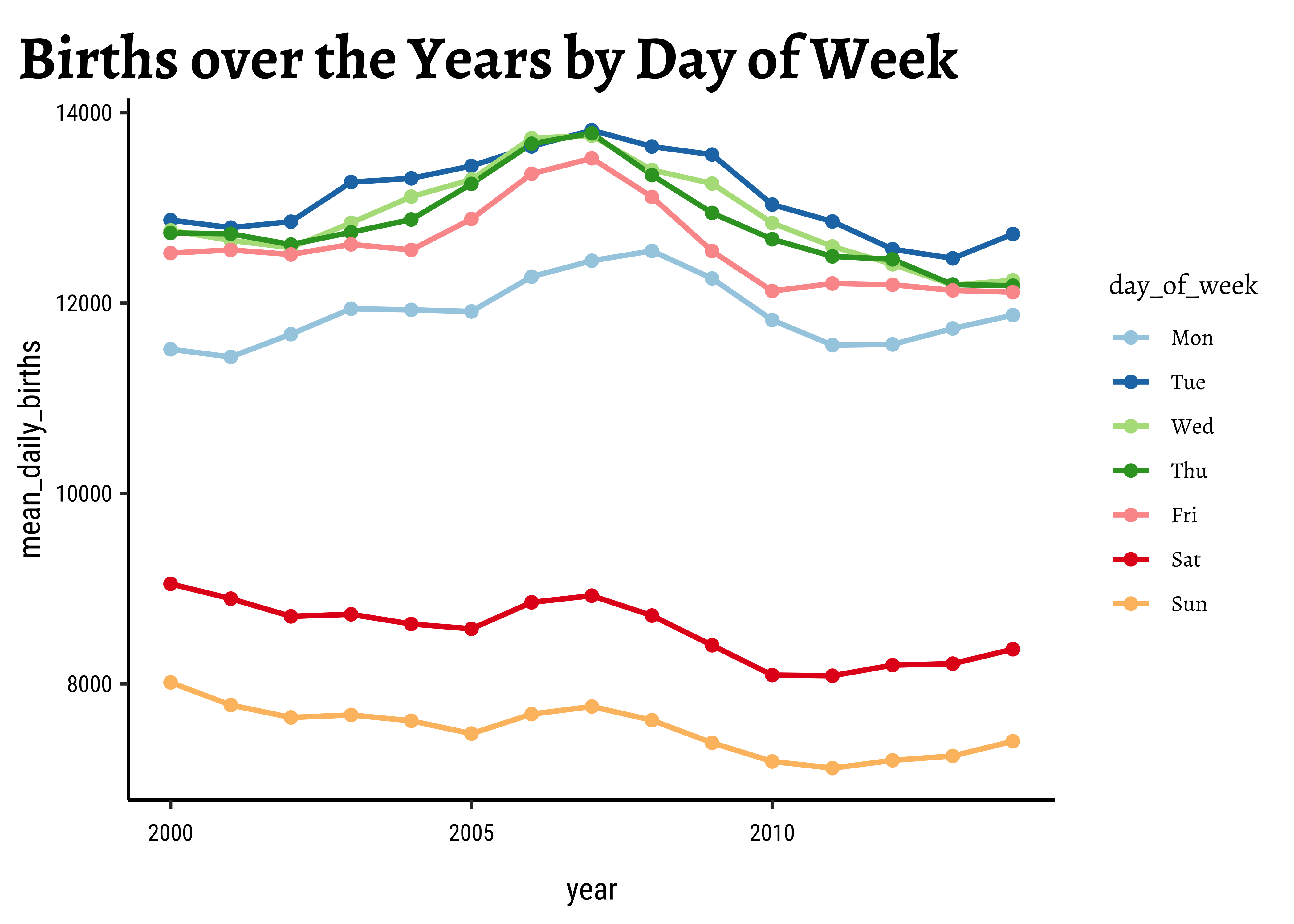
We will now plot this using ggplot for completeness. Using the separate year/month/week and day_of_week / day_of_month columns, we can plot births over time, colouring by day_of_week, for example:
## Set the theme
theme_set(new = theme_custom())
# grouping by day_of_week
births_2000_2014 %>%
ggplot(aes(year, births,
group = day_of_week,
color = day_of_week
)) +
geom_line() +
geom_point() +
labs(
title = "Births, By Day of Week",
subtitle = "Over the Years"
) +
scale_colour_distiller(palette = "Paired")
##
# Grouping by date_of_month
births_2000_2014 %>%
ggplot(aes(year, births,
color = date_of_month,
group = date_of_month
)) +
geom_line() +
geom_point() +
labs(
title = "Births, By Date of Month",
subtitle = "Over the Years"
) +
scale_colour_distiller(palette = "Paired")
## Set the theme
theme_set(new = theme_custom())
births_2000_2014_monthly <- births_2000_2014 %>%
# Convert month to factor/Qual variable!
# So that we can have discrete colours for each month
# Using base::factor()
# Could use forcats::as_factor() also
mutate(month = base::factor(month, labels = month.abb)) %>%
# `month.abb` is a built-in dataset containing names of months.
group_by(year, month) %>%
summarise(mean_monthly_births = mean(births, na.rm = TRUE))
births_2000_2014_monthly
births_2000_2014_monthly %>%
ggplot(aes(year, mean_monthly_births,
group = month,
colour = month
)) +
geom_line(linewidth = 1) +
geom_point(size = 1.5) +
labs(title = "Summaries of Monthly Births over the years") +
# palette for 12 colours
scale_colour_brewer(palette = "Paired")year <dbl> | month <fct> | mean_monthly_births <dbl> | ||
|---|---|---|---|---|
| 2000 | Jan | 10894.81 | ||
| 2000 | Feb | 11174.00 | ||
| 2000 | Mar | 11220.13 | ||
| 2000 | Apr | 10778.57 | ||
| 2000 | May | 11224.19 | ||
| 2000 | Jun | 11596.63 | ||
| 2000 | Jul | 11488.10 | ||
| 2000 | Aug | 11867.52 | ||
| 2000 | Sep | 11866.03 | ||
| 2000 | Oct | 11366.71 |
## Set the theme
theme_set(new = theme_custom())
births_2000_2014_weekly <- births_2000_2014 %>%
mutate(day_of_week = base::factor(day_of_week,
levels = c(1, 2, 3, 4, 5, 6, 7),
labels = c("Mon", "Tue", "Wed", "Thu", "Fri", "Sat", "Sun")
)) %>%
group_by(year, day_of_week) %>%
summarise(mean_daily_births = mean(births, na.rm = TRUE))
births_2000_2014_weekly
births_2000_2014_weekly %>%
ggplot(aes(year, mean_daily_births,
group = day_of_week,
colour = day_of_week
)) +
geom_line(linewidth = 1) +
geom_point(size = 2) +
# palette for 12 colours
scale_colour_brewer(palette = "Paired") +
labs(title = "Births over the Years by Day of Week")year <dbl> | day_of_week <fct> | mean_daily_births <dbl> | ||
|---|---|---|---|---|
| 2000 | Mon | 11514.462 | ||
| 2000 | Tue | 12870.846 | ||
| 2000 | Wed | 12762.269 | ||
| 2000 | Thu | 12735.462 | ||
| 2000 | Fri | 12524.500 | ||
| 2000 | Sat | 9049.830 | ||
| 2000 | Sun | 8014.434 | ||
| 2001 | Mon | 11433.849 | ||
| 2001 | Tue | 12791.385 | ||
| 2001 | Wed | 12656.731 |
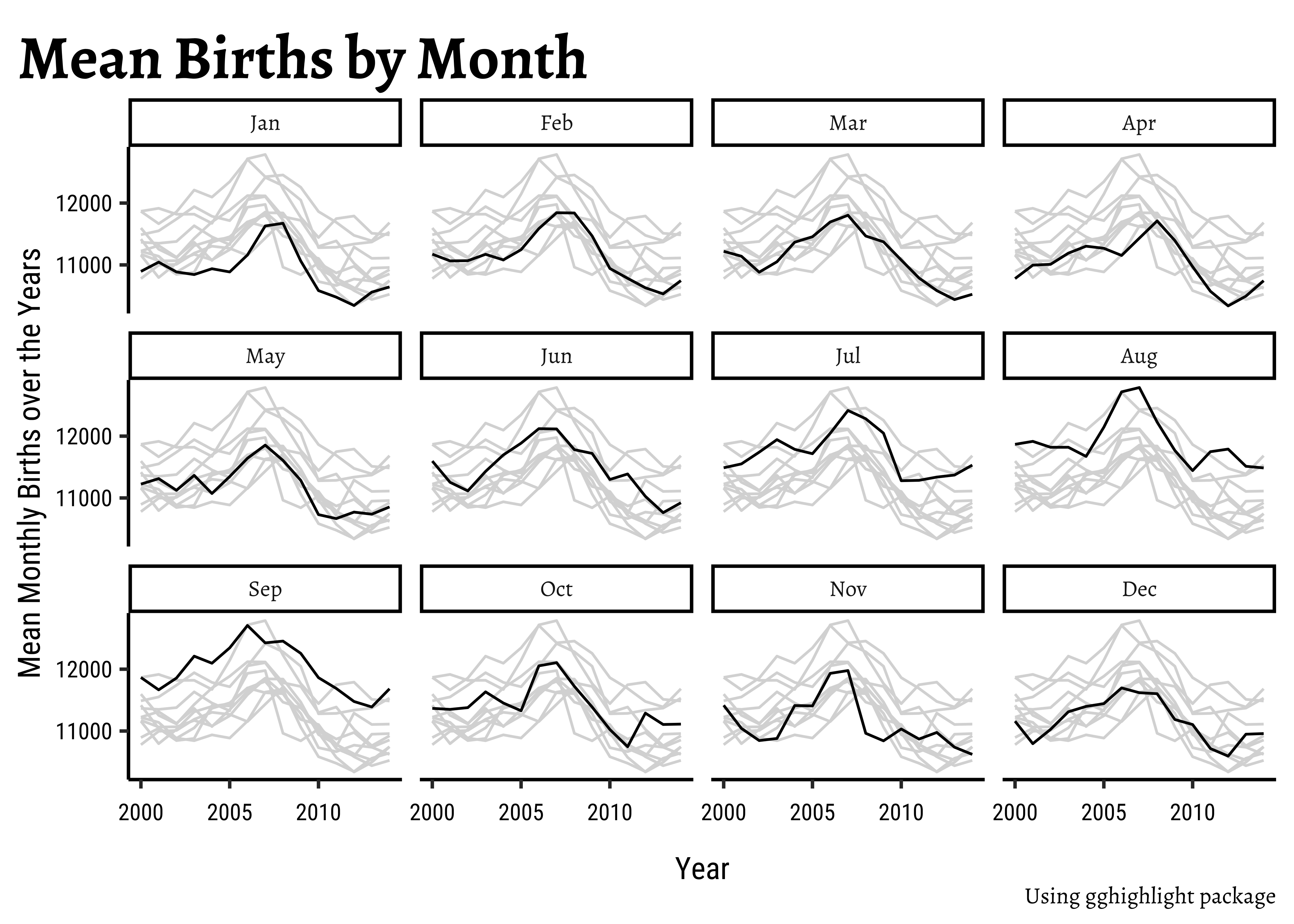
Instead of looking at multiple overlapping time series graphs, we could split these up into small multiples or facets and still retain the overall picture that is offered by the overlapping graphs. The trick here is the highlight one of the graphs at a time, while keeping all other graphs in the background. We can do this with the gghighlight package.
## Set the theme
theme_set(new = theme_custom())
# library(gghighlight)
births_2000_2014_monthly
###
births_2000_2014_monthly %>% ggplot() +
geom_line(aes(
y = mean_monthly_births,
x = year,
group = month
)) +
labs(
x = "Year", y = "Mean Monthly Births over the Years",
title = "Mean Births by Month",
caption = "Using gghighlight package"
) +
### Add highlighting
gghighlight(
use_direct_label = F,
unhighlighted_params = list(colour = alpha("grey85", 1))
) +
### Add faceting
facet_wrap(vars(month))year <dbl> | month <fct> | mean_monthly_births <dbl> | ||
|---|---|---|---|---|
| 2000 | Jan | 10894.81 | ||
| 2000 | Feb | 11174.00 | ||
| 2000 | Mar | 11220.13 | ||
| 2000 | Apr | 10778.57 | ||
| 2000 | May | 11224.19 | ||
| 2000 | Jun | 11596.63 | ||
| 2000 | Jul | 11488.10 | ||
| 2000 | Aug | 11867.52 | ||
| 2000 | Sep | 11866.03 | ||
| 2000 | Oct | 11366.71 |
## Set the theme
theme_set(new = theme_custom())
births_2000_2014_weekly
###
births_2000_2014_weekly %>% ggplot() +
geom_line(aes(y = mean_daily_births, x = year, group = day_of_week)) +
labs(
x = "Year", y = "Mean Daily Births over the Years",
title = "Mean Births by Day of Week",
caption = "Using gghighlight package"
) +
### Add highlighting
gghighlight(
use_direct_label = F,
unhighlighted_params = list(colour = alpha("grey85", 1))
) +
### Add faceting
facet_wrap(vars(day_of_week))year <dbl> | day_of_week <fct> | mean_daily_births <dbl> | ||
|---|---|---|---|---|
| 2000 | Mon | 11514.462 | ||
| 2000 | Tue | 12870.846 | ||
| 2000 | Wed | 12762.269 | ||
| 2000 | Thu | 12735.462 | ||
| 2000 | Fri | 12524.500 | ||
| 2000 | Sat | 9049.830 | ||
| 2000 | Sun | 8014.434 | ||
| 2001 | Mon | 11433.849 | ||
| 2001 | Tue | 12791.385 | ||
| 2001 | Wed | 12656.731 |
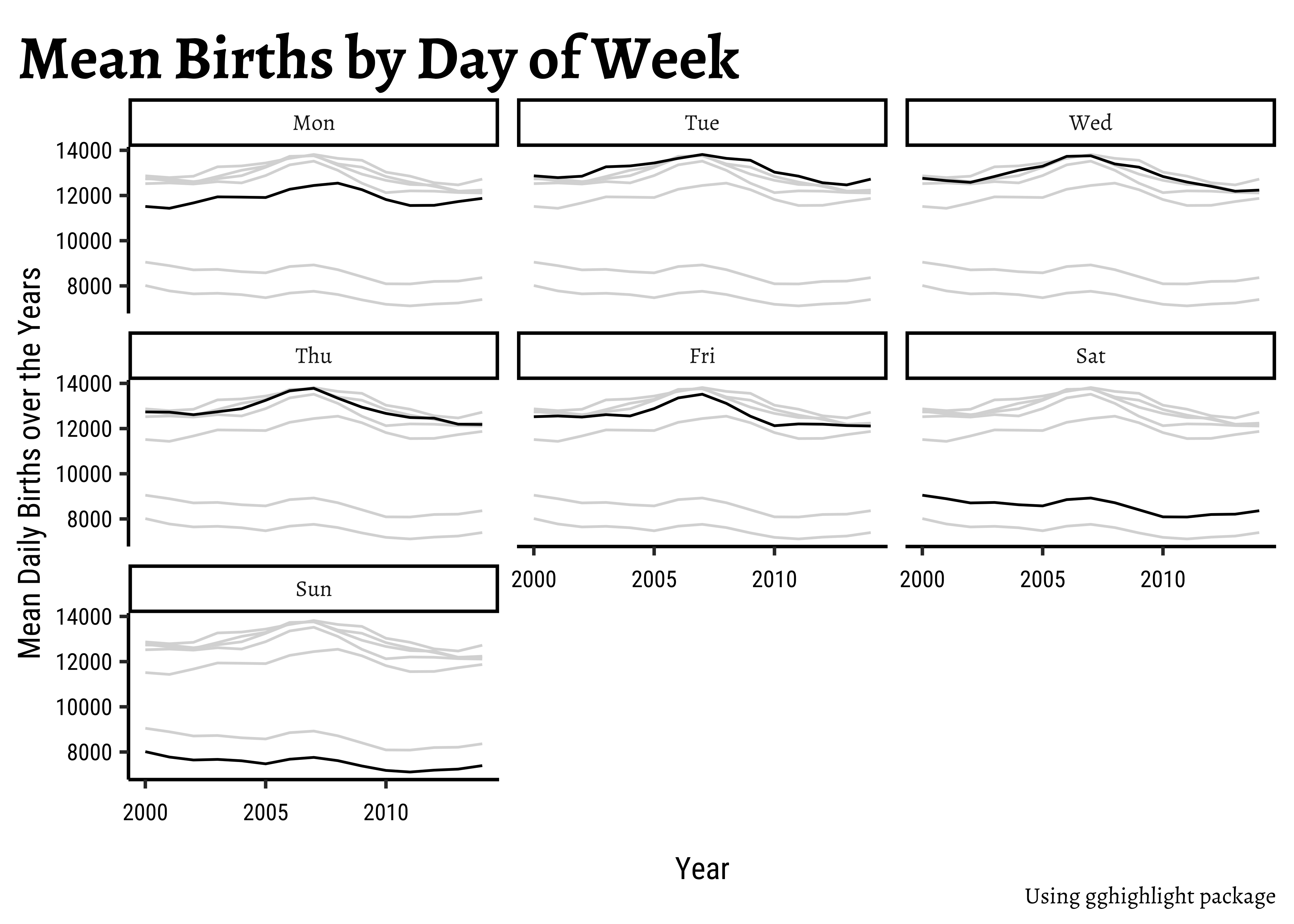
Why are fewer babies born on weekends?
Looks like an interesting story here…there are significantly fewer births on average on Sat and Sun, over the years! Why? Should we watch Grey’s Anatomy ?
And more births in September? That should be a no-brainer!! 😀
Important
Note that this is still using just tibble data, without converting it into a time series format. So far we are simply treating the year/month/day variables are simple variables and using dplyr to group and summarize. We have not created an explicit time or date variable.
Plotting tibble time-series
Now, we can convert the time-oriented columns in this dataset into a single date variable, giving us a proper tibble time-series:
births_tibble_timeseries <-
births_2000_2014 %>%
mutate(date = lubridate::make_date(year, month, date_of_month)) %>%
## Drop off the individual columns ( year, month, day_of_month)
select(date, births)
births_tibble_timeseriesdate <date> | births <dbl> | |||
|---|---|---|---|---|
| 2000-01-01 | 9083 | |||
| 2000-01-02 | 8006 | |||
| 2000-01-03 | 11363 | |||
| 2000-01-04 | 13032 | |||
| 2000-01-05 | 12558 | |||
| 2000-01-06 | 12466 | |||
| 2000-01-07 | 12516 | |||
| 2000-01-08 | 8934 | |||
| 2000-01-09 | 7949 | |||
| 2000-01-10 | 11668 |
Note that we have a proper date formatted column, as desired. This is a single time series, but if we had other Qualitative variables such as say city, we could easily have had multiple series here. We can plot this with ggformula/ggplot as we have done before, and with now with timetk:
## Set the theme
theme_set(new = theme_custom())
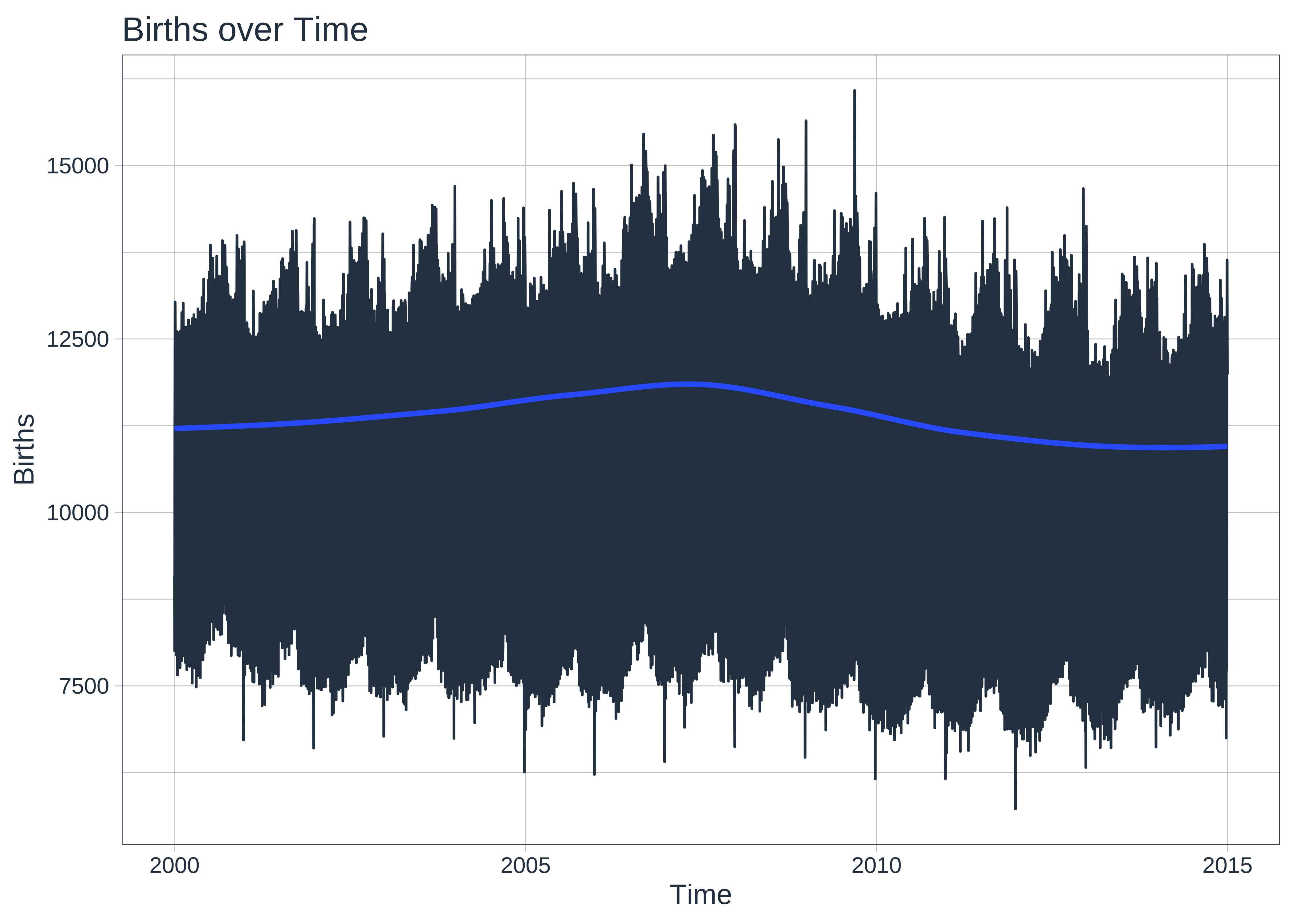
births_tibble_timeseries %>%
timetk::plot_time_series(
.date_var = date,
.value = births,
.interactive = FALSE,
.title = "Births over Time",
.x_lab = "Time",
.y_lab = "Births"
)
tsibble data
Finally, we have tsibble (“time series tibble”) format data, which contains three main components:
- an
indexvariable that defines time; - a set of
keyvariables, usually categorical, that define sets of observations, over time. This allows for each combination of the categorical variables to define a separate time series. - a set of quantitative variables, that represent the quantities that vary with time (i.e
index)
Here is Robert Hyndman’s video introducing tsibbles:
The package tsibbledata contains several ready made tsibble format data. Run data(package = "tsibbledata") in your Console to find out about these.
Let us try PBS, which is a dataset containing Monthly Medicare prescription data in Australia.
data(PBS, package = "tsibbledata")
PBSMonth <mth> | Concession <chr> | Type <chr> | ATC1 <chr> | ATC1_desc <chr> | ATC2 <chr> | ATC2_desc <chr> | Scripts <dbl> | Cost <dbl> |
|---|---|---|---|---|---|---|---|---|
| 1991 Jul | Concessional | Co-payments | A | Alimentary tract and metabolism | A01 | STOMATOLOGICAL PREPARATIONS | 18228 | 67877.00 |
| 1991 Aug | Concessional | Co-payments | A | Alimentary tract and metabolism | A01 | STOMATOLOGICAL PREPARATIONS | 15327 | 57011.00 |
| 1991 Sep | Concessional | Co-payments | A | Alimentary tract and metabolism | A01 | STOMATOLOGICAL PREPARATIONS | 14775 | 55020.00 |
| 1991 Oct | Concessional | Co-payments | A | Alimentary tract and metabolism | A01 | STOMATOLOGICAL PREPARATIONS | 15380 | 57222.00 |
| 1991 Nov | Concessional | Co-payments | A | Alimentary tract and metabolism | A01 | STOMATOLOGICAL PREPARATIONS | 14371 | 52120.00 |
| 1991 Dec | Concessional | Co-payments | A | Alimentary tract and metabolism | A01 | STOMATOLOGICAL PREPARATIONS | 15028 | 54299.00 |
| 1992 Jan | Concessional | Co-payments | A | Alimentary tract and metabolism | A01 | STOMATOLOGICAL PREPARATIONS | 11040 | 39753.00 |
| 1992 Feb | Concessional | Co-payments | A | Alimentary tract and metabolism | A01 | STOMATOLOGICAL PREPARATIONS | 15165 | 54405.00 |
| 1992 Mar | Concessional | Co-payments | A | Alimentary tract and metabolism | A01 | STOMATOLOGICAL PREPARATIONS | 16898 | 61108.00 |
| 1992 Apr | Concessional | Co-payments | A | Alimentary tract and metabolism | A01 | STOMATOLOGICAL PREPARATIONS | 18141 | 65356.00 |
glimpse(PBS)Rows: 67,596
Columns: 9
Key: Concession, Type, ATC1, ATC2 [336]
$ Month <mth> 1991 Jul, 1991 Aug, 1991 Sep, 1991 Oct, 1991 Nov, 1991 Dec,…
$ Concession <chr> "Concessional", "Concessional", "Concessional", "Concession…
$ Type <chr> "Co-payments", "Co-payments", "Co-payments", "Co-payments",…
$ ATC1 <chr> "A", "A", "A", "A", "A", "A", "A", "A", "A", "A", "A", "A",…
$ ATC1_desc <chr> "Alimentary tract and metabolism", "Alimentary tract and me…
$ ATC2 <chr> "A01", "A01", "A01", "A01", "A01", "A01", "A01", "A01", "A0…
$ ATC2_desc <chr> "STOMATOLOGICAL PREPARATIONS", "STOMATOLOGICAL PREPARATIONS…
$ Scripts <dbl> 18228, 15327, 14775, 15380, 14371, 15028, 11040, 15165, 168…
$ Cost <dbl> 67877.00, 57011.00, 55020.00, 57222.00, 52120.00, 54299.00,…Data Dictionary
Note
Data Description: This is a large-ish dataset.Run PBS in your console)
- 67K observations
- 336 combinations of
keyvariables (Concession,Type,ATC1,ATC2) which are categorical, as foreseen. - Data appears to be monthly, as indicated by the
1M. - the time index variable is called
Month, formatted asyearmonth, a new type of variable introduced in thetsibblepackage.
Note that there are multiple Quantitative variables (Scripts,Cost), each sliced into 336 time-series, a feature which is not supported in the ts format, but is supported in a tsibble. The Qualitative Variables are described below. (Type help("PBS") in your Console.)
The data is dis-aggregated/grouped using four keys:
- Concession: Concessional scripts are given to pensioners, unemployed, dependents, and other card holders
- Type: Co-payments are made until an individual’s script expenditure hits a threshold ($290.00 for concession, $1141.80 otherwise). Safety net subsidies are provided to individuals exceeding this amount.
- ATC1: Anatomical Therapeutic Chemical index (level 1). 15 types
- ATC2: Anatomical Therapeutic Chemical index (level 2). 84 types, nested inside ATC1.
Let us simply plot Cost over time:
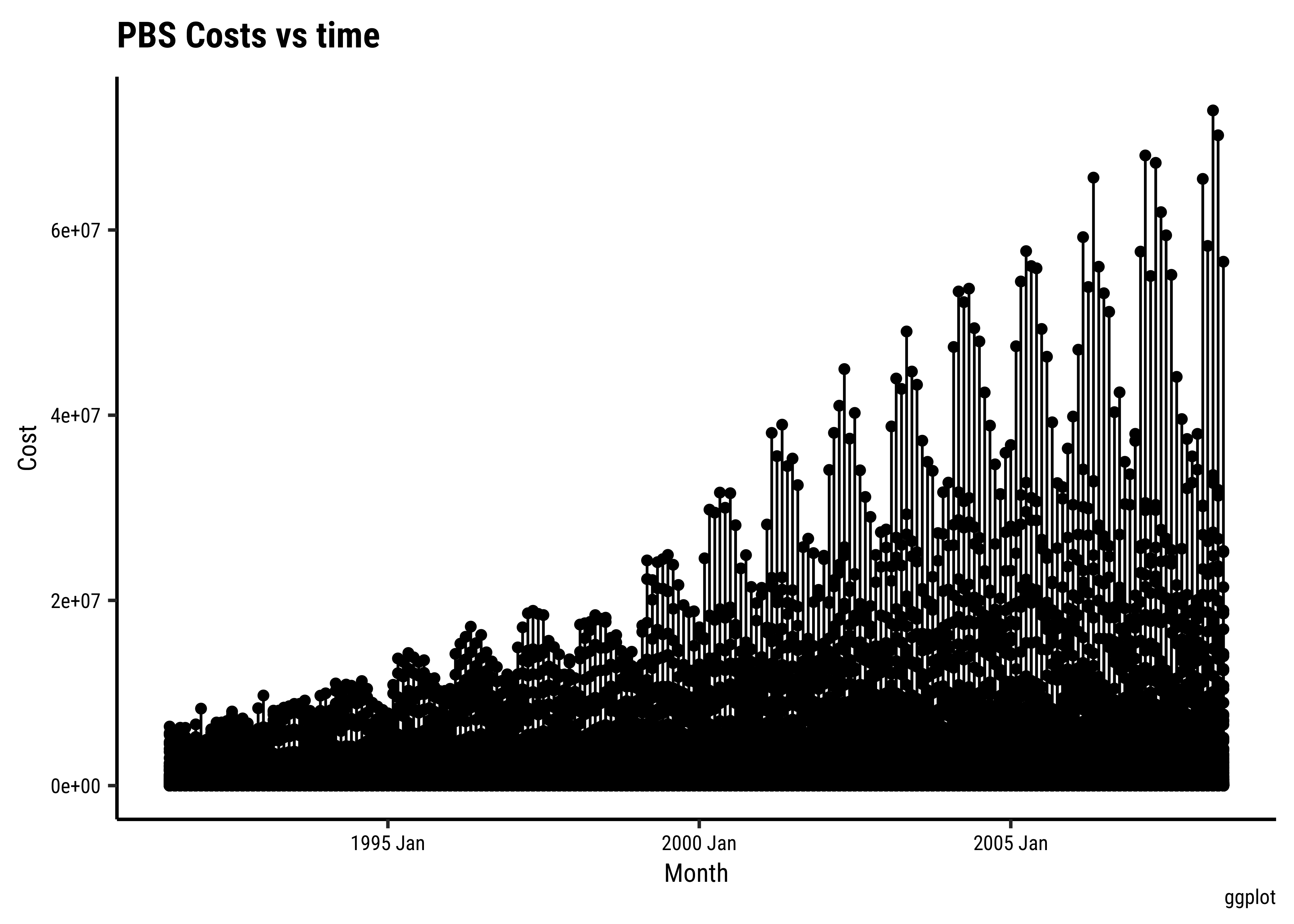
## Set the theme
theme_set(new = theme_custom())
PBS %>%
timetk::plot_time_series(
.date_var = Month, .value = Cost,
.interactive = FALSE,
.smooth = FALSE
)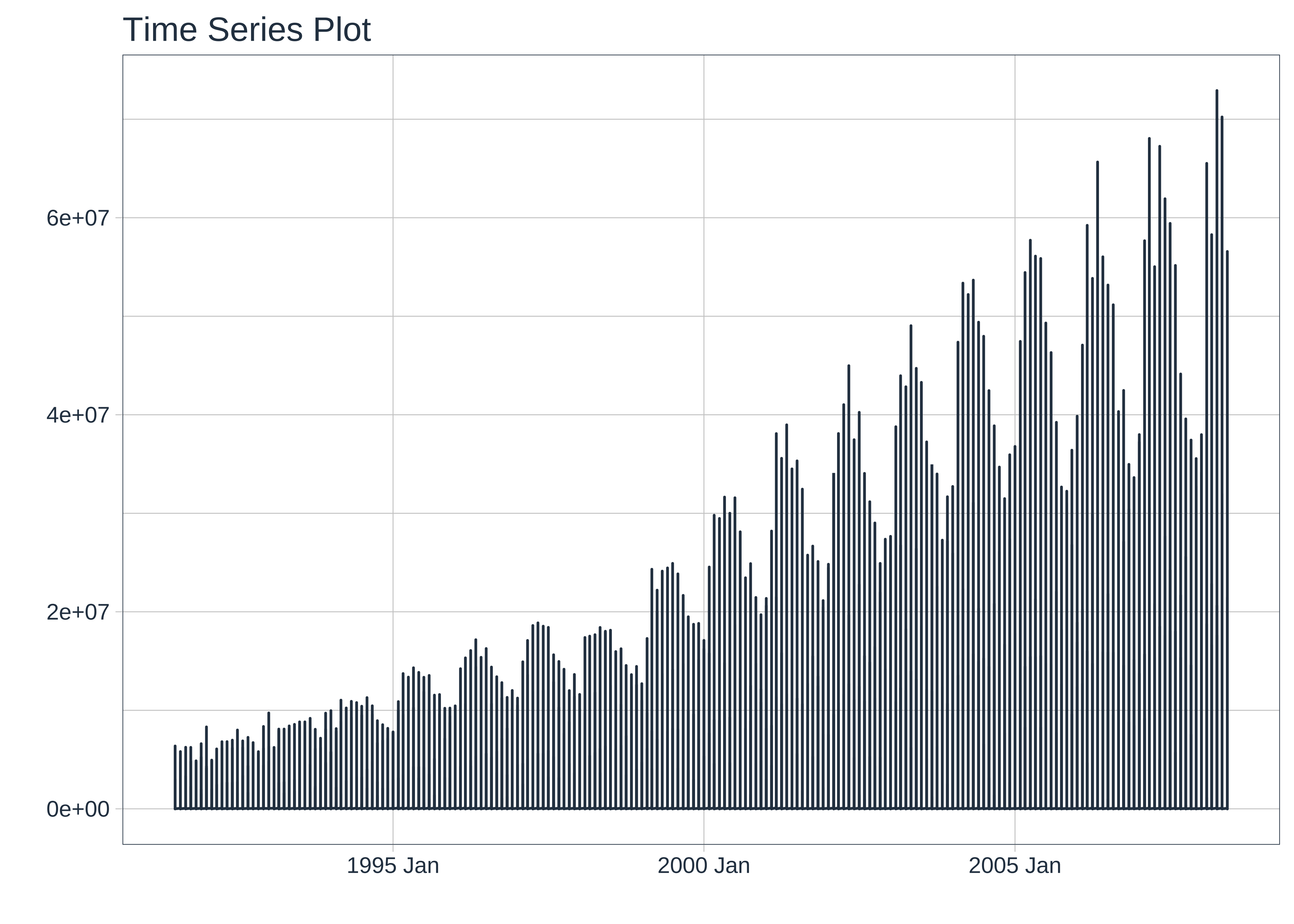
This basic plot is quite messy. Other than an overall rising trend and more vigorous variations pointing to a multiplicative process, we cannot say more. There is simply too much happening here and it is now time (sic!) for us to look at summaries of the data using dplyr-like verbs.
We will do that in the Section 1.
How about a heatmap? We can cook up a categorical variable based on the number of births (low, fine, high) and use that to create a heatmap:
## Set the theme
theme_set(new = theme_custom())
births_2000_2014 %>%
mutate(birthrate = case_when(
births >= 10000 ~ "high",
births <= 8000 ~ "low",
TRUE ~ "fine"
)) %>%
mutate(birthrate = base::factor(birthrate,
labels = c("high", "fine", "low"),
ordered = TRUE
)) %>%
gf_tile(
data = .,
year ~ month,
fill = ~birthrate,
color = "black"
) %>%
gf_refine(scale_x_time(
breaks = 1:12,
labels = c(
"Jan", "Feb", "Mar", "Apr",
"May", "Jun", "Jul", "Aug",
"Sep", "Oct", "Nov", "Dec"
)
)) %>%
gf_refine(scale_fill_brewer(type = "qual", palette = "OrRd", direction = -1))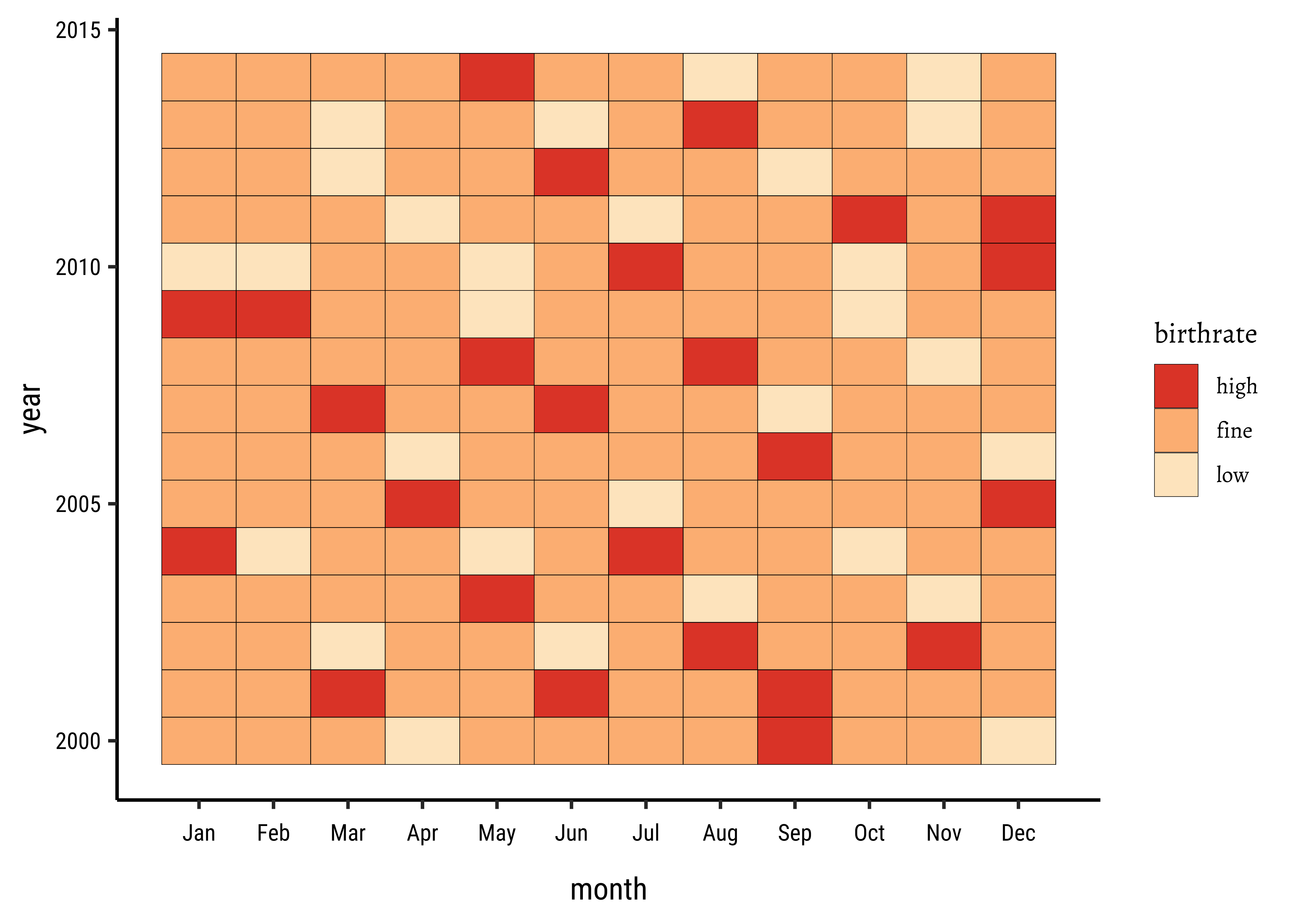
Note how both X and Y axis seem to be a time-oriented variable in a heatmap!
- Choose some of the datasets in the
tsdland in thetsibbledatapackages. (Install and load them first! ) Plot basic, filtered and model-based graphs for these and interpret.
- Many datasets show quantities varying over time. These are called time-series data.
- The X-axis in these cases becomes a
timeaxis. - Time-series data come in many different formats!
- The time-aspect in a dataset creates for two dimensions of data-aggregation and averaging: One based on factors as before, and a new one based on intervals of time
- We are interested in decomposing a time-series into averages, trends, seasonal components, and random variations
- We are also interested in modelling a time-series as additive or multiplicative time-series, using techniques such as Holt-Winters, and ARIMA
- And of course we are interested in forecasting!
We have seen a good few data formats for time series, and how to work with them and plot them.
In the Tutorial Section 1, we will explore:
- wrangling with Time series to produce grouped and filtered aggregates/summaries and plots with these
- how to decompose time series into periodic and aperiodic components, which can be used to make business decisions.
- Producing Interactive Plots for Time Series
- modelling and forecasting of time series.
- Robert Hyndman, Forecasting: Principles and Practice (Third Edition).available online
-
Time Series Analysis at Our Coding Club
-
The Nuclear Threat—The Shadow Peace, part 1
-
11 Ways to Visualize Changes Over Time – A Guide
-
What is seasonal adjustment and why is it used?
-
The start-at-zero rule
Dancho, Matt, and Davis Vaughan. 2023. timetk: A Tool Kit for Working with Time Series. https://doi.org/10.32614/CRAN.package.timetk.
Hyndman, Rob. 2024. Fpp3: Data for “Forecasting: Principles and Practice” (3rd Edition). https://doi.org/10.32614/CRAN.package.fpp3.
Hyndman, Rob, and Yangzhuoran Yang. 2025. tsdl: Time Series Data Library. https://github.com/FinYang/tsdl.
Krispin, Rami. 2023. TSstudio: Functions for Time Series Analysis and Forecasting. https://doi.org/10.32614/CRAN.package.TSstudio.
O’Hara-Wild, Mitchell, Rob Hyndman, Earo Wang, and Rakshitha Godahewa. 2022. tsibbledata: Diverse Datasets for “tsibble”. https://doi.org/10.32614/CRAN.package.tsibbledata.
Wang, Earo, Dianne Cook, and Rob J Hyndman. 2020. “A New Tidy Data Structure to Support Exploration and Modeling of Temporal Data.” Journal of Computational and Graphical Statistics 29 (3): 466–78. https://doi.org/10.1080/10618600.2019.1695624.
Yutani, Hiroaki. 2025. gghighlight: Highlight Lines and Points in “ggplot2”. https://doi.org/10.32614/CRAN.package.gghighlight.
Footnotes
https://www.gapminder.org/data/↩︎
Citation
BibTeX citation:
@online{2022,
author = {},
title = {\textless Iconify-Icon Icon=“fluent-Mdl2:hour-Glass”
Width=“1.2em”
Height=“1.2em”\textgreater\textless/Iconify-Icon\textgreater{}
{Time}},
date = {2022-12-15},
url = {https://av-quarto.netlify.app/content/courses/Analytics/Descriptive/Modules/50-Time/},
langid = {en},
abstract = {Events, Trends, Seasons, and Changes over Time}
}
For attribution, please cite this work as:
“<Iconify-Icon Icon=‘fluent-Mdl2:hour-Glass’
Width=‘1.2em’
Height=‘1.2em’></Iconify-Icon> Time.” 2022.
December 15, 2022. https://av-quarto.netlify.app/content/courses/Analytics/Descriptive/Modules/50-Time/.